📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Language Model Alignment
Simulation Environments for LLMs
AlpacaFarm is a simulation sandbox that enables low-cost research on learning from human feedback by replacing human annotators with API-based LLMs that closely mimic human preference rankings.
Core Problem
Developing instruction-following models via RLHF is difficult because data collection is expensive, evaluation is untrustworthy, and there are no public reference implementations of training methods.
Why it matters:
- The specific training methods (like PPO) used by vendors like OpenAI are unpublished, making the process poorly understood
- High costs of human annotation prevent academic researchers from replicating or improving upon state-of-the-art alignment techniques
- The lack of a standardized sandbox means researchers cannot rapidly iterate on new alignment algorithms before deploying them to real users
Concrete Example:
When researchers try to replicate ChatGPT's instruction following, they often lack the budget to collect 10k+ human preference pairs. Without this data, they cannot verify if PPO actually outperforms supervised fine-tuning (SFT) or if simpler methods like Best-of-N would suffice, leading to blind adoption of complex algorithms.
Key Novelty
Simulated sandbox for RLHF research (AlpacaFarm)
- Replaces human labelers with 'simulated annotators' (prompted API LLMs) that mimic human inter-annotator disagreement and noise
- Provides a validated automated evaluation suite that correlates highly with human rankings on real-world instruction sets
- Offers clean reference implementations of major alignment algorithms (PPO, Expert Iteration, Quark) tuned to work in this specific environment
Architecture
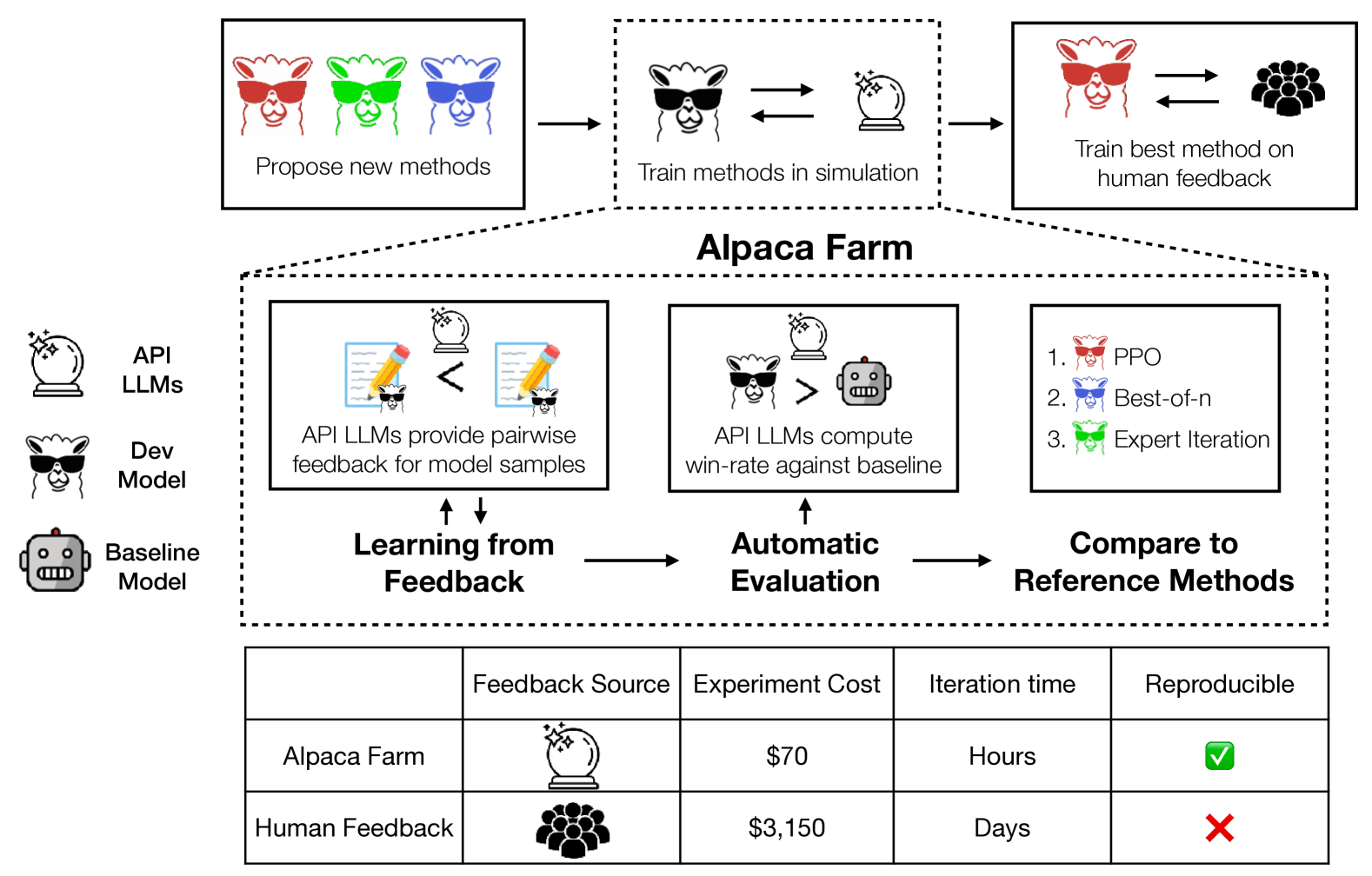
Overview of the AlpacaFarm workflow.
Evaluation Highlights
- Simulated annotators are 50x cheaper than human crowdworkers while maintaining high agreement with human preferences
- Method rankings in the simulator correlate strongly (Spearman 0.98) with method rankings obtained from training on actual human data
- Reference PPO implementation improves win-rate against Davinci003 from 44% (SFT baseline) to 55% using simulated feedback
Breakthrough Assessment
9/10
Critically enables academic research into RLHF by removing the prohibitive cost barrier of human annotation. The high correlation with real human data validates it as a trustworthy proxy.
