📝 Paper Summary
Memory recall
Modularized RAG pipeline
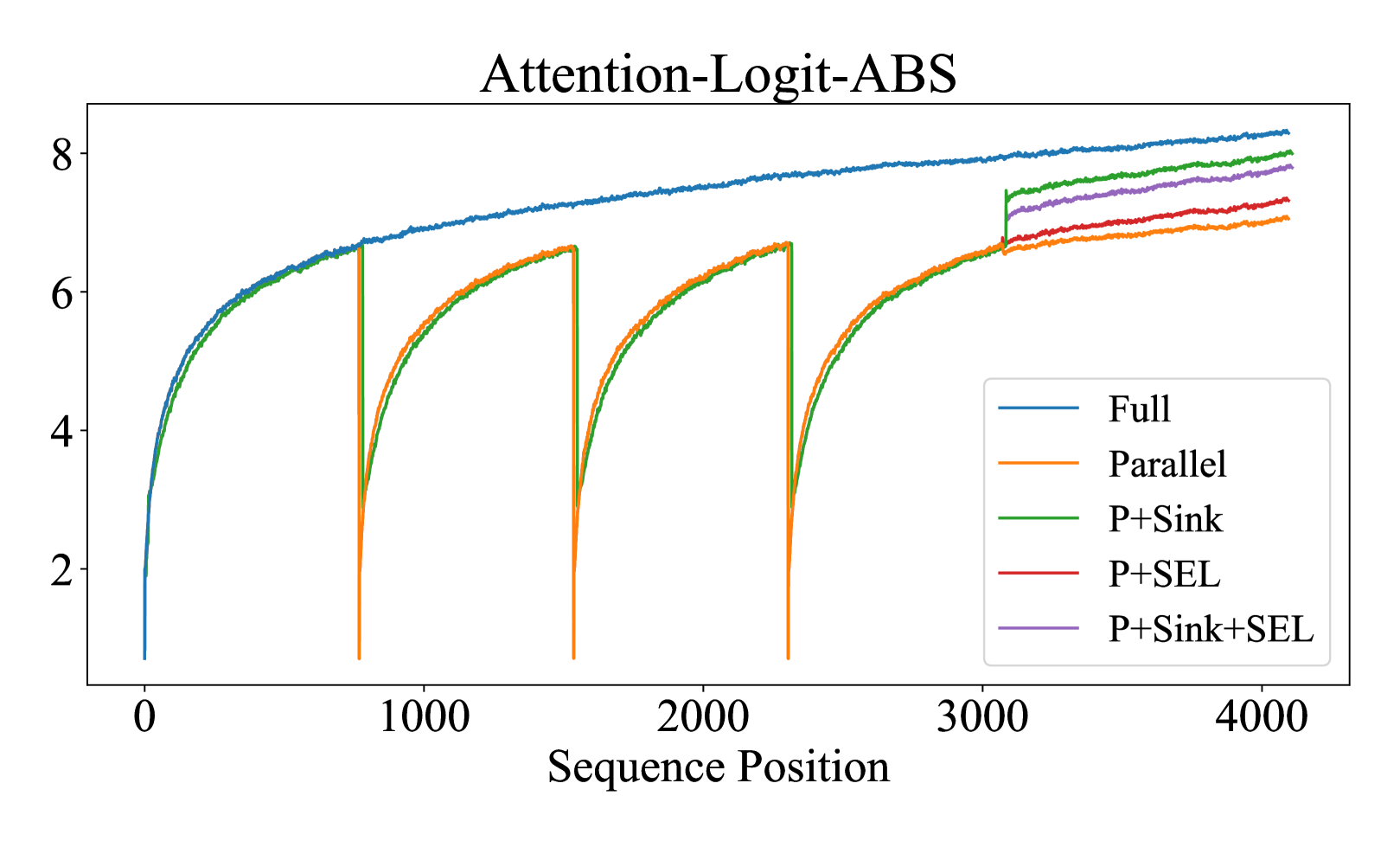
The paper identifies irregularly high attention entropy as the cause of performance degradation in parallel context encoding and proposes using shared attention sinks and selective attention to mitigate this.
Core Problem
Naively applying parallel context encoding (splitting context into independent chunks) to full-attention-trained LLMs causes severe performance drops because the models encounter unfamiliar attention patterns.
Why it matters:
- Full self-attention scales quadratically with sequence length, making long-context processing inefficient and costly.
- Many applications like RAG and In-Context Learning have natural parallel structures (documents, examples) that could be processed more efficiently if parallel encoding worked reliably.
- Existing solutions often require computationally expensive fine-tuning or are limited to specific tasks.
Concrete Example:
In a synthetic recall task (finding a needle in a haystack), a model achieves near 100% accuracy with full attention but drops to near 0% when the context is split into tens of parallel sub-pieces.
Key Novelty
Entropy-Aware Parallel Context Encoding
- Identifies that parallel encoding causes 'attention entropy' (uncertainty) to spike because query tokens attend to multiple unconnected sub-contexts, a pattern unseen during training.
- Introduces 'Shared Attention Sinks': Prepending a common prefix to every parallel chunk to normalize hidden state magnitudes and absorb excess attention.
- Introduces 'Selective Attention': A hard filtering mechanism that forces the model to attend only to the top-K most relevant context chunks, artificially sharpening the attention distribution.
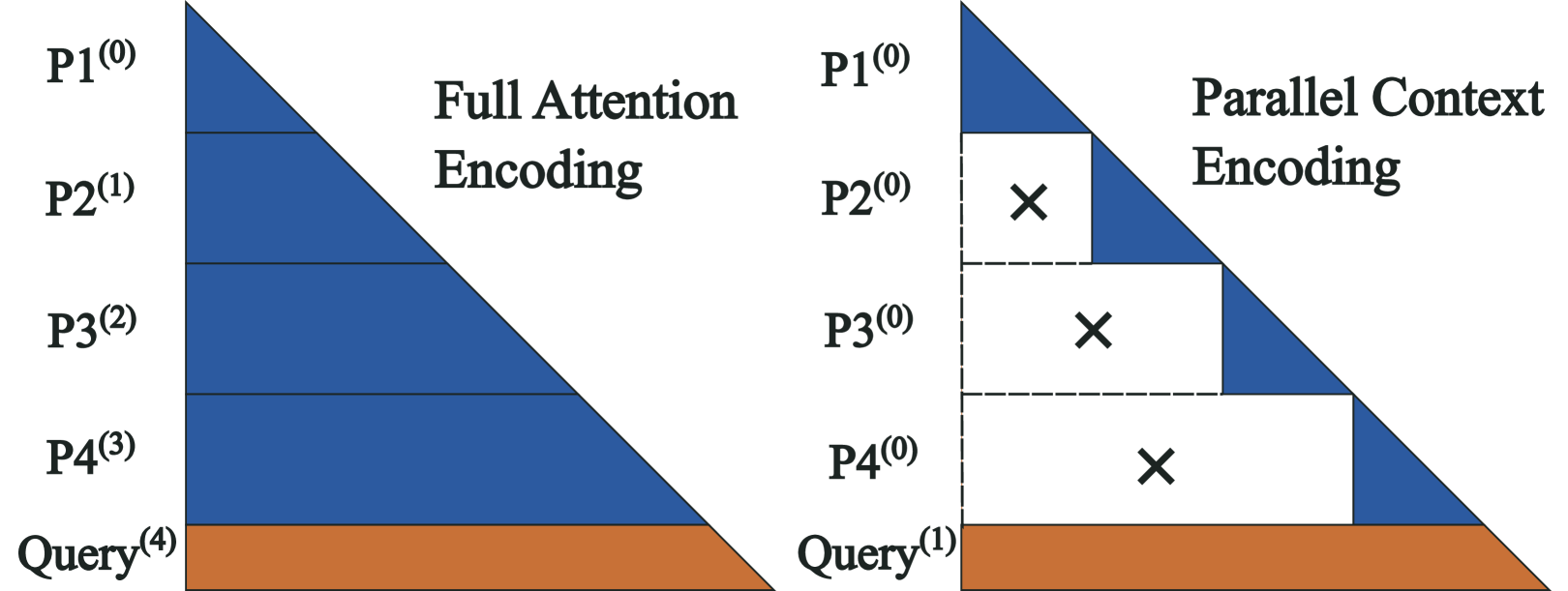
Architecture
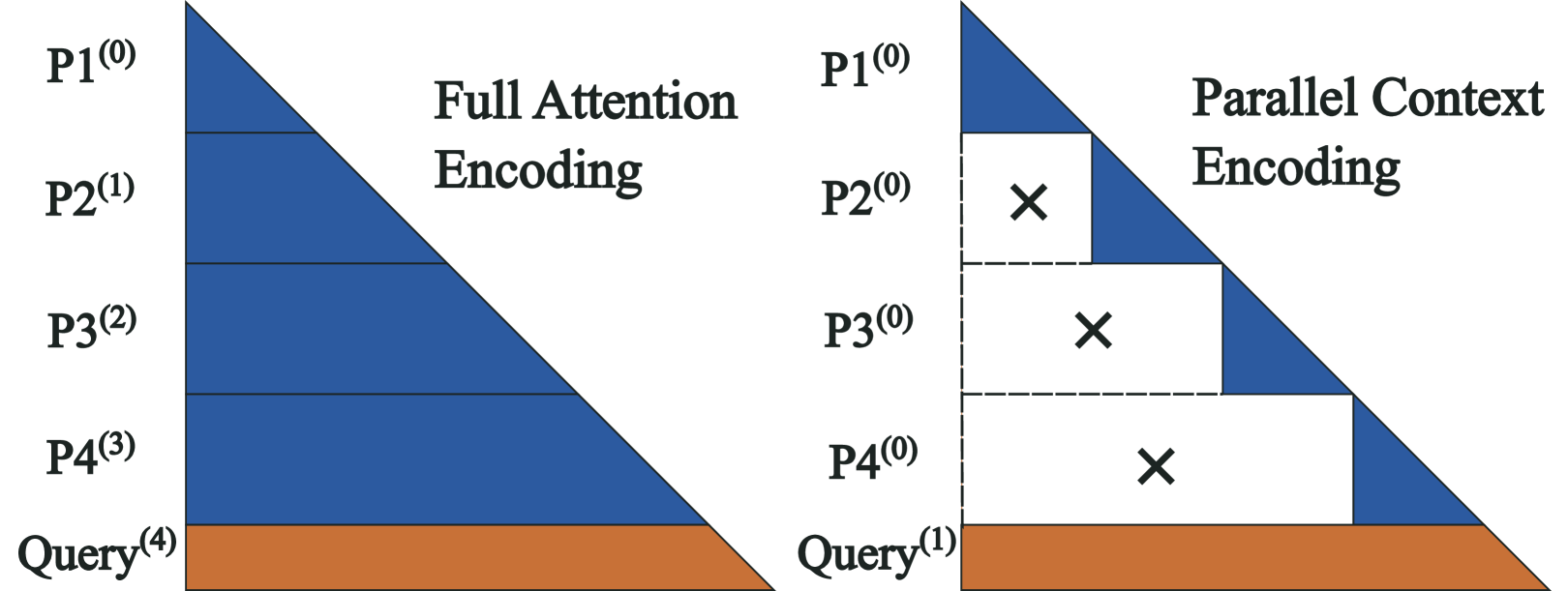
Comparison between Full Attention and Parallel Context Encoding patterns, and the resulting Attention Entropy.
Evaluation Highlights
- Synthetic recall accuracy improves from ~0% (naive parallel) to near 100% (with selective attention) on 8K context tasks using Llama-3.1-8B.
- Reduces attention entropy on PG19 language modeling tasks, bringing perplexity closer to full-attention baselines compared to naive parallel encoding.
- Demonstrates consistent improvements across RAG (Natural Questions, HotpotQA) and ICL (Banking77, TREC) benchmarks without any model fine-tuning.
Breakthrough Assessment
7/10
Provides a crucial diagnostic insight (attention entropy) for why parallel encoding fails and offers simple, inference-time solutions that recover performance without training.