📝 Paper Summary
Multi-Agent Reinforcement Learning (MARL)
Centralized Training with Centralized Execution (CTCE)
JointPPO solves the scalability issues of fully centralized multi-agent learning by decomposing the joint policy into an autoregressive sequence generation task optimized directly via PPO.
Core Problem
Centralized Training with Decentralized Execution (CTDE) limits agent coordination by restricting information sharing, while traditional Fully Centralized (CTCE) methods fail to scale because the joint action space grows exponentially with the number of agents.
Why it matters:
- CTDE methods force agents to make independent decisions during execution, ignoring potentially available shared information.
- Existing centralized methods often require complex value factorization or restrictive assumptions to handle large action spaces.
- Prior sequence-based methods (like MAT) use loss functions that may not strictly adhere to the Multi-Agent Advantage Decomposition Theorem, potentially biasing optimization.
Concrete Example:
In a scenario with 10 agents each having 5 actions, a traditional centralized controller faces a joint action space of 5^10 (~9.7 million), making direct optimization impossible. CTDE avoids this but prevents agents from coordinating via real-time communication. JointPPO converts this into a sequence of 10 individual choices conditioned on previous ones.
Key Novelty
Autoregressive Joint Policy Optimization (JointPPO)
- Decomposes the complex joint policy distribution into a chain of conditional probabilities, treating multi-agent decision-making as a sequence generation task.
- Applying standard PPO updates directly to the factorized joint policy rather than individual policies, effectively simplifying MARL into a single-agent RL problem.
- Utilizes a Transformer architecture to process all agent observations and generate actions sequentially, scaling linearly rather than exponentially.
Architecture
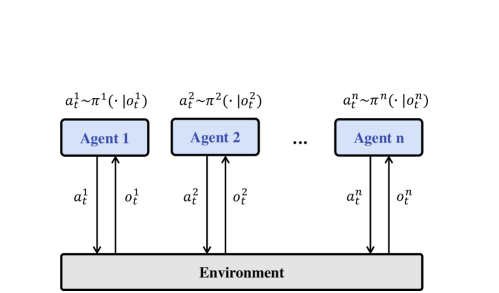
Comparison of MARL paradigms: (a) Independent, (b) Fully Centralized (CTCE), and (c) CTDE. JointPPO falls under (b) but uses sequence generation.
Evaluation Highlights
- Achieves nearly 100% win rates across all tested StarCraft Multi-Agent Challenge (SMAC) maps, including both homogeneous and heterogeneous scenarios.
- Demonstrates superior data efficiency compared to strong baselines (MAPPO, HAPPO, MAT) according to the authors' claims.
- Shows robustness to the specific order of action generation (Decision Order Designation) in ablation studies.
Breakthrough Assessment
7/10
Offers a clean, theoretically grounded simplification of MARL to single-agent RL via sequence modeling. While the architecture borrows from MAT, the direct PPO application to joint policy without value decomposition is a significant refinement.