📝 Paper Summary
Humanoid Robot Locomotion
Sim-to-Real Transfer
Distillation-PPO (D-PPO) improves humanoid robot walking by training a student policy with a hybrid loss that combines imitation of a privileged teacher (DAgger) with continued reinforcement learning (PPO) to handle noise and surpass teacher limits.
Core Problem
Existing two-stage locomotion methods (imitation learning) restrict the student to the teacher's performance ceiling and handle sensor noise poorly, while end-to-end methods are unstable and difficult to train from scratch.
Why it matters:
- Humanoid robots are inherently unstable and require precise control to navigate complex terrains (stairs, slopes) without falling.
- Teacher policies trained with perfect simulation data often fail to guide students correctly when real-world sensors (depth cameras/LiDAR) introduce noise and occlusion.
- Pure imitation prevents the student policy from adapting or improving beyond the teacher, contradicting the core goal of reinforcement learning to find optimal behaviors.
Concrete Example:
A teacher policy uses perfect terrain data to step exactly on a safe spot. A student policy relying on noisy real-world depth data sees a slightly different terrain geometry. If the student strictly imitates the teacher's foot placement (DAgger), it might step on a dangerous edge. D-PPO allows the student to adjust its action using RL rewards to find a safe step despite the noisy input.
Key Novelty
Distillation-PPO (D-PPO) Hybrid Loss
- Combines supervised imitation loss (DAgger) with reinforcement learning loss (PPO) during the student training stage.
- Uses the teacher's actions as a regularization signal to guide convergence, while allowing the PPO component to explore and optimize rewards, enabling the student to adapt to partial observability and potentially outperform the teacher.
Architecture
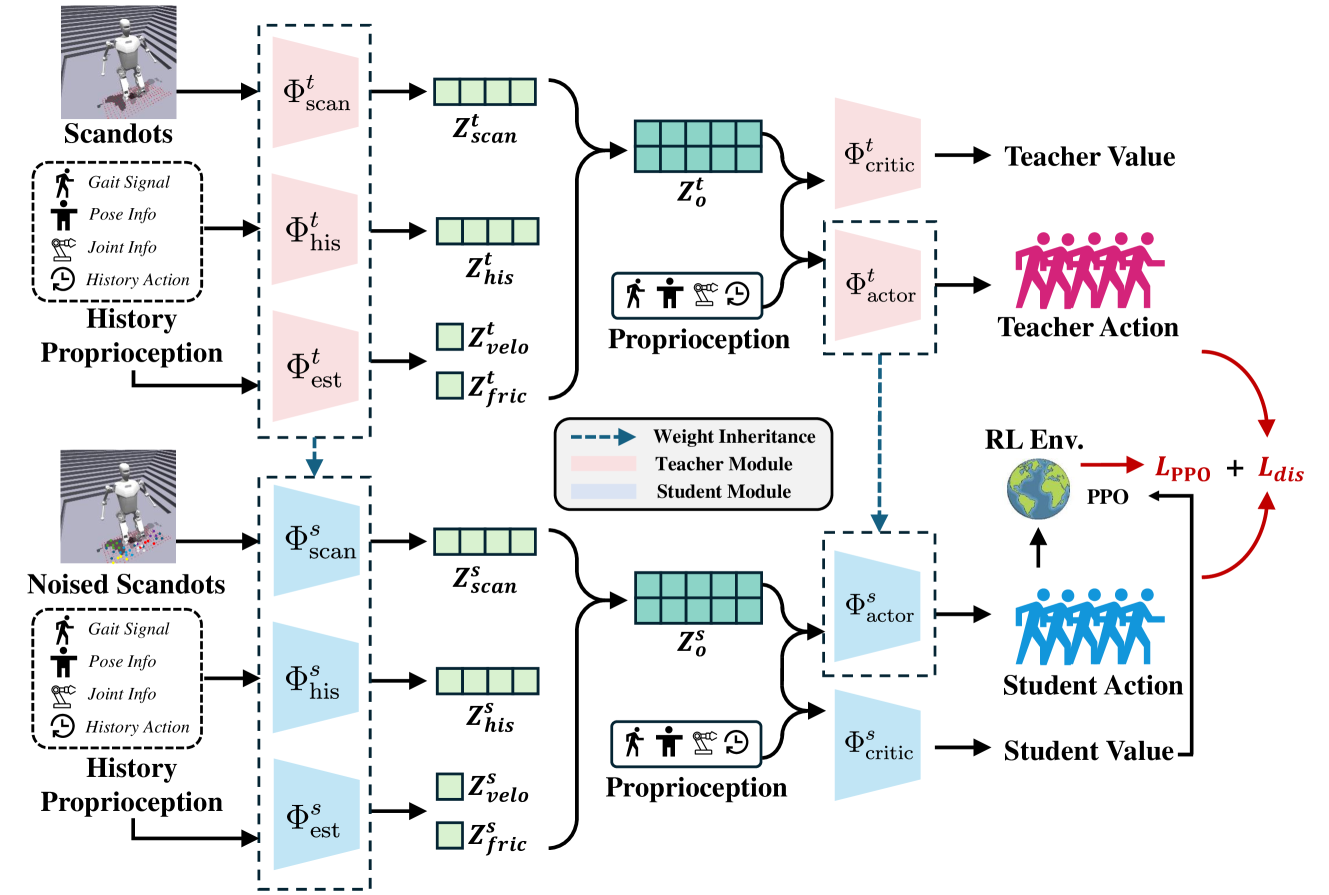
Schematic diagram of the D-PPO training framework, illustrating the two-stage process.
Evaluation Highlights
- Demonstrates successful sim-to-real transfer on the 'Tien Kung' humanoid robot across various terrains (qualitative result).
- Achieves higher training efficiency and stability in simulation compared to end-to-end methods (qualitative result).
- Exhibits robustness to sensor noise by continuing to learn in the POMDP setting rather than just mimicking the MDP teacher (qualitative result).
Breakthrough Assessment
5/10
A solid incremental improvement combining two standard techniques (DAgger and PPO) to address a specific limitation in robotic sim-to-real transfer. While effective, the components are well-known.
