📝 Paper Summary
Continuous Control
Robotic Manipulation
Action Discretization
CQN enables stable, sample-efficient value-based reinforcement learning in continuous action spaces by iteratively zooming into the action space through multi-level discretization.
Core Problem
Applying RL to real-world robotics is difficult because actor-critic methods are unstable and sample-inefficient, while value-based methods struggle with the trade-off between action precision and the curse of dimensionality in continuous spaces.
Why it matters:
- Real-world robots require sample efficiency due to hardware wear and reset costs, making data-hungry on-policy methods impractical
- Standard discretization limits precision: fine grids explode the action space (hard to learn), while coarse grids lack the dexterity needed for manipulation
Concrete Example:
In a robotic manipulation task requiring high precision (e.g., inserting a plug), a standard discrete agent with few bins misses the target, while one with many bins takes too long to explore and learn. CQN starts coarse to find the general area, then zooms in for precision.
Key Novelty
Coarse-to-fine Q-Network (CQN)
- Iterative Zooming: instead of outputting one high-precision action, the agent discretizes the space into a few bins, selects the best one, and then re-discretizes that specific interval at the next level
- Multi-level Critic: A single value-based network structure that takes the previous level's decisions as input to inform the next level's finer-grained choice
- Efficient Precision: Achieves high continuous control precision with very few bins per level (e.g., 3 bins) by chaining multiple levels, avoiding the exponential explosion of actions
Architecture
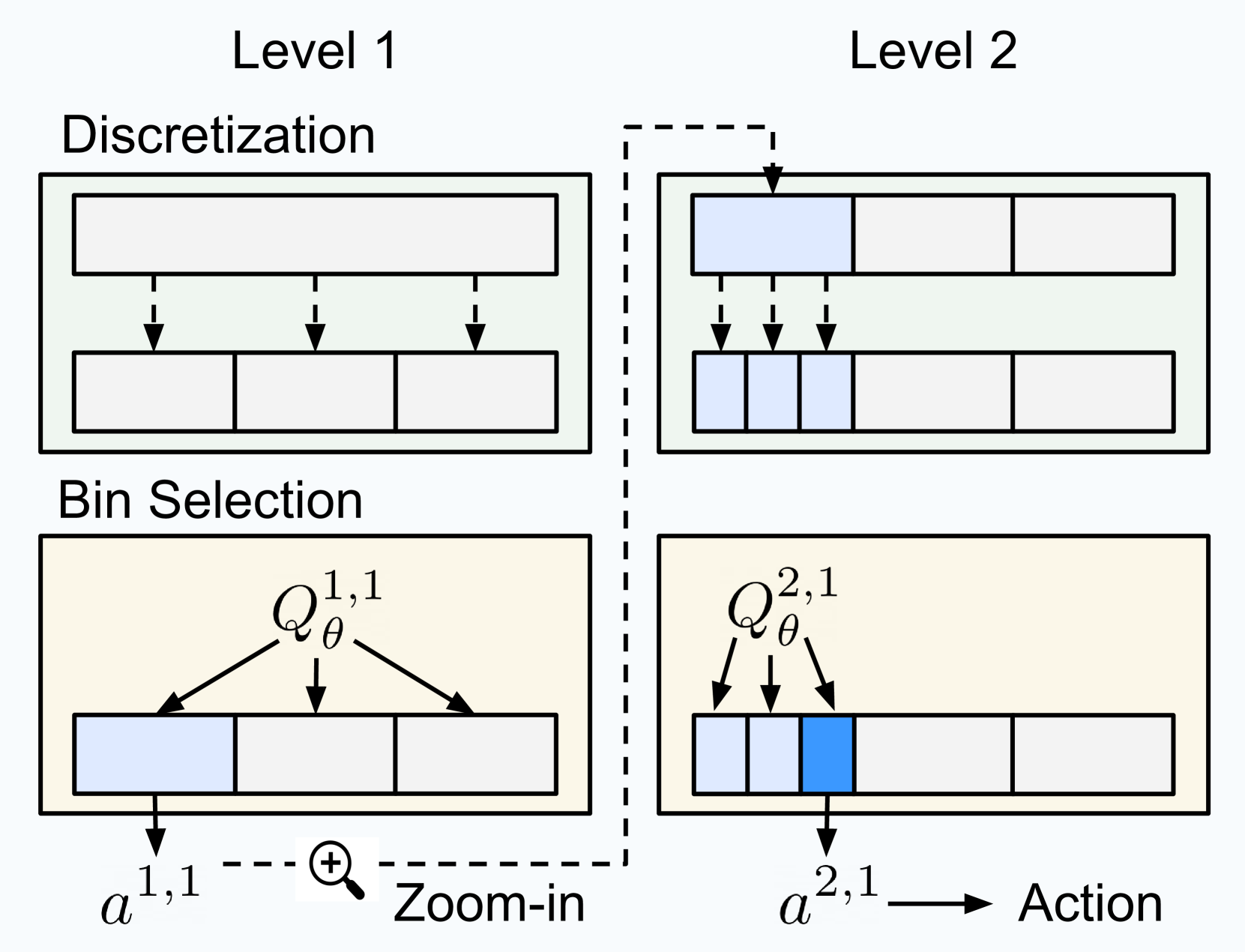
Overview of the Coarse-to-fine Reinforcement Learning (CRL) framework and CQN architecture.
Evaluation Highlights
- Outperforms RL and BC baselines on 20 sparsely-rewarded RLBench tasks using only 100 demonstrations and 100k online interactions
- Achieves competitive performance to state-of-the-art actor-critic baselines (DrQ-v2) on DeepMind Control Suite tasks
- Robustly solves real-world manipulation tasks (e.g., stacking blocks) within minutes of online training
Breakthrough Assessment
8/10
Significantly improves sample efficiency for precise continuous control by cleverly adapting value-based methods. The removal of the actor network simplifies the architecture while maintaining high precision.