📝 Paper Summary
Model-Based Reinforcement Learning
Privileged Information
Sim-to-Real Transfer
Robotic Manipulation
Scaffolder trains robots using extra sensors available only during training (like cameras or motion capture) to build better internal simulators, allowing the final robot to perform well with only basic sensors.
Core Problem
Robots often train with access to rich sensor data (privileged information) but must deploy with cheap, limited sensors; existing methods struggle to effectively transfer this rich training knowledge to the limited deployment policy.
Why it matters:
- Real-world robots often rely on cheap, robust sensors (e.g., RGB cameras) due to cost and durability, while training environments can support expensive instrumentation (e.g., motion capture).
- Current methods typically use privileged data only for reward calculation or value estimation, missing opportunities to improve the robot's understanding of world dynamics and exploration.
Concrete Example:
A robot arm must pick up a block using only touch sensors (blind). During training, a camera reveals the block's location. Standard RL ignores the camera for the policy, making learning slow or impossible because the robot cannot 'see' the block to learn the task initially.
Key Novelty
Scaffolded Model-Based Reinforcement Learning
- Trains a 'scaffolded' world model using privileged sensors (e.g., cameras) to accurately simulate the environment, rather than relying on a weak model built from limited target sensors.
- Uses this accurate simulator to train the limited target policy by translating rich simulator states into the limited observations the policy expects via a 'transdecoder'.
- Employes a privileged exploration policy that uses the extra sensors to collect better training data, guiding the blind target policy toward useful behaviors it couldn't find alone.
Architecture
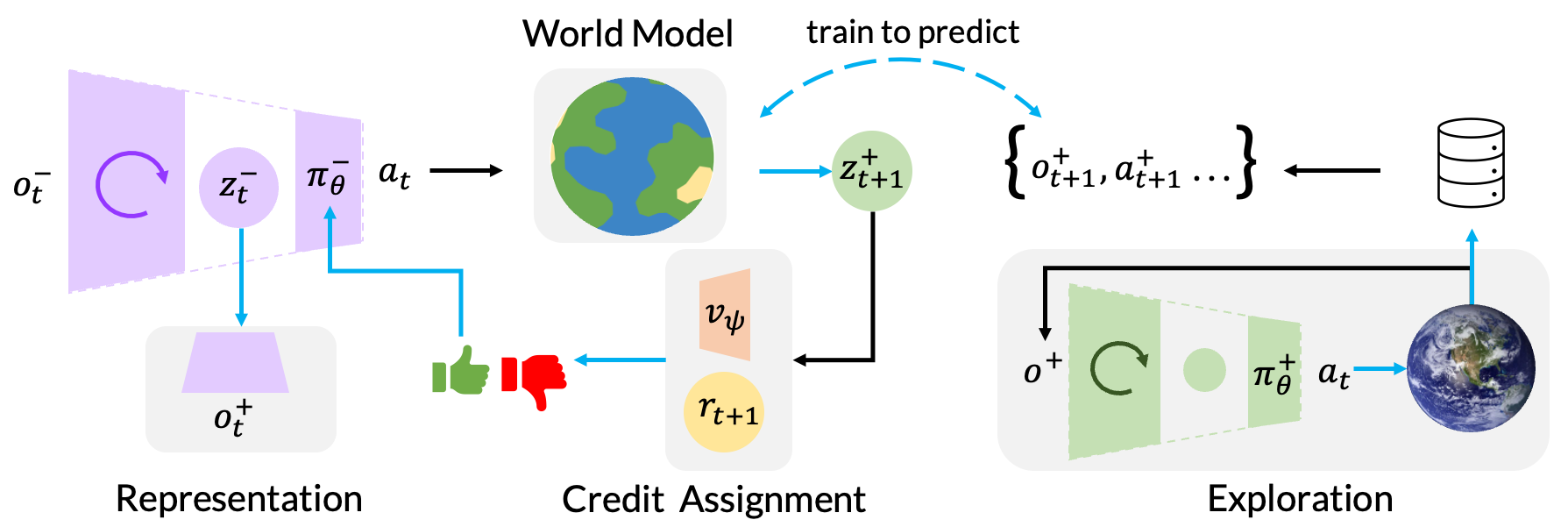
The training architecture of Scaffolder, contrasting the Target World Model (used for test-time encoding) with the Scaffolded World Model (used for training-time imagination).
Evaluation Highlights
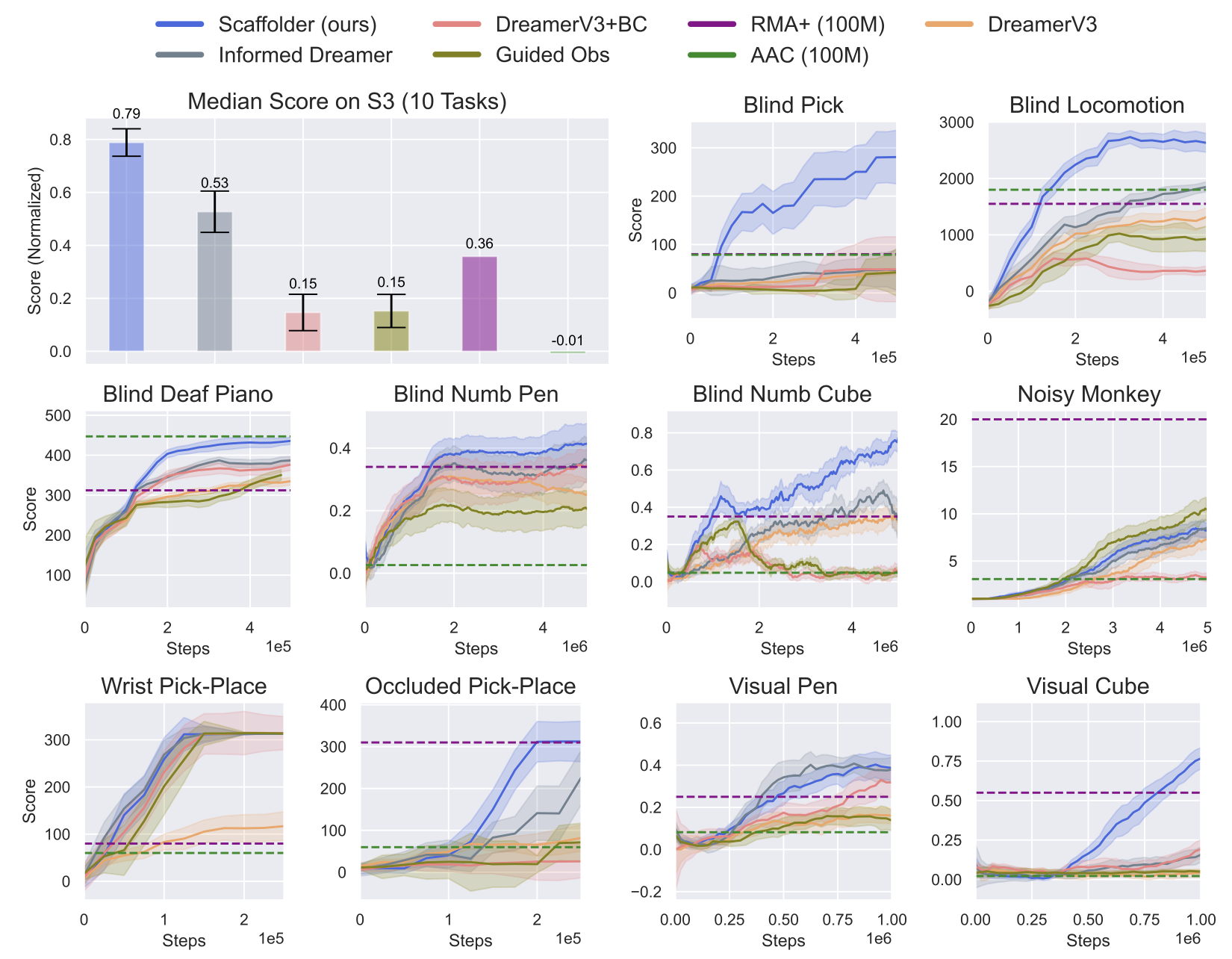
- Outperforms DreamerV3 baseline by +64% success rate on the 'Visual Occlusion' task where a robot must reach behind an obstacle.
- Achieves 85% success rate on 'PandaPick' using only touch sensors, matching the performance of a policy that has full access to camera data at test time.
- Surpasses prior state-of-the-art methods (privileged critics, distillation) across a new suite of 10 diverse robotic tasks, including dexterous manipulation and blind locomotion.
Breakthrough Assessment
8/10
Proposes a comprehensive framework for leveraging privileged information in MBRL, consistently outperforming baselines across diverse tasks. The 'S3' benchmark suite is also a valuable contribution.