📝 Paper Summary
In-Context Learning
Reinforcement Learning
Training a transformer to simply predict optimal actions from interaction histories enables it to act as an effective in-context RL algorithm that performs exploration and improves upon its training data.
Core Problem
Standard RL methods often require expensive retraining for new tasks, while existing offline RL methods struggle to improve beyond their datasets or handle online exploration naturally.
Why it matters:
- Real-world agents need to adapt to new environments instantly (few-shot) without parameter updates
- Current supervised transformers (like Decision Transformer) generally cannot outperform the behavior policy in their training data
- Posterior Sampling is a powerful theoretical RL algorithm but is computationally intractable to implement directly
Concrete Example:
In a linear bandit problem, a standard supervised model mimics the suboptimal algorithm used to generate the data. In contrast, DPT learns the underlying structure (linearity) and performs efficient exploration to find the optimal arm, achieving lower regret than the algorithm that generated its training data.
Key Novelty
Decision-Pretrained Transformer (DPT)
- Pretrains a transformer using supervised learning to predict the *optimal* action given a query state and a context of suboptimal interactions
- Demonstrates that this simple objective leads to emergent exploration and posterior sampling behavior at test time, without explicit exploration training
Architecture
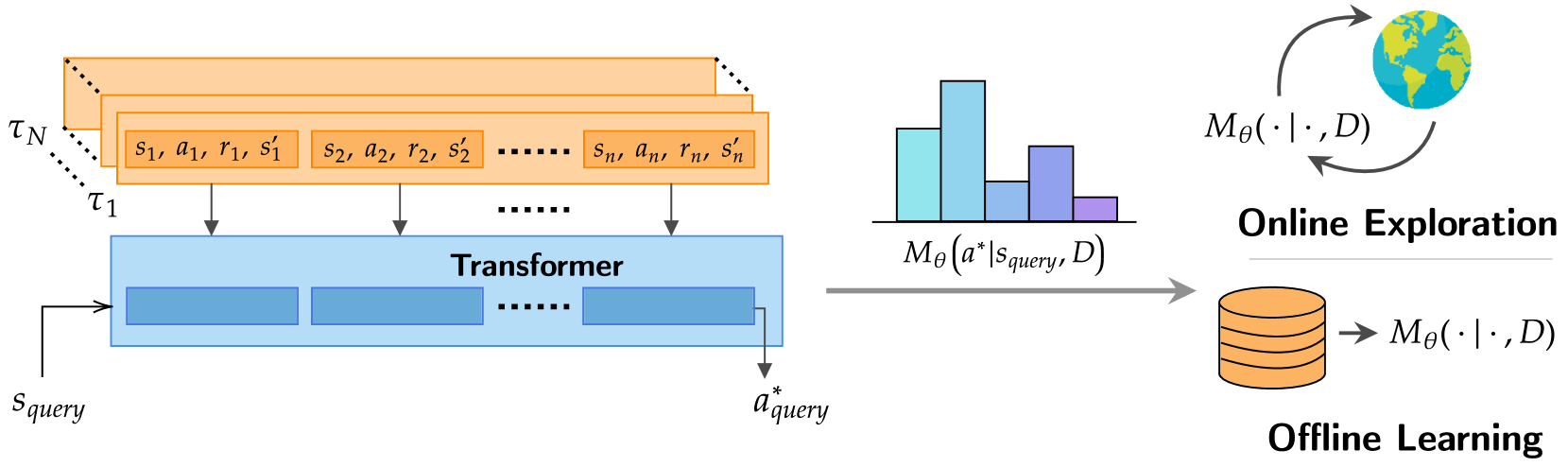
Overview of the Decision-Pretrained Transformer (DPT) framework. It shows the pretraining phase where the model learns to predict optimal actions from datasets, and the evaluation phase where it interacts with a new environment to collect data and refine its policy in-context.
Evaluation Highlights
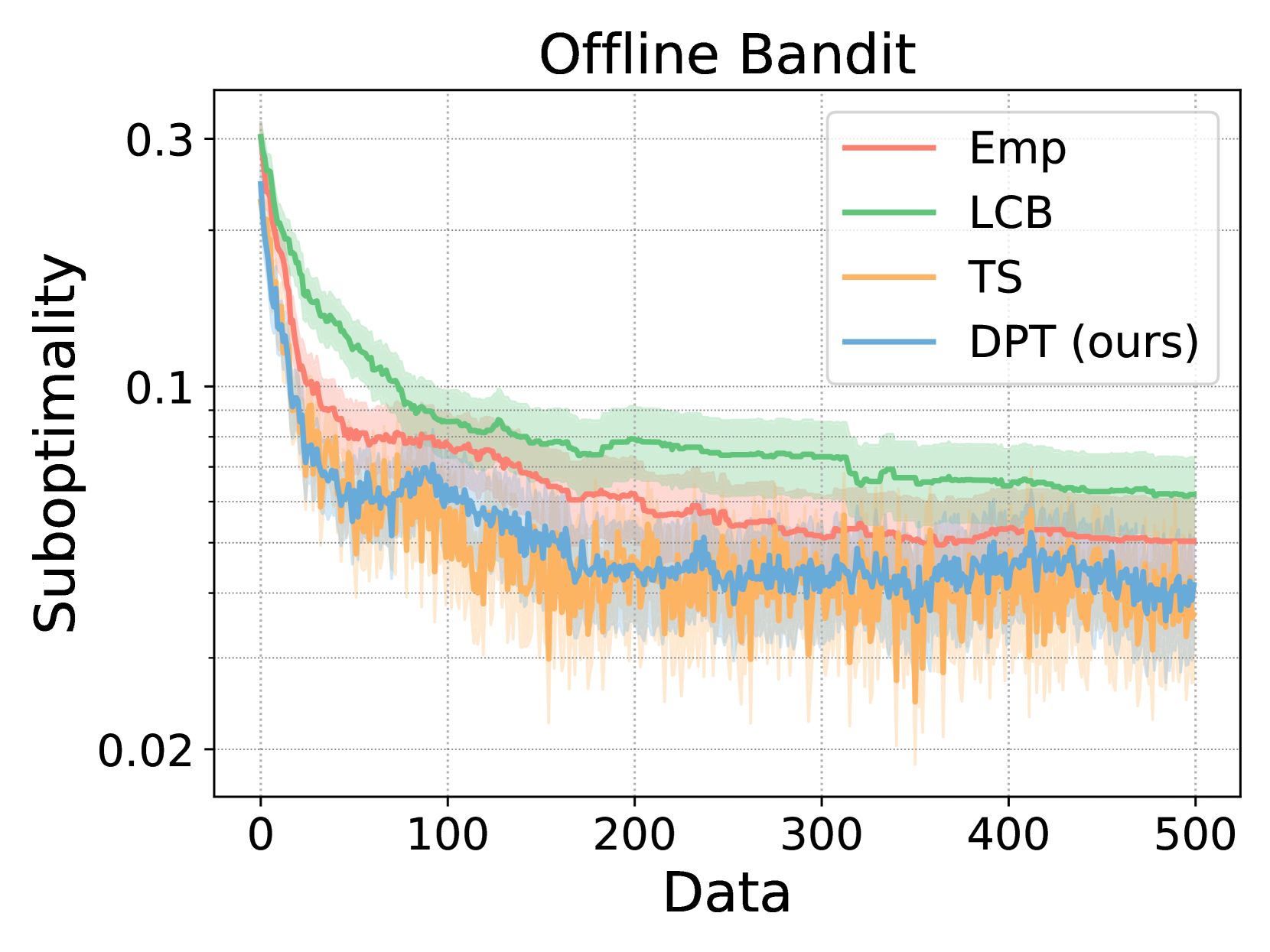
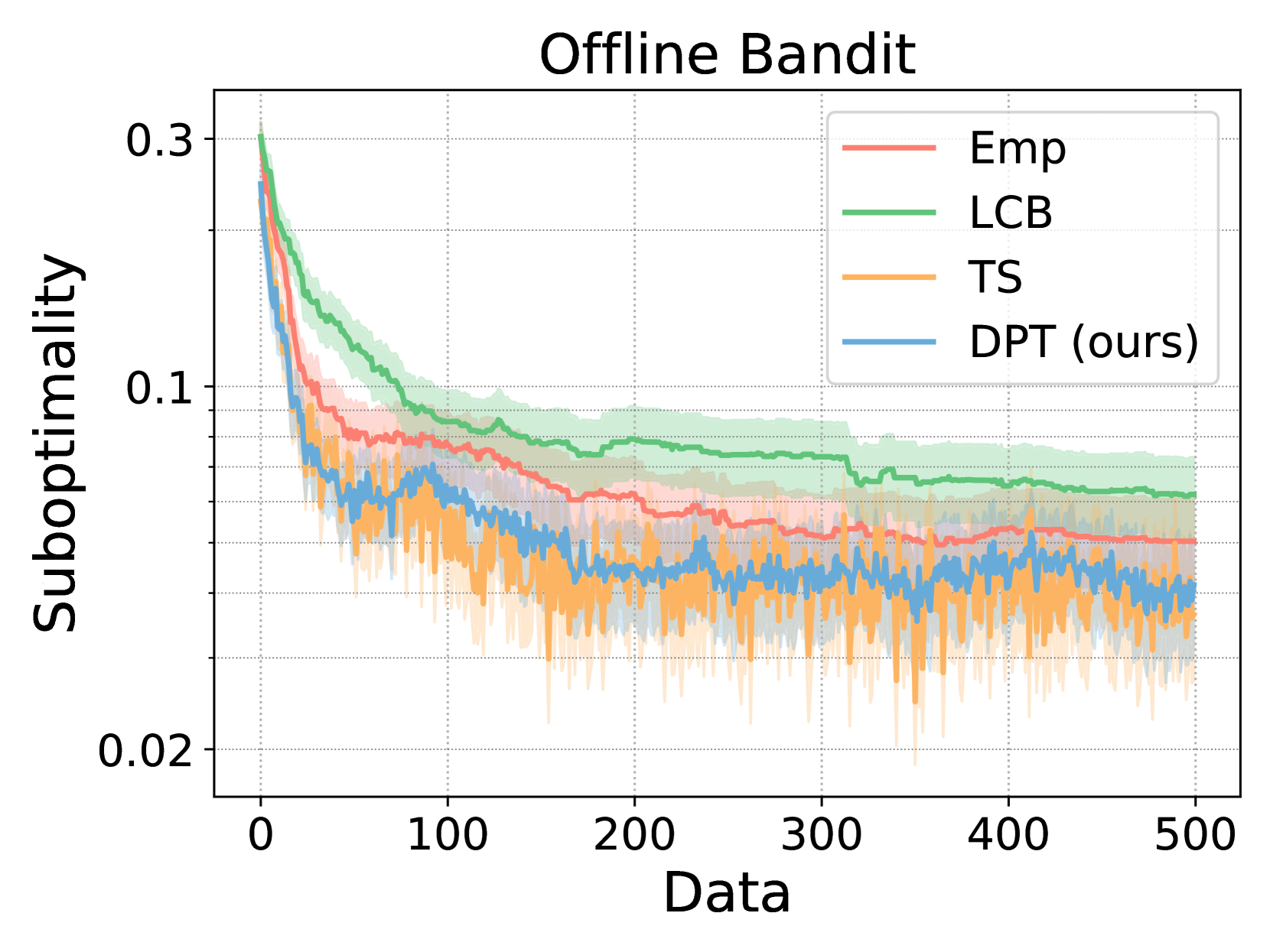
- DPT achieves sub-linear regret on linear bandit tasks even when pretrained on data from a uniform sampling policy (which has linear regret)
- Matches the performance of LinUCB (an optimal analytic algorithm) on linear bandits with unknown representations, outperforming algorithm distillation
- In Dark Room MDPs, DPT effectively explores to find an unseen goal state and generalizes to new map layouts not seen during pretraining
Breakthrough Assessment
8/10
Provides a strong theoretical and empirical link between supervised pretraining and Bayesian posterior sampling, showing transformers can learn to explore and improve over training data—addressing a major criticism of prior work like Decision Transformer.