📝 Paper Summary
Reinforcement Finetuning (RFT)
Curriculum Learning
Mathematical Reasoning
AdaRFT accelerates mathematical reasoning training by dynamically adjusting the difficulty of training problems to maintain a 50% model success rate, ensuring samples are neither too easy nor too hard.
Core Problem
Standard Reinforcement Finetuning is compute-inefficient because models waste resources training on problems they can already solve easily or problems that are currently impossible for them.
Why it matters:
- RFT is computationally expensive due to repeated rollout generation and reward computation
- Static datasets or fixed curricula fail to adapt to the model's evolving capabilities, leading to suboptimal learning rates
- Existing filtering methods (removing easy/hard samples) are rigid, require repeated expensive rollouts, or rely on brittle manual thresholds
Concrete Example:
A model capable of solving high school algebra might waste thousands of training steps iterating on elementary arithmetic (zero learning signal) or International Math Olympiad problems (zero reward), resulting in slow convergence.
Key Novelty
Adaptive Curriculum Reinforcement Finetuning (AdaRFT)
- Maintains a 'target difficulty' scalar that represents the ideal problem difficulty for the model's current skill level
- Updates this target dynamically using a feedback loop: if recent rewards are high, increase target difficulty; if low, decrease it
- Samples training batches by selecting problems from the dataset whose estimated difficulty scores are closest to the current target
Architecture
Pseudocode for AdaRFT showing the loop of difficulty estimation, batch selection, PPO update, and target difficulty adjustment.
Evaluation Highlights
- Reduces training time by up to 2× compared to standard baselines (Abstract)
- Demonstrates high correlation (Pearson r = -0.34) between estimated difficulty scores and ground-truth model success rates
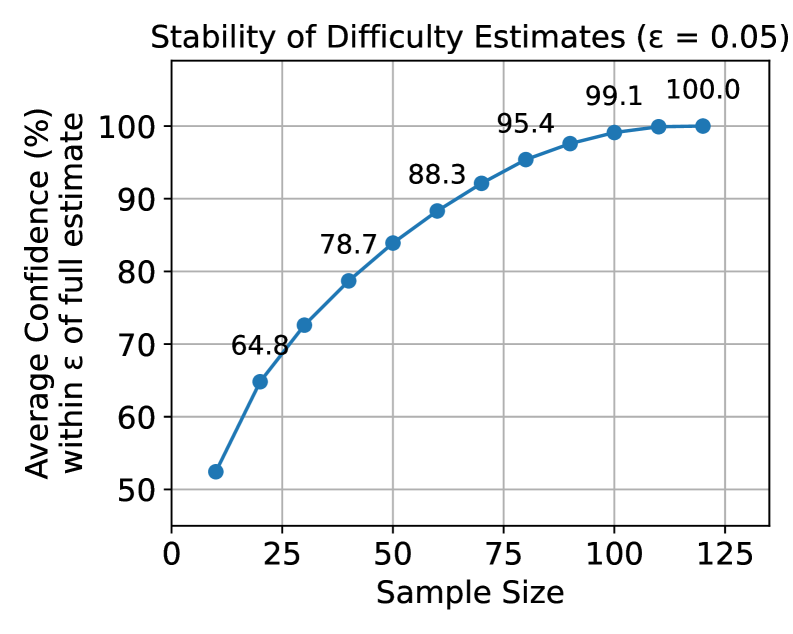
- Achieves robust difficulty estimation with as few as 64 rollouts (estimates remain within ±0.05 of ground truth >90% of the time)
Breakthrough Assessment
7/10
A theoretically grounded, lightweight improvement to standard RFT that addresses a major efficiency bottleneck. While the core idea of 'train on the frontier' is classic, the adaptive implementation for LLMs is practical and effective.