📝 Paper Summary
Humanoid Robotics
Sim-to-Real Transfer
Locomotion Control
Deep RL enables low-cost miniature humanoid robots to learn agile soccer skills via self-play in simulation and transfer them zero-shot to the physical world.
Core Problem
Controlling bipedal humanoids is difficult due to instability, hardware fragility, and limited degrees of freedom, often resulting in slow, conservative movements when using classical methods.
Why it matters:
- Existing humanoid control relies on expensive model-based predictive control that lacks generality and agility
- Current learning-based approaches focus on isolated skills (walking, jumping) rather than integrated long-horizon behaviors
- Deploying agile policies on low-cost hardware is challenging due to the 'sim-to-real' gap and safety risks
Concrete Example:
A standard scripted controller for the OP3 robot walks by keeping foot plates parallel to the ground to maintain static stability, resulting in a slow, shuffling gait that cannot effectively chase a moving ball or recover from pushes.
Key Novelty
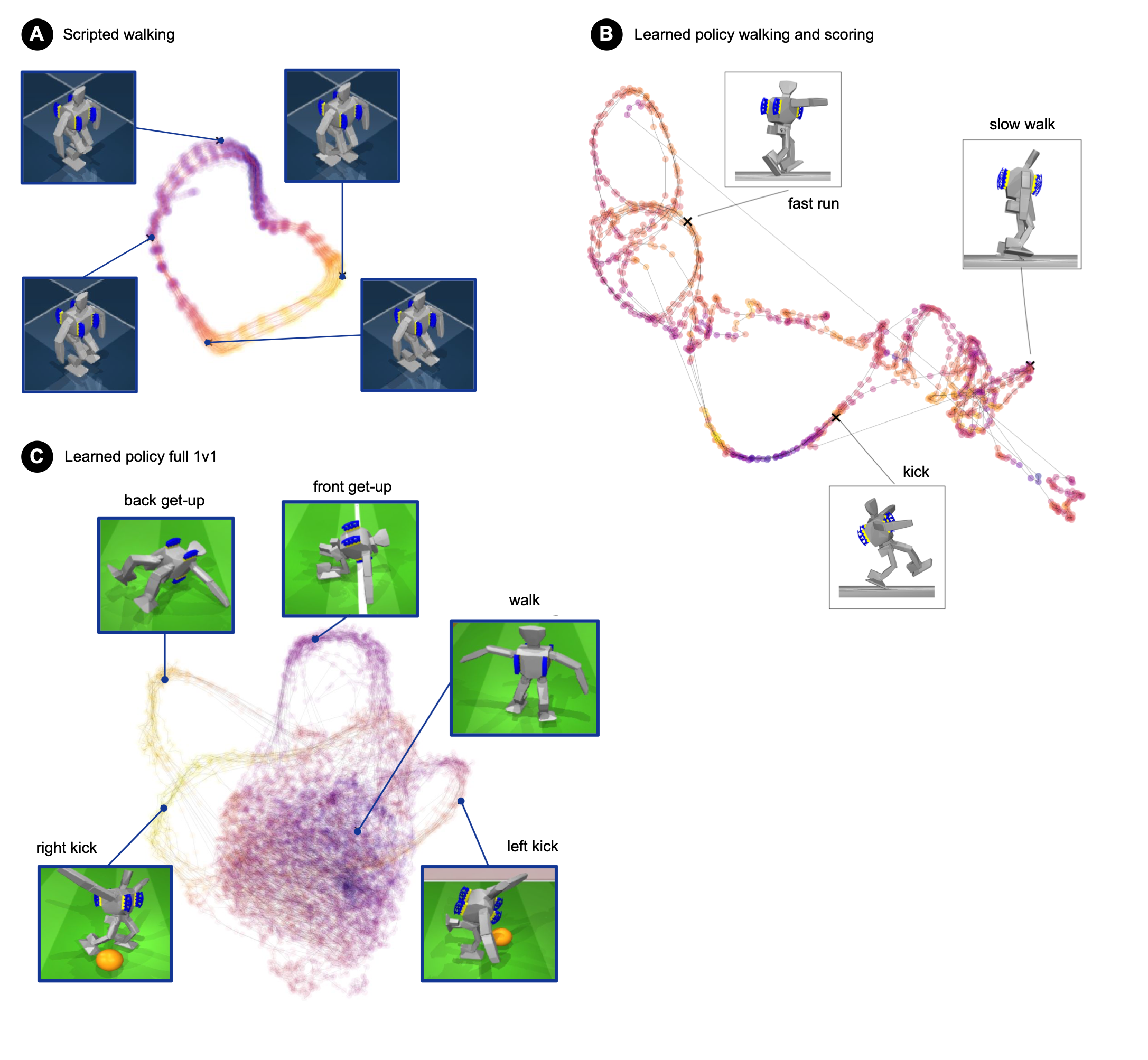
Two-Stage Deep RL with Skill Distillation
- Trains teacher policies for specific skills (getting up, scoring) and distills them into a single agent trained via multi-agent self-play
- Uses domain randomization and perturbations during simulation training to enable zero-shot transfer to real robots without fine-tuning
- Encourages emergent agility (like pivoting on foot corners) rather than specifying gait parameters manually
Architecture
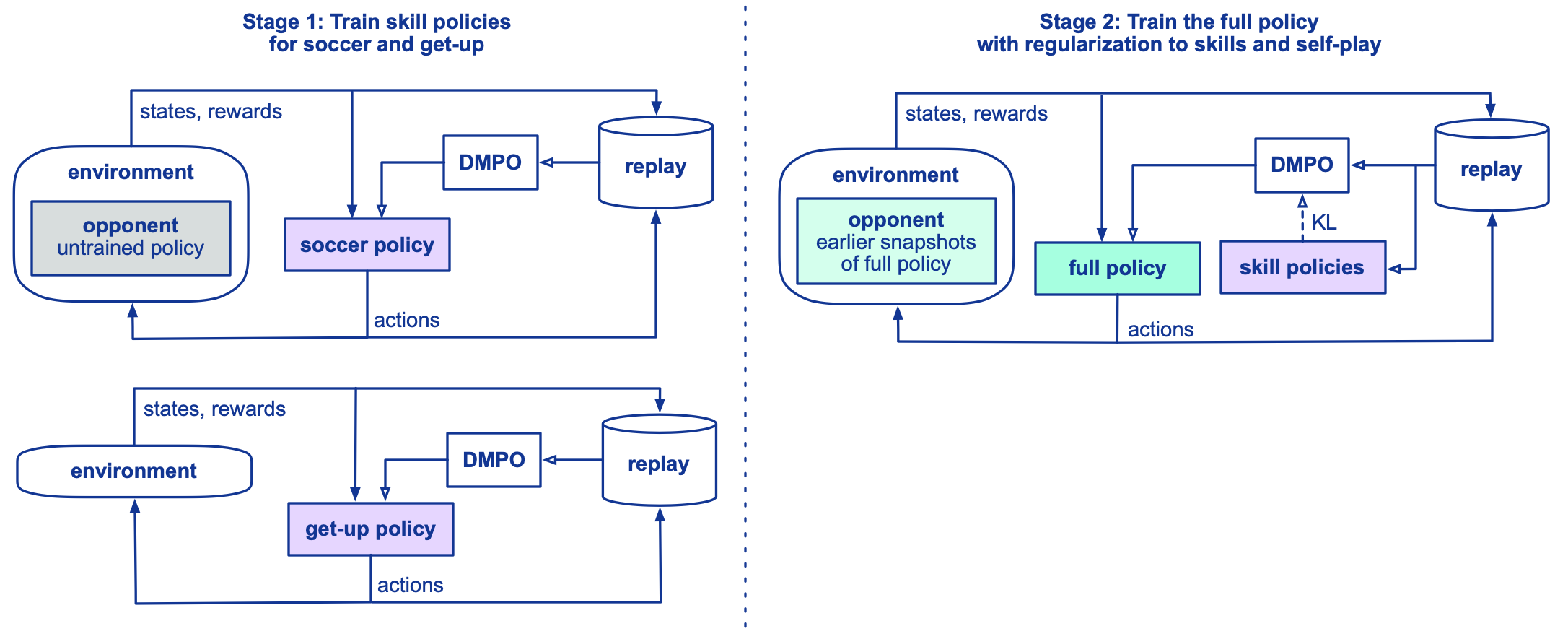
Overview of the learning method showing the two-stage training pipeline.
Evaluation Highlights
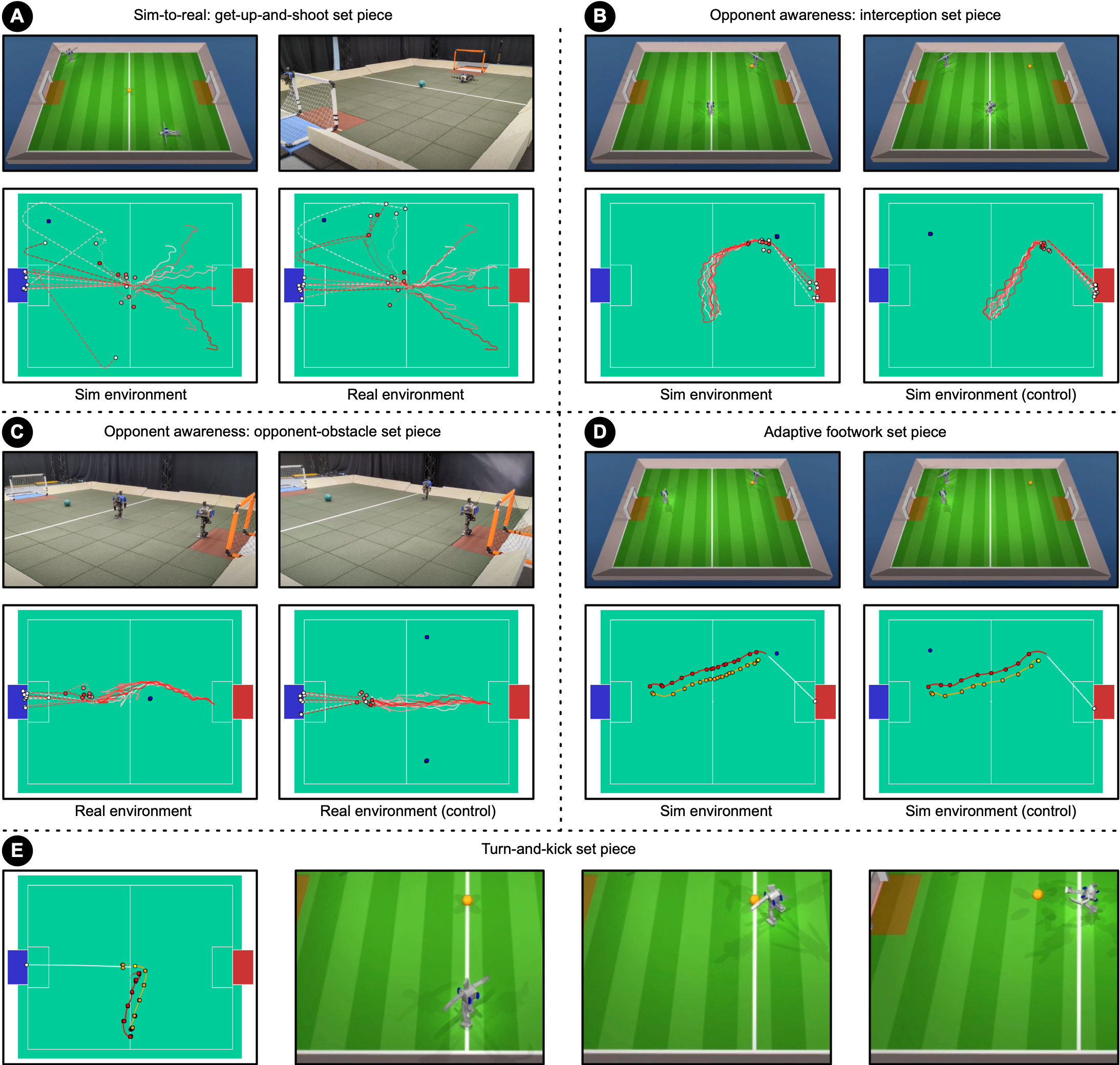
- Walks 181% faster and turns 302% faster than the specialized manually-designed baseline controller on real hardware
- Reduces time to get up from the ground by 63% compared to the scripted baseline
- Achieves a 58% scoring rate in real-world 'get-up-and-shoot' scenarios (transferring from 70% in simulation)
Breakthrough Assessment
9/10
Demonstrates highly dynamic, agile full-body control on cheap, imperfect hardware with zero-shot transfer. The emergent behaviors (agile turning, tactical blocking) significantly outperform traditional engineering approaches.