📝 Paper Summary
Autonomous Drone Racing
Robotic Control Systems
Reinforcement learning outperforms optimal control in autonomous drone racing not by optimizing better, but by optimizing a better objective—maximizing gate progress directly rather than tracking a fixed trajectory.
Core Problem
Optimal Control (OC) systems rely on a separation of planning (generating a trajectory) and control (tracking it), which limits performance when facing unmodeled dynamics or disturbances at the physical limit.
Why it matters:
- Agile robotics requires operating at physical limits where accurate modeling is extremely difficult
- Traditional pipeline separation leads to erratic behavior when the real system deviates from the planned trajectory due to aerodynamic effects or voltage drops
- Prior state-of-the-art OC methods required conservative tuning or operated below physical limits to maintain stability in the real world
Concrete Example:
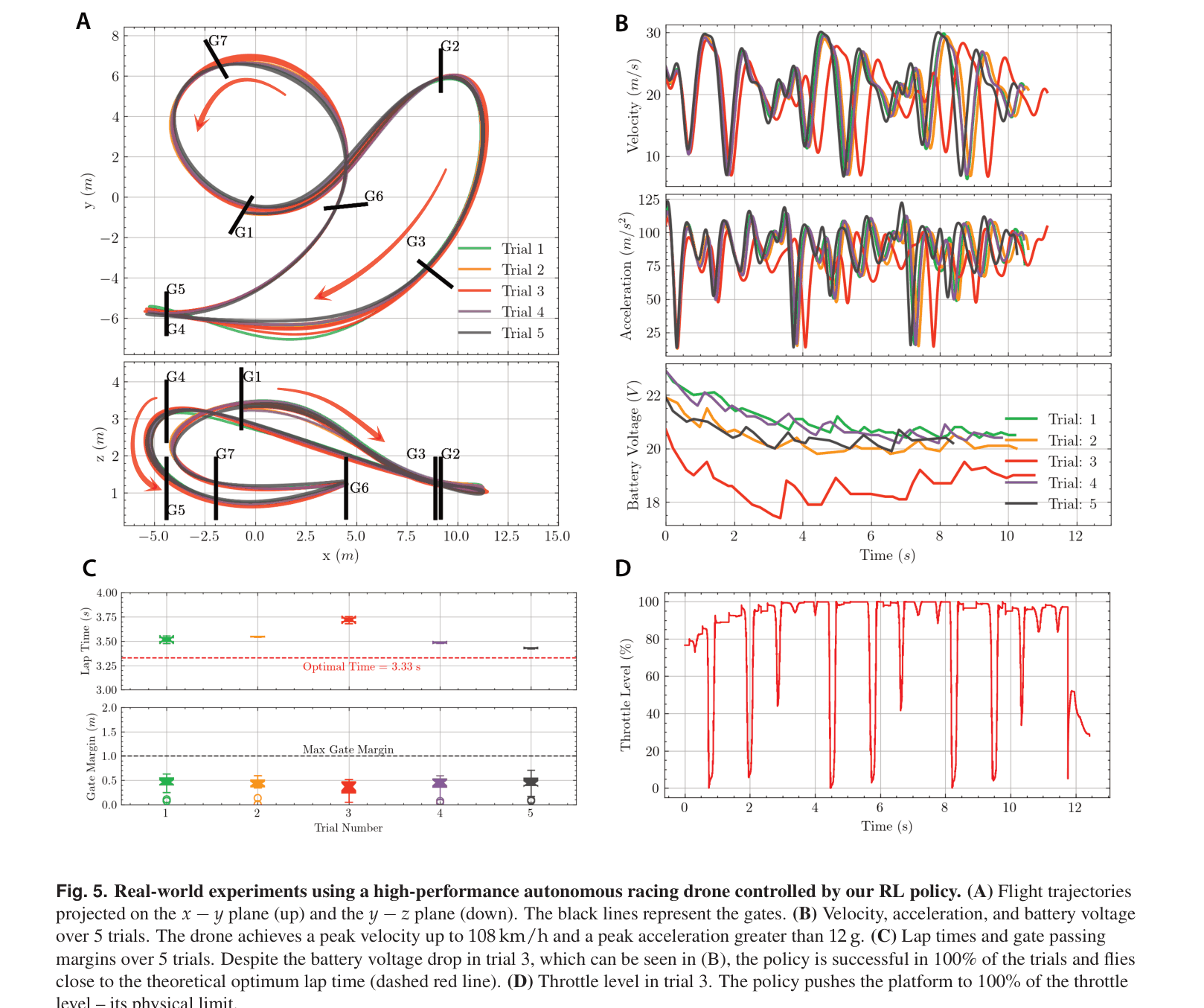
When a drone flying at 108 km/h experiences a sudden battery voltage drop, a trajectory-tracking controller tries to force the drone back onto a now-infeasible pre-planned time path, leading to a crash. The proposed RL policy, however, adapts its path to simply maximize progress through the next gate, successfully completing the lap.
Key Novelty
Direct Task-Level Optimization via RL
- Replaces the standard 'Plan Trajectory → Track Trajectory' pipeline with a single neural network policy that maps observations directly to control commands
- Optimizes a 'Gate Progress' objective that rewards moving toward the next gate rather than punishing deviation from a specific spatial path
- Leverages domain randomization during simulation training to build robustness against unmodeled aerodynamic effects and system delays
Architecture
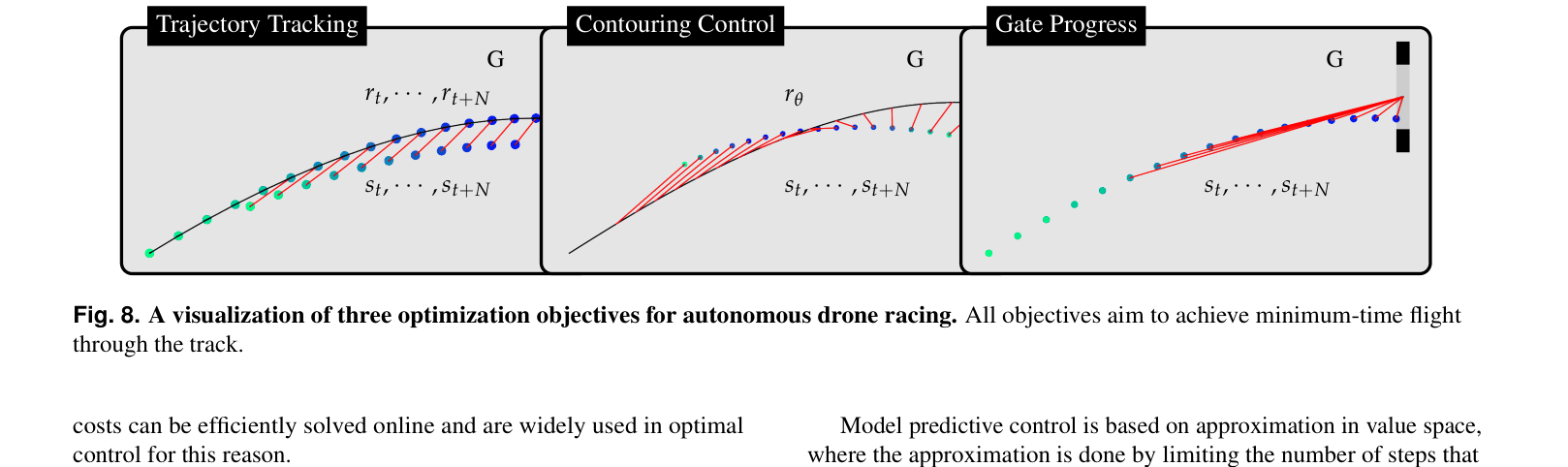
Conceptual comparison of three optimization objectives: Trajectory Tracking, Contouring Control, and Gate Progress.
Evaluation Highlights
- Achieved peak acceleration >12 g and velocity of 108 km/h on a physical drone, pushing the platform to its mechanical limit
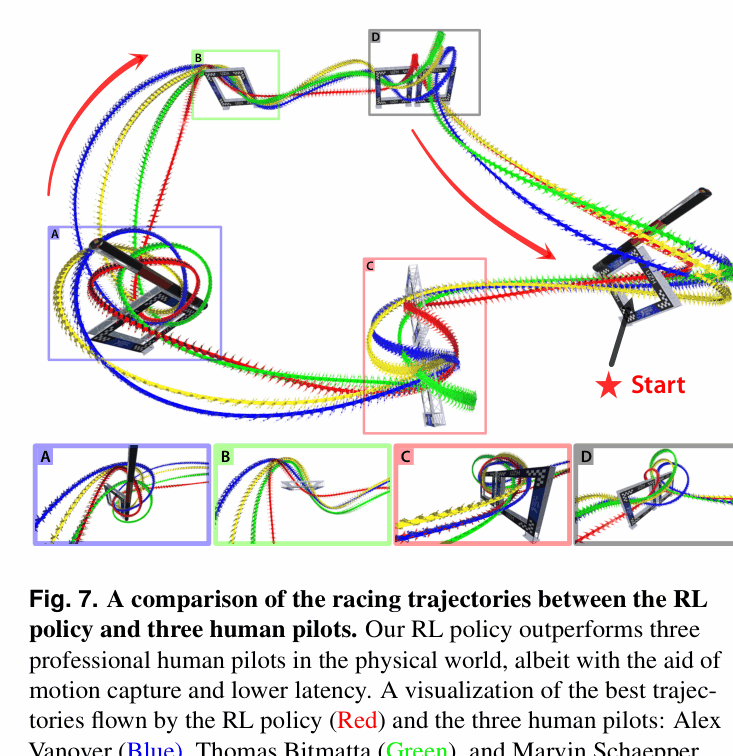
- Outperformed 3 human world champions in real-world time trials (e.g., 15.59s for 3 laps vs. human best of 17.21s)
- Maintained 100% success rate in simulation with realistic dynamics, whereas optimal control baselines dropped to 0-20% success
Breakthrough Assessment
9/10
This work demonstrates superhuman performance in a highly dynamic physical task, definitively showing RL's superiority over traditional Optimal Control in agile settings. It fundamentally shifts the design paradigm from trajectory tracking to task-level optimization.