📝 Paper Summary
Robotic Manipulation
Dexterous Grasping
Cross-Embodiment Learning
CrossDex enables a single reinforcement learning policy to control diverse robotic hands by mapping actions to a universal human hand space and retargeting them to specific robot kinematics.
Core Problem
Existing dexterous grasping policies are tailored to specific hand hardware, meaning a new robot hand requires expensive retraining and data collection from scratch.
Why it matters:
- Training separate policies for every new robotic hand is computationally expensive and data-inefficient
- Current methods struggle to transfer skills between hands with different numbers of fingers or degrees of freedom (e.g., ShadowHand vs. LEAP Hand)
- Real-world deployment is hindered by the lack of generalized controllers that can adapt to available hardware without extensive tuning
Concrete Example:
A policy trained for a 5-fingered ShadowHand cannot control a 4-fingered LEAP Hand because their action spaces (22 DoF vs 16 DoF) and physical structures are incompatible.
Key Novelty
Universal Action/Observation Space via Human Hand Proxy
- Defines a universal action space using human hand 'eigengrasps' (principal motion components), which are then retargeted to specific robot joints
- Unifies observation space by using fingertip and palm positions instead of robot-specific joint angles, making the input consistent across different hands
- Uses a teacher-student framework where state-based policies train a single vision-based policy via DAgger (Dataset Aggregation)
Architecture
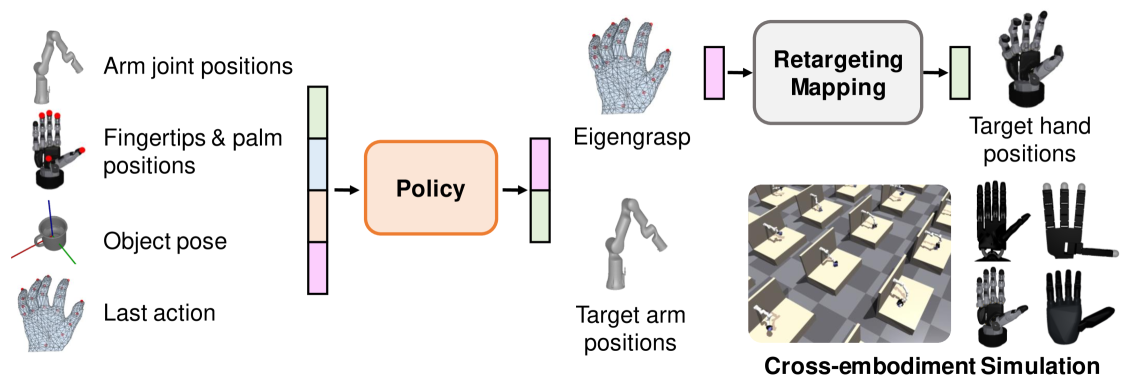
The CrossDex framework pipeline including the retargeting process and policy inputs/outputs
Evaluation Highlights
- Achieves ~80% success rate on YCB objects across four different training hands (ShadowHand, Allegro, LEAP, SVH) using a single vision-based policy
- Demonstrates zero-shot generalization to two unseen hands (Faive Hand, MJCF ShadowHand) with success rates comparable to trained hands
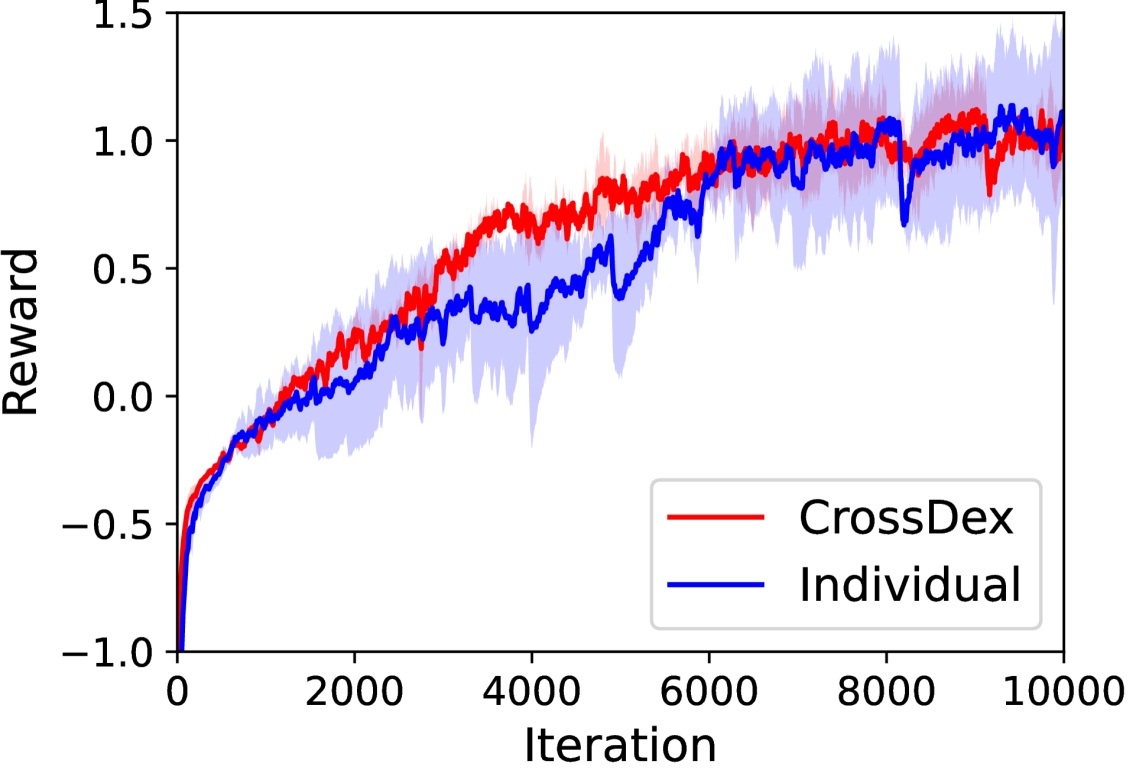
- Fine-tuning the universal policy on a new hand is significantly more efficient than training from scratch, reaching high performance in fewer iterations
Breakthrough Assessment
8/10
Significant step towards universal robotic control. Successfully bridges disparate hardware morphologies (different fingers/DoFs) with a single policy, showing strong zero-shot transfer.