📝 Paper Summary
Sim-to-Real Transfer
Visual Reinforcement Learning
Legged Robotics
The paper demonstrates that agile, multi-agent robot soccer policies can be learned end-to-end from egocentric RGB vision by using NeRF-based simulation rendering and reusing data across experiments.
Core Problem
Training robots to play soccer from onboard vision is challenging due to partial observability, motion blur, and the lack of expensive external state estimation (like motion capture) typically used in prior work.
Why it matters:
- Real-world robots often cannot rely on external sensors or ground-truth state estimation outside of controlled labs
- Existing methods relying on depth sensors or modular pipelines often fail to capture the complex, context-dependent coordination required for agile multi-agent tasks
- Manually scripting active perception (looking for the ball while running) is difficult in dynamic environments
Concrete Example:
A robot using a fixed camera might lose track of a ball rolling behind it. While a state-based agent 'knows' the ball is there via ground truth, a vision-based agent must learn to actively turn its head to track the object, a behavior that is hard to script manually.
Key Novelty
End-to-End Vision-Based Soccer via NeRF Simulation
- Uses Neural Radiance Fields (NeRFs) to render realistic backgrounds in the MuJoCo simulator, enabling zero-shot transfer of vision policies to the real world without domain randomization of textures
- Trains end-to-end from pixels using an asymmetric actor-critic where the critic sees ground truth state but the actor sees only pixels, avoiding the need for explicit state estimation modules
- Employs Replay across Experiments (RaE) to pool experience data from varying past experiments, significantly speeding up the slow process of vision-based training
Architecture
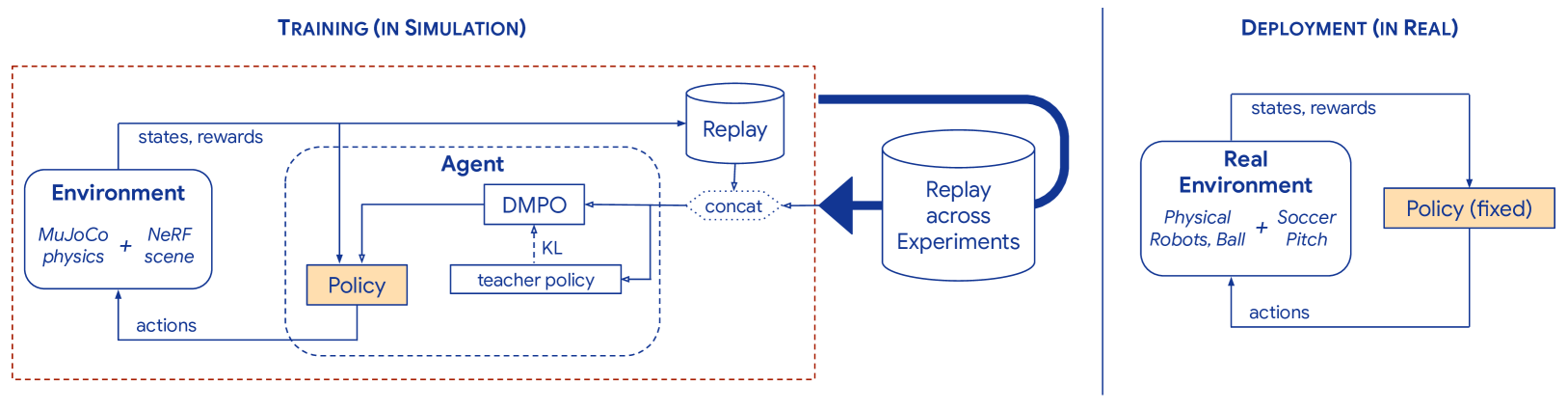
The deployment pipeline on the real robot showing sensors and data flow
Evaluation Highlights
- Vision-based agents achieve 0.86 scoring accuracy in simulation, slightly outperforming state-based agents (0.82) that have access to ground-truth positions
- In real-world zero-shot deployment, vision agents achieve a 0.40 scoring rate on penalty shots (compared to 0.58 for state-based agents), demonstrating viable transfer despite significant sensor noise
- Maintains competitive agility: vision agents walk at comparable speeds and kick with equivalent power (1.79 m/s ball velocity) to privileged state-based agents
Breakthrough Assessment
8/10
Significant achievement in demonstrating agile, dynamic multi-agent behavior (soccer) from raw pixels without depth sensors or modular state estimators, successfully transferring to real hardware.