📊 Experiments & Results
Evaluation Setup
Meta-training on simple environments (Grid-Worlds or MinAtar), then evaluating generalization to unseen environments and horizons.
Benchmarks:
- Grid-Worlds (Discrete navigation (Variable horizons))
- MinAtar (Discrete control (Atari-like))
- Brax (Continuous control (Physics))
Metrics:
- Final Return (often normalized against A2C or raw score)
- Training Efficiency (steps to convergence)
- Statistical methodology: Mean evaluation return across 3 random seeds with standard error bars (Figures 6/7).
Experiment Figures
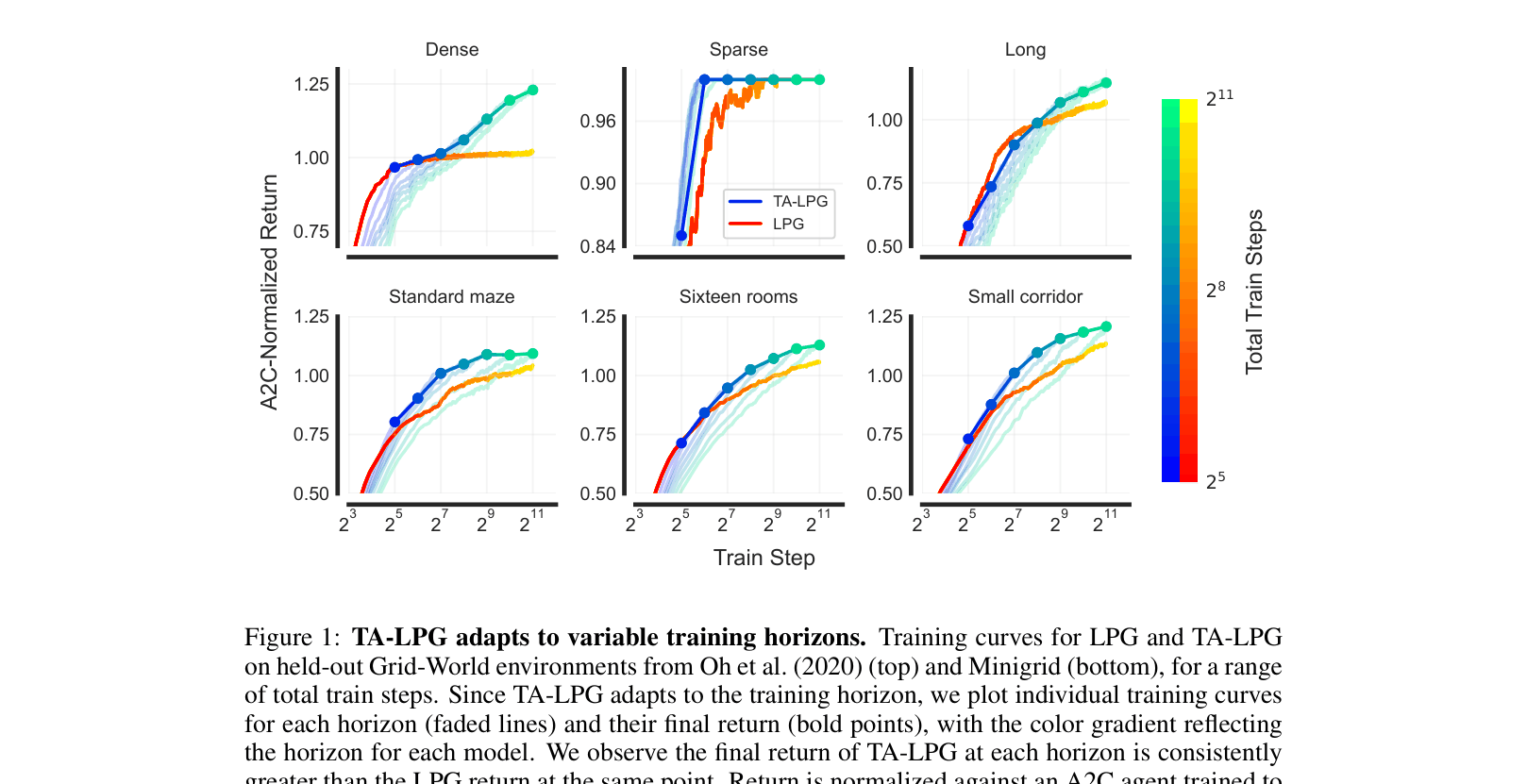
Training curves comparing TA-LPG and LPG on Grid-Worlds across different training horizons.
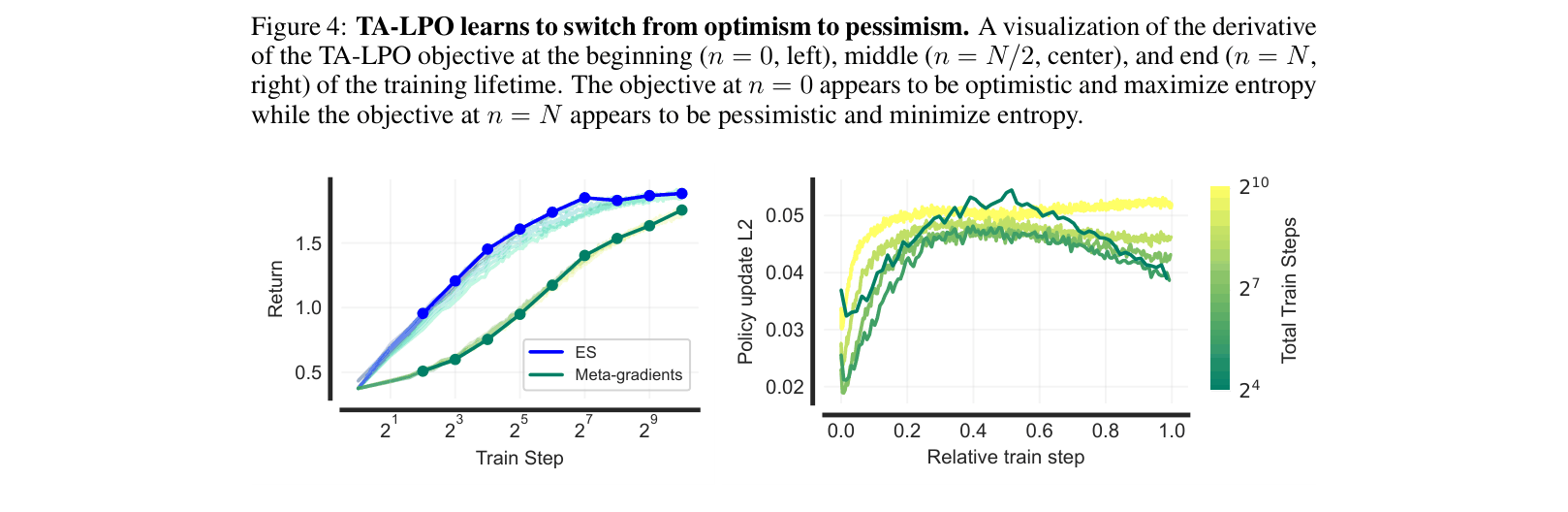
Visualization of the learned TA-LPO drift function derivative at different training stages (Start, Middle, End).
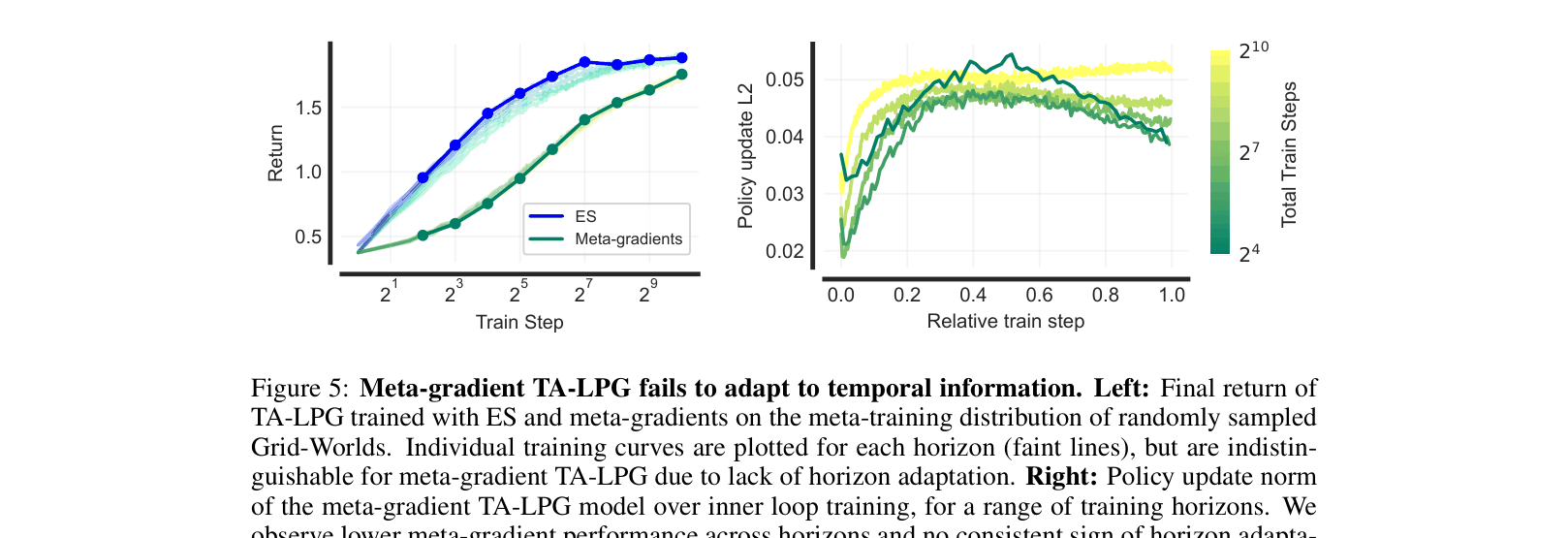
Comparison of TA-LPG trained with ES vs. Meta-gradients.
Main Takeaways
- TA-LPG consistently outperforms LPG across all training horizons on held-out Grid-Worlds, often reaching peak performance significantly faster (e.g., 1/8th the steps for 'sparse' tasks).
- TA-LPO generalizes effectively to continuous control tasks (Brax) and other MinAtar games despite being meta-trained only on MinAtar SpaceInvaders, outperforming PPO and LPO.
- Meta-gradient optimization fails to discover temporally-aware strategies because truncated backpropagation is myopic; Evolution Strategies (ES) are essential for learning lifetime-dependent schedules.
- Qualitative analysis shows TA-LPO discovers an 'asymmetric rollback schedule': it is optimistic (high entropy) early in training and pessimistic (risk-averse, low entropy) late in training.