📝 Paper Summary
Reinforcement Learning under Partial Observability
Equivariant Neural Networks
The paper extends the theory of group-invariant MDPs to partially observable settings (POMDPs) and proposes equivariant recurrent actor-critic agents that leverage geometric symmetries to significantly improve sample efficiency in robotic tasks.
Core Problem
Standard Reinforcement Learning (RL) methods in partially observable domains (PORL) require massive amounts of data to learn policies, often failing to generalize across symmetric variations of the same task.
Why it matters:
- Robotic learning is notoriously sample-inefficient, making real-world training prohibitive
- Existing symmetry-preserving (equivariant) methods are limited to fully observable MDPs, failing in realistic scenarios where robots have limited sensors (e.g., top-down views hiding state properties)
- Data augmentation is an inefficient alternative, requiring larger models and longer training times to learn symmetries that could instead be baked into the architecture
Concrete Example:
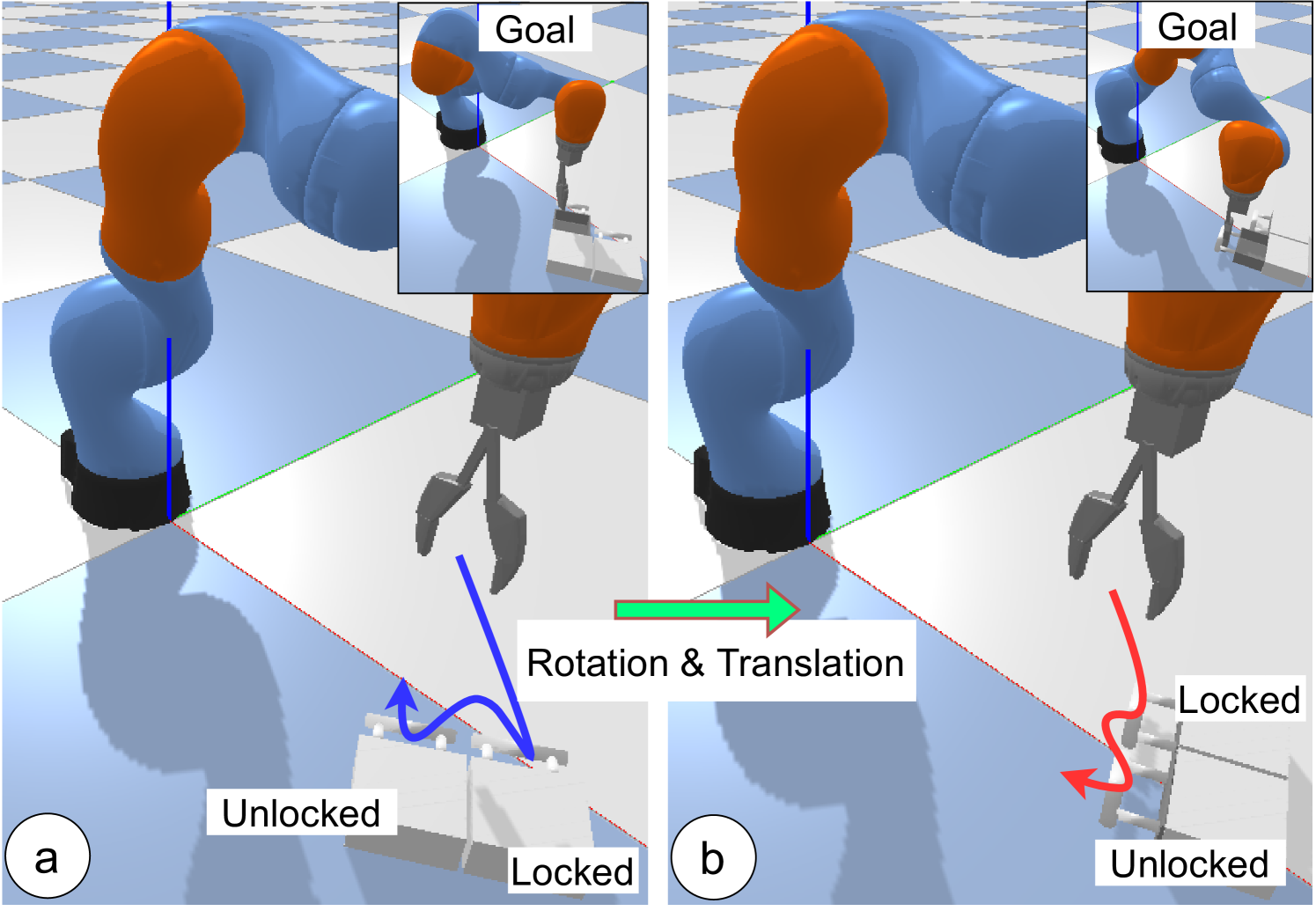
In a 'Drawer-Opening' task, a robot sees a top-down view of two drawers but doesn't know which is unlocked. The optimal strategy (pulling a drawer to test it) is rotationally symmetric: if the chest rotates 90 degrees, the optimal action sequence should rotate 90 degrees. Standard agents must relearn this behavior for every orientation, while equivariant agents generalize instantly.
Key Novelty
Group-Invariant POMDPs & Equivariant Recurrent Agents
- Formalizes 'Group-Invariant POMDPs', proving that if the environment dynamics and observation functions are symmetric, the optimal policy and value function are also symmetric (equivariant/invariant)
- Embeds this symmetry directly into the agent's neural architecture using equivariant convolutions and recurrent layers, forcing the agent to treat rotated inputs as mathematically equivalent without seeing them during training
- Extends popular RL algorithms (SAC, A2C) to be both recurrent (dealing with partial observability) and equivariant (dealing with symmetry)
Architecture
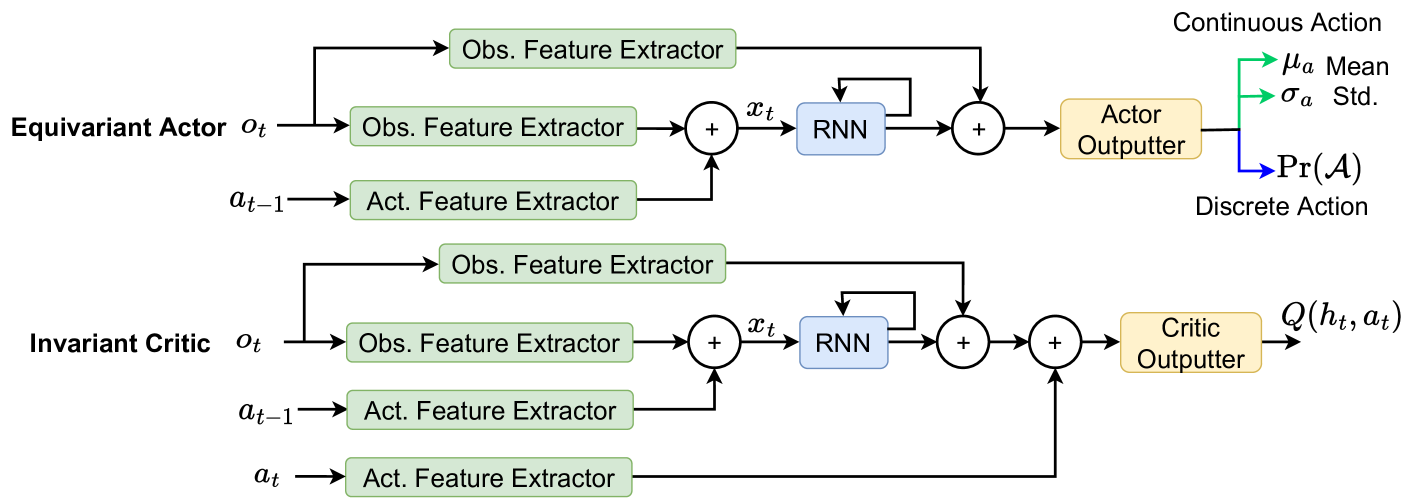
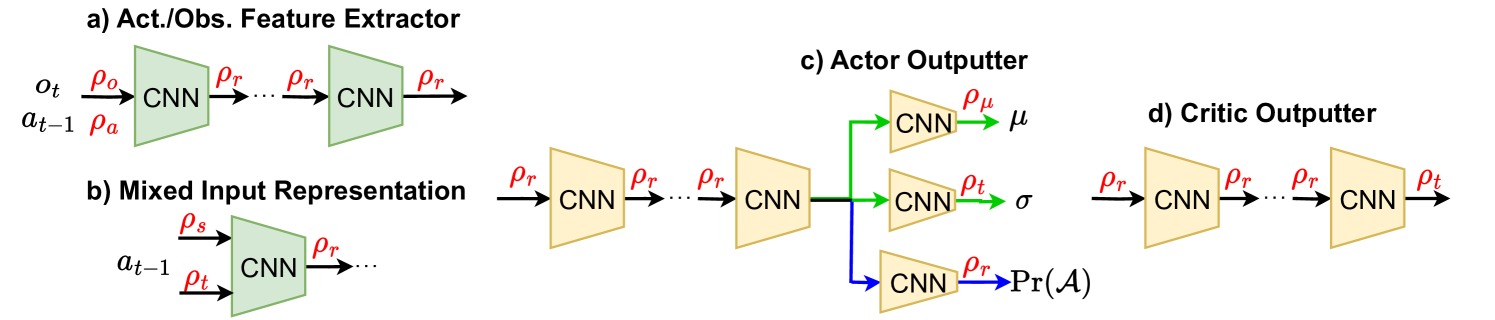
The architecture of the Equivariant Actor-Critic network.
Evaluation Highlights
- Achieves ~95-100% success rate on real-robot Drawer Opening task with only 1.5k training steps, while non-equivariant baselines fail completely (<20%)
- Outperforms non-equivariant recurrent baselines by large margins on 4 simulated robotic manipulation tasks, often reaching optimal performance 2-5x faster
- Demonstrates robustness to unseen rotations during testing, maintaining high performance where standard baselines drop significantly
Breakthrough Assessment
8/10
Provides a solid theoretical foundation extending equivariant RL to POMDPs and demonstrates strong empirical gains on real hardware. It bridges a crucial gap for practical robotic learning.