📝 Paper Summary
Transfer Learning in Reinforcement Learning
Catastrophic Forgetting
Fine-tuning pre-trained RL models fails because agents forget skills in unvisited state subspaces (FPC), a problem solvable by applying knowledge retention techniques like behavioral cloning.
Core Problem
In RL fine-tuning, the interplay between actions and observations causes agents to visit only a subset of states ('Close') early on, leading to the catastrophic forgetting of pre-trained capabilities in unvisited parts of the environment ('Far').
Why it matters:
- Standard fine-tuning often leads to performance deterioration rather than improvement, negating the benefits of pre-training
- Current approaches in supervised learning assume i.i.d. distributions, which fails in RL where the data distribution is non-stationary and dependent on the agent's current policy
- Valuable capabilities (e.g., solving deeper game levels) are lost before the agent can re-explore those areas
Concrete Example:
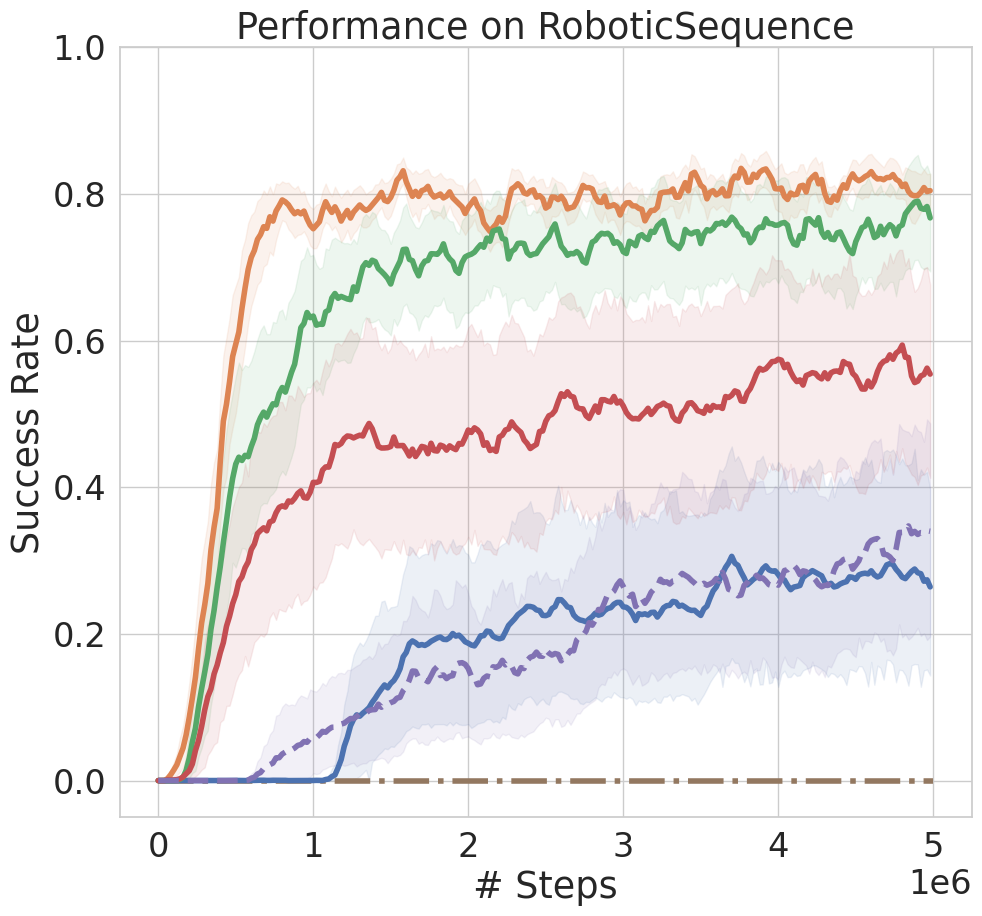
In RoboticSequence, a robot pre-trained to unplug a peg ('Far' task) but fine-tuned on a sequence starting with hammering ('Close' task) forgets how to unplug the peg by the time it relearns to hammer, resulting in a 0% success rate for the full sequence.
Key Novelty
Forgetting of Pre-trained Capabilities (FPC) Mitigation
- Conceptualizes RL fine-tuning failure as a memory retention problem specifically caused by 'State Coverage Gap' (rarely visiting states where pre-training helps) and 'Imperfect Cloning Gap' (drift from expert behavior)
- Demonstrates that standard continual learning methods (EWC, Behavioral Cloning, Kickstarting) are sufficient to fix this, treating fine-tuning as a forgetting mitigation task rather than just an exploration task
Architecture
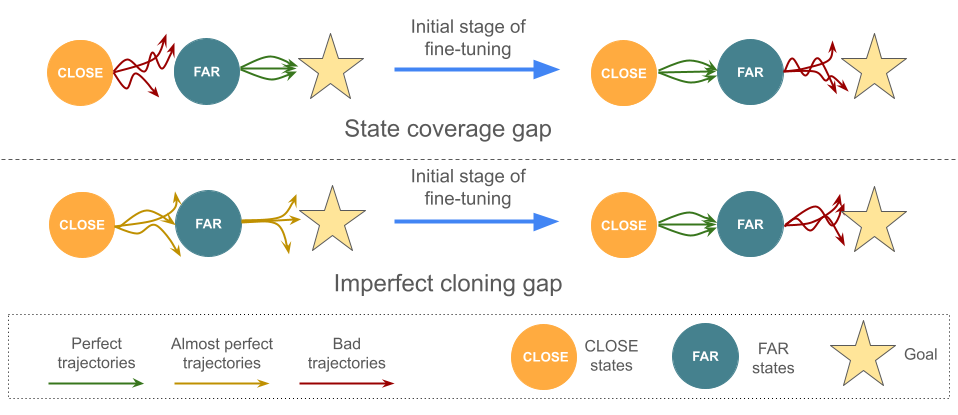
Conceptual illustration of 'Close' and 'Far' state sets and how forgetting occurs during fine-tuning.
Evaluation Highlights
- Achieves >10,000 points on NetHack (Human Monk), a 2x improvement over the previous state-of-the-art neural model (~5,000 points)
- Solves all four stages of the RoboticSequence task 80% of the time using Behavioral Cloning, while vanilla fine-tuning collapses to near 0%
- Maintains ~1.0 success rate in Montezuma's Revenge Room 7 (the 'Far' state) using knowledge retention, whereas vanilla fine-tuning drops significantly during early training
Breakthrough Assessment
8/10
Identifies a fundamental, overlooked cause of transfer failure in RL (FPC) and achieves a massive (2x) SOTA improvement on the difficult NetHack benchmark using simple, existing tools.