📝 Paper Summary
Deep Reinforcement Learning
Neural Network Dynamics
Training Stability
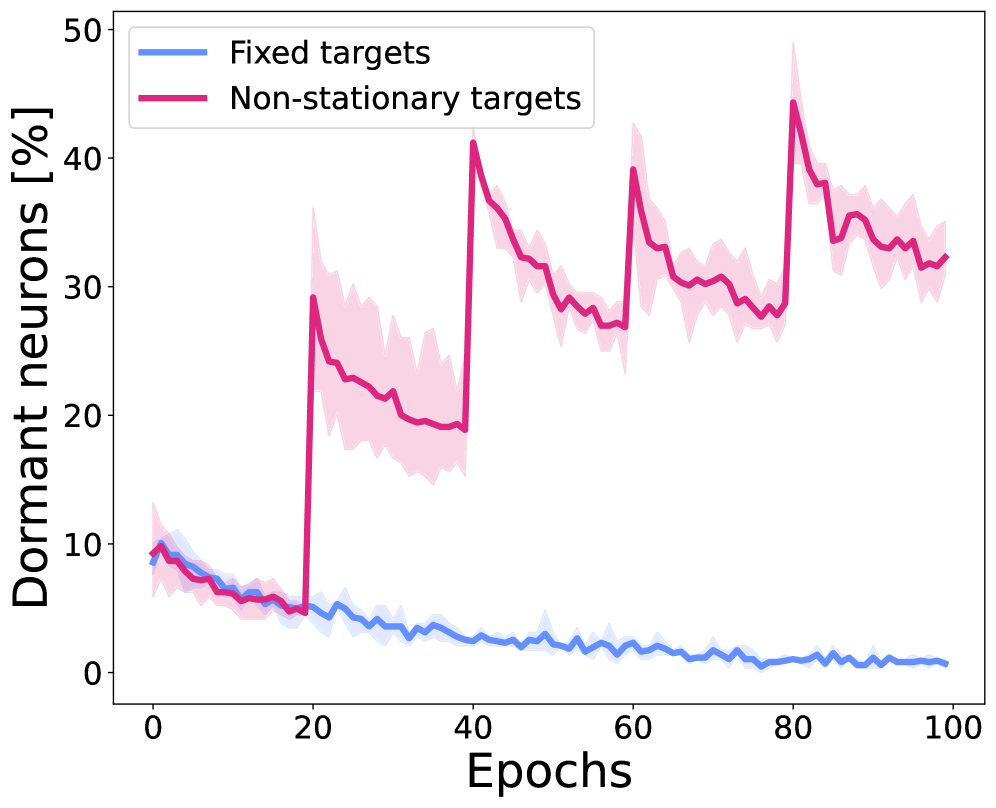
Deep RL agents suffer from increasing numbers of inactive 'dormant' neurons during training due to non-stationary targets; the ReDo algorithm mitigates this by periodically recycling these neurons to maintain network expressivity.
Core Problem
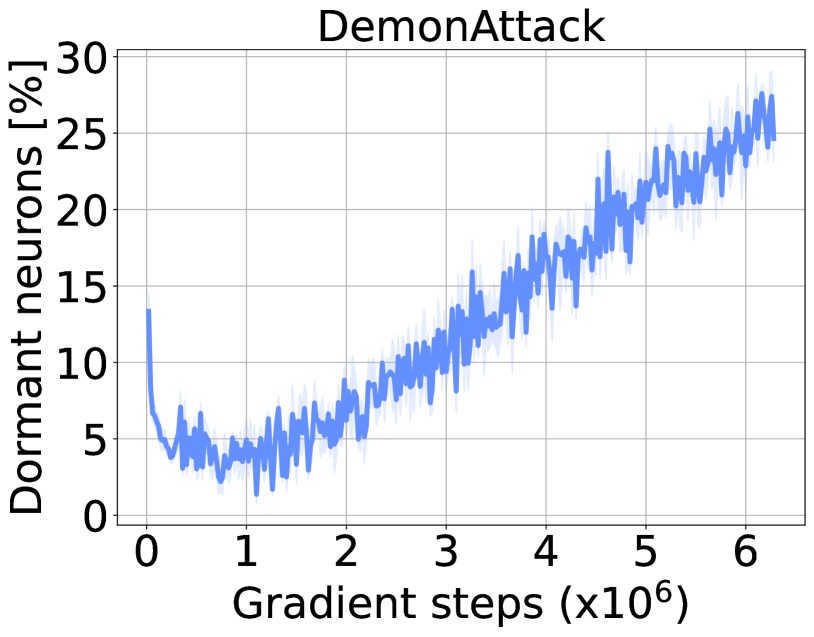
Deep RL networks progressively lose expressivity during training as neurons become 'dormant' (permanently inactive), a phenomenon exacerbated by non-stationary targets and high replay ratios.
Why it matters:
- Dormant neurons reduce the effective capacity of the network, preventing it from fitting new targets as the policy evolves
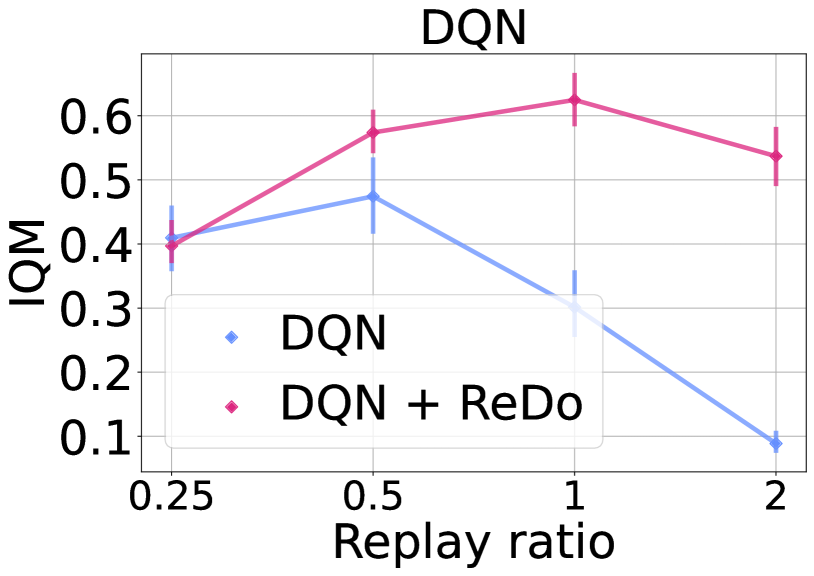
- The phenomenon limits the ability to scale up the replay ratio (updates per environment step), which is crucial for sample efficiency but typically leads to performance collapse
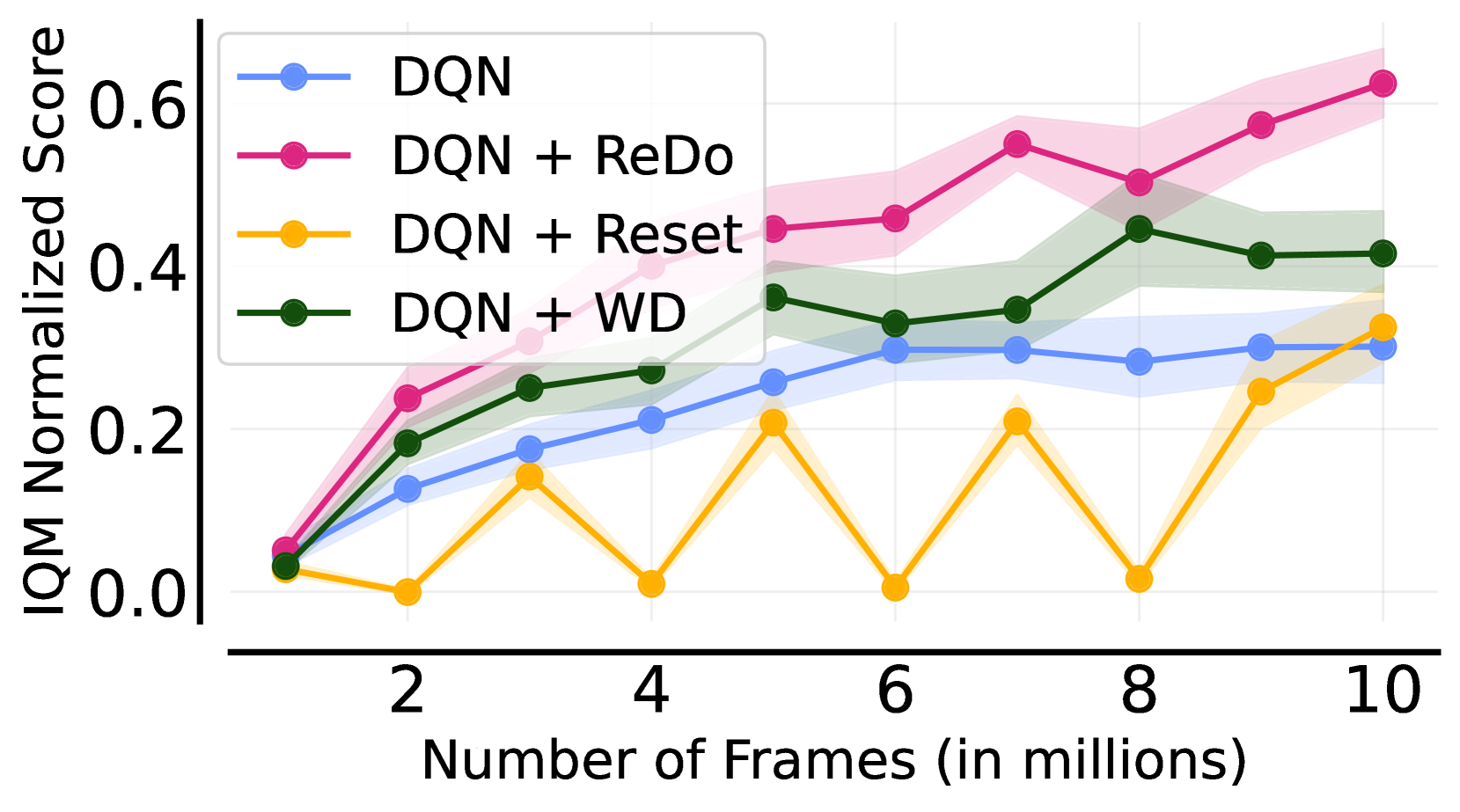
- Standard periodic network resets are too drastic, causing the agent to 'forget' learned behaviors and requiring costly recovery time
Concrete Example:
In the game DemonAttack, a DQN agent's network sees the percentage of dormant neurons rise steadily throughout training. If this agent is then used to learn a new task (or fine-tuned), it fails to improve compared to a randomly initialized network because its capacity is effectively locked.
Key Novelty
Recycling Dormant Neurons (ReDo)
- Periodically identifies neurons with near-zero activation scores across a batch
- Resets the incoming weights of these dormant neurons to their initial distribution, effectively 'waking them up' to learn new features
- Sets outgoing weights to zero to ensure the recycling step does not immediately disrupt the network's current output or performance
Architecture
The ReDo logic loop integrated into training
Evaluation Highlights
- ReDo prevents performance collapse in DQN when scaling replay ratio to 2, effectively maintaining performance where standard DQN fails
- Improves Interquantile Mean (IQM) scores on Atari 100K with DrQ(ε) at high replay ratios (e.g., ratio 8), outperforming the baseline
- Reduces the fraction of dormant neurons significantly compared to standard training, correlating with improved ability to fit value functions
Breakthrough Assessment
8/10
Identifies a fundamental pathology in Deep RL (dormant neurons) and provides a simple, effective fix that enables better scaling of replay ratios. The analysis is thorough across multiple domains.