📝 Paper Summary
Legged Robotics
Proprioceptive Locomotion
Sim-to-Real Transfer
DreamWaQ enables quadrupedal robots to traverse challenging terrains using only proprioception by jointly learning body state estimation and implicit terrain context via a context-aided estimator network.
Core Problem
Robots relying on exteroception (vision/LiDAR) fail in adverse conditions, while proprioception-only methods suffer from state estimation drift and struggle to adapt to complex terrain properties (friction, softness) over long distances.
Why it matters:
- Visual sensors are unreliable in snow, fog, or transparent obstacles, causing navigation failures
- Existing proprioceptive approaches often use two-stage teacher-student training, which limits the student's exploration and leads to suboptimal policies
- Inaccurate body state estimation on stairs or slopes can lead to catastrophic falls, limiting robot deployment in the wild
Concrete Example:
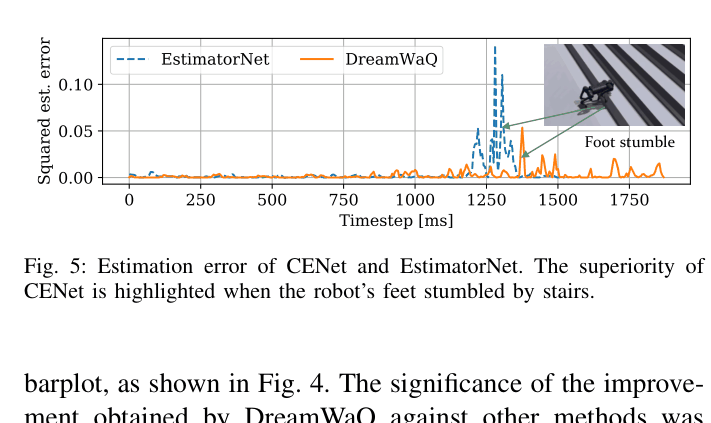
When a robot stumbles on stairs, standard estimators (like EstimatorNet) fail to track body velocity accurately due to the sudden shock, causing the robot to fall. DreamWaQ's estimator uses learned context to maintain accurate velocity estimates, allowing recovery.
Key Novelty
Context-Aided Estimator Network (CENet) with Adaptive Bootstrapping
- Replaces separate state estimation and adaptation modules with a unified network (CENet) that jointly estimates body velocity and latent terrain context (friction, hazards)
- Uses an auto-encoding auxiliary task to reconstruct future observations, forcing the network to implicitly learn forward-backward dynamics and terrain properties
- Employs Adaptive Bootstrapping (AdaBoot) to dynamically adjust how much the policy trusts the learned estimator during training based on reward variance
Architecture
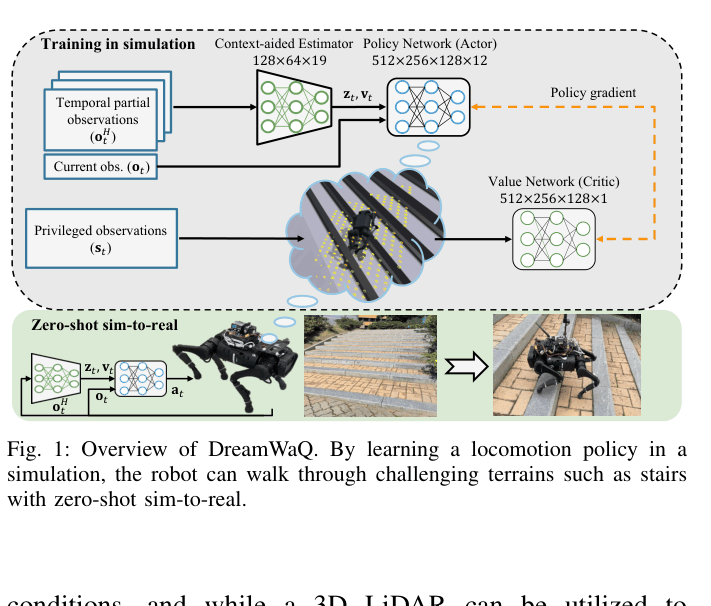
Overview of the DreamWaQ asymmetric actor-critic training architecture
Evaluation Highlights
- Achieved 95.23% survival rate in random disturbance tests, outperforming the RMA-based AdaptationNet baseline (82.37%) by ~13 percentage points
- Withstood lateral pushes of up to 1.121 m/s, significantly higher than the EstimatorNet baseline (0.871 m/s)
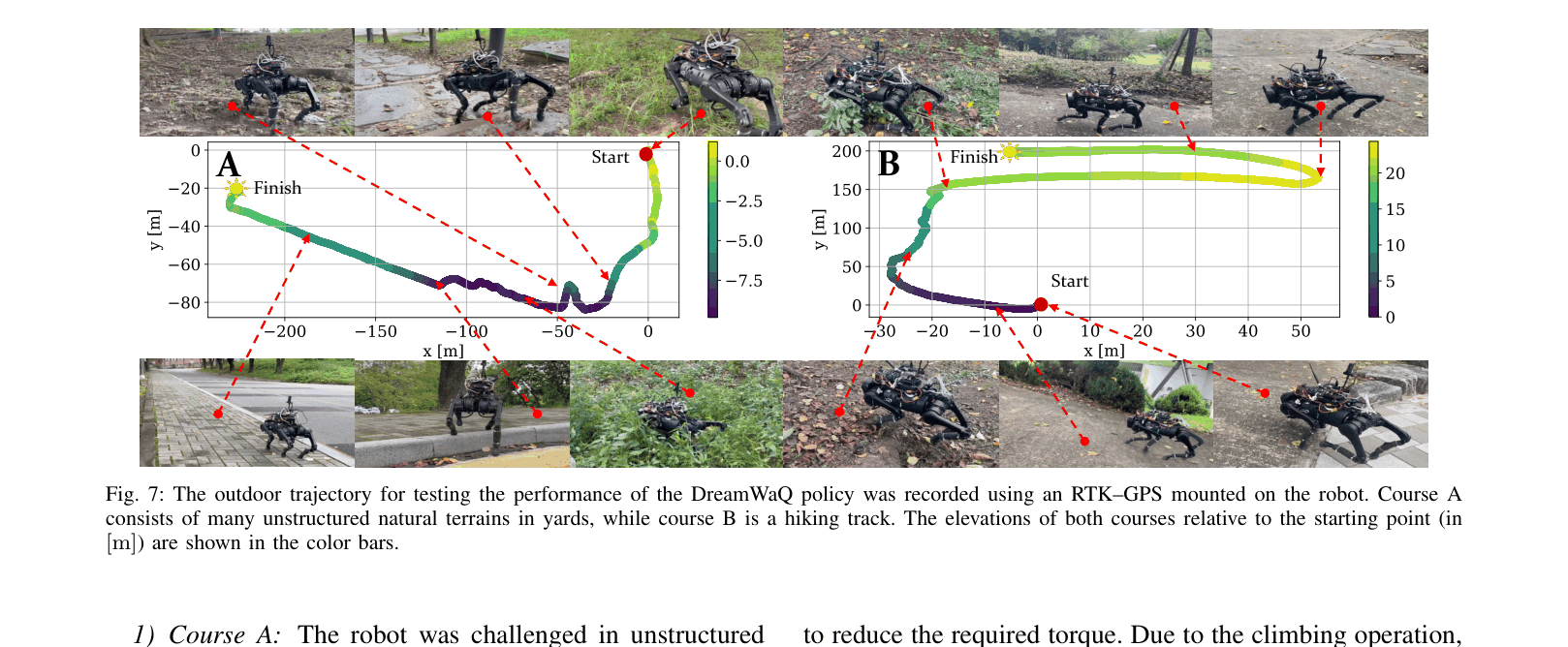
- Demonstrated real-world traversal of a 465m hiking trail with 22m elevation gain in a single continuous run using a Unitree A1 robot
Breakthrough Assessment
8/10
Significant improvement in robust proprioceptive locomotion. The joint estimation/context architecture solves a key bottleneck in blind locomotion, demonstrated by impressive long-distance outdoor deployments.