📝 Paper Summary
Offline Reinforcement Learning
Scalable Transformer Architectures for Control
Perceiver-Actor-Critic (PAC) demonstrates that offline actor-critic algorithms scale to billion-parameter models following supervised-style scaling laws, outperforming behavioral cloning on suboptimal multi-task robotics data.
Core Problem
Supervised Behavioral Cloning (BC) fails when expert data is scarce or suboptimal, while existing offline RL methods have not been successfully scaled to large transformer models due to instability and computational costs.
Why it matters:
- Robotics data is often expensive to collect and suboptimal, making reliance on pure expert demonstrations (required for BC) a major bottleneck
- Prior work scaling transformers for control (like Gato) relies on BC, missing the ability of RL to learn from mixed-quality data or self-improve
- It was previously unknown if RL objectives follow the same power-law scaling relations as supervised learning
Concrete Example:
In the CHEF simulation task involving object stacking with suboptimal data (28% success rate), a standard BC approach only achieves 17.0% success, failing to learn a competent policy. The proposed method recovers a 55.0% success rate from the same suboptimal dataset.
Key Novelty
Perceiver-Actor-Critic (PAC)
- Adapts the Perceiver-IO architecture for RL by using latent cross-attention to handle massive multimodal inputs (vision, text, proprioception) efficiently without quadratic scaling costs
- Injects actions into the Q-function via cross-attention (late fusion) rather than as inputs, enabling efficient evaluation of multiple action candidates against a cached state representation
Architecture
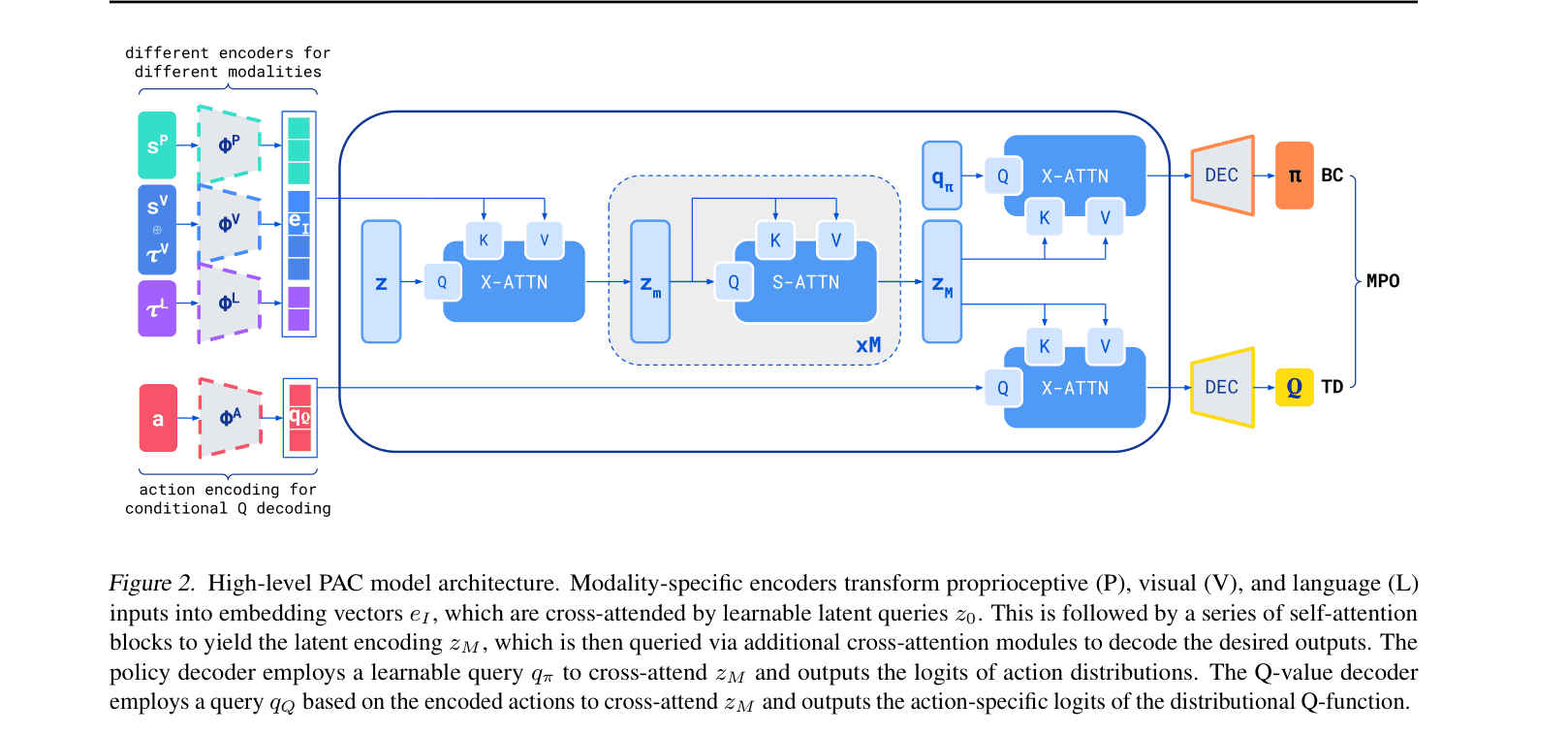
The Perceiver-Actor-Critic (PAC) architecture, detailing the flow from multimodal inputs to policy and value outputs
Evaluation Highlights
- Outperforms Gato baseline on 32 Control Suite tasks (92.1% vs 63.6% expert score) using the same dataset
- Achieves 3x higher success rate than BC (55.0% vs 17.0%) on the CHEF task using severely suboptimal training data
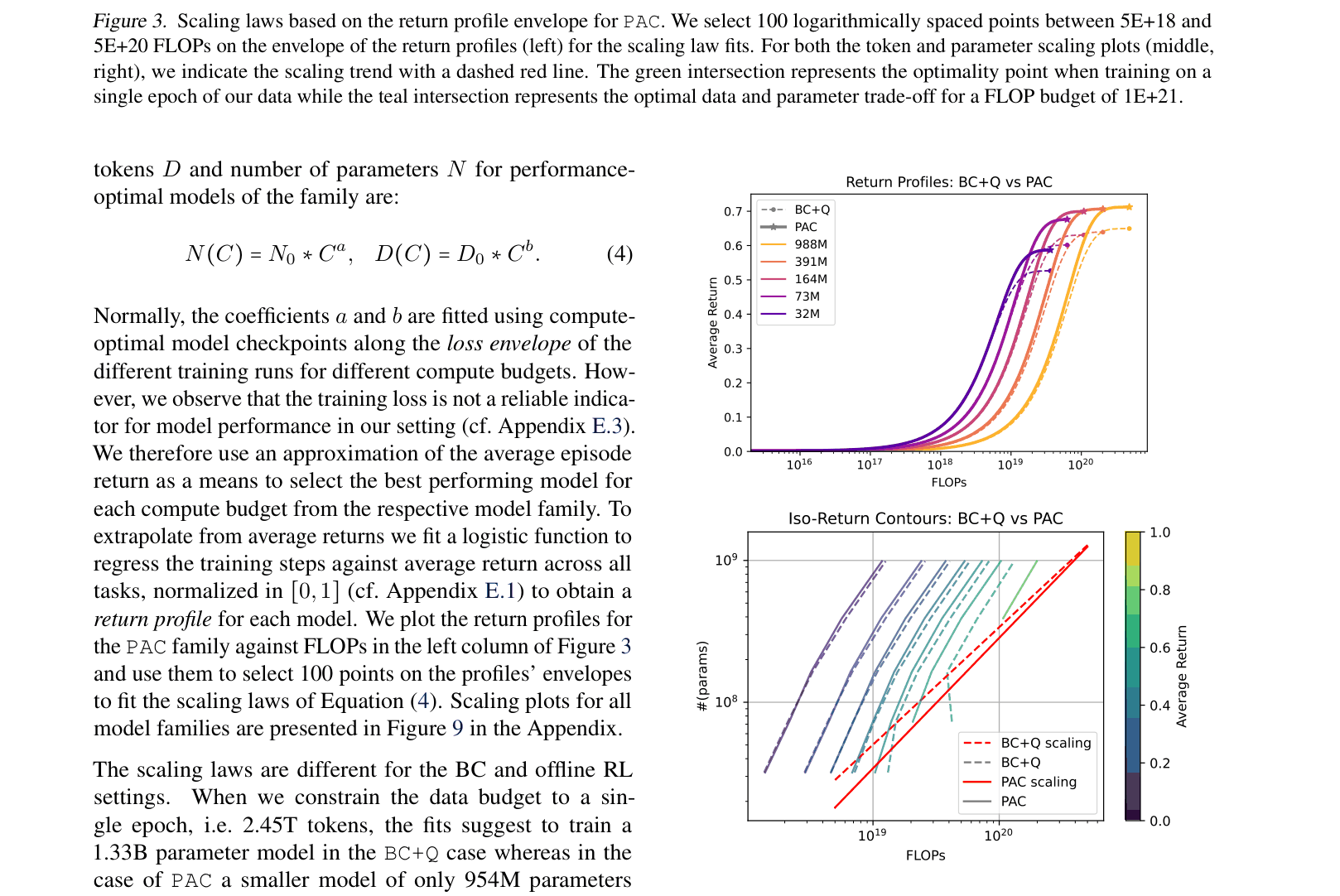
- Scales to 988M parameters, demonstrating for the first time that offline RL follows power-law scaling laws similar to LLMs, often scaling more efficiently than BC
Breakthrough Assessment
9/10
Establishes the first clear evidence of scaling laws for offline RL, provides a recipe for training 1B+ parameter RL agents, and demonstrates mastery of real-world robotics tasks via self-improvement.