📝 Paper Summary
Vision-based Quadrotor Control
Agile Drone Racing
A three-stage framework that trains a teacher policy with privileged states, distills it into a vision-based student, and fine-tunes the student with adaptive RL to achieve agile flight using only RGB images.
Core Problem
Training agile vision-based drone policies from scratch with RL is sample-inefficient and computationally demanding due to high-dimensional inputs, while Imitation Learning (IL) is limited by the expert's performance and struggles with covariate shift.
Why it matters:
- Current autonomous racing drones often rely on external state estimation or IMUs, whereas human pilots fly using only visual cues
- Pure RL from pixels fails to learn effectively within reasonable sample budgets due to the difficulty of exploration in high-dimensional spaces
- Standard Imitation Learning cannot surpass the expert demonstrator and often fails when the drone drifts from the training distribution
Concrete Example:
In the 'SplitS' maneuver, a drone may face frames without visible gate corners. A student policy trained via IL often fails here because it lacks the context to infer actions from partial information, crashing where an RL-refined policy would succeed.
Key Novelty
Teacher-Student Distillation with Adaptive RL Fine-tuning
- Train a privileged expert using state-based RL, then distill it into a vision-based student policy via DAgger (Imitation Learning)
- Use the pre-trained vision student as the initialization for a second round of RL, using a performance-adaptive update rule to prevent catastrophic forgetting during fine-tuning
Architecture
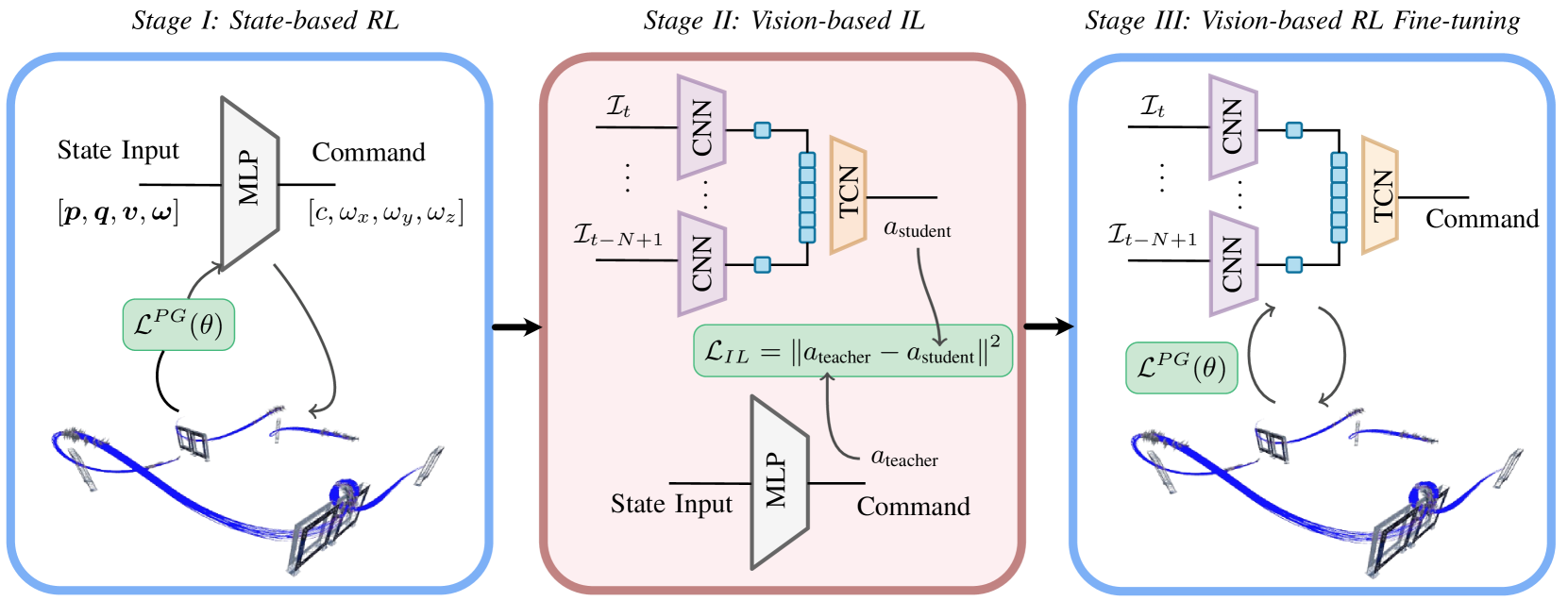
The three-phase training framework: (1) Teacher Training with RL on states, (2) Student Distillation via Imitation Learning on vision, (3) Student Fine-tuning via RL with Asymmetric Critic.
Evaluation Highlights
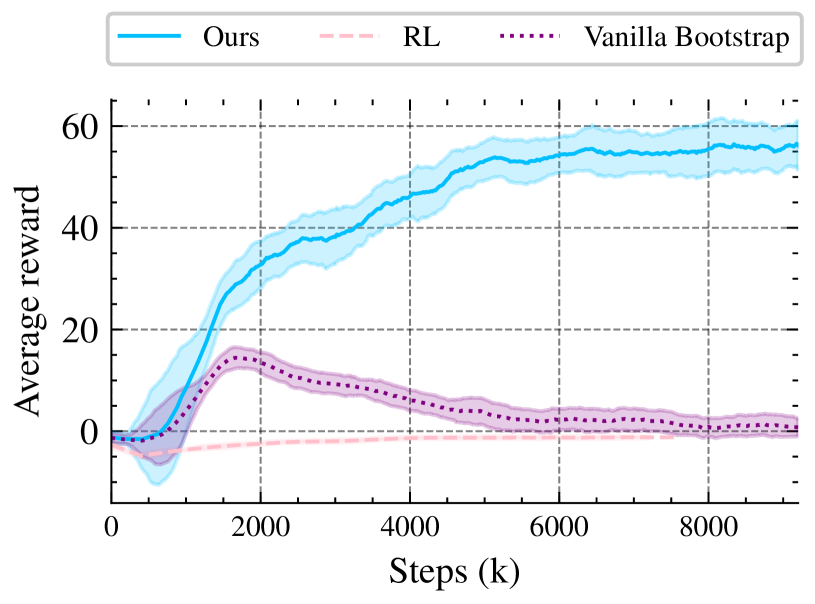
- Achieved 100% Success Rate on the 'SplitS' track using gate corner inputs, whereas RL from scratch failed completely (0%)
- Outperformed standard DAgger (Imitation Learning) by reducing lap times from 6.89s to 6.27s on the SplitS track
- Demonstrated real-world transfer where RL fine-tuning improved success rate from 40% (DAgger) to 100% and reduced gate passing error by ~50%
Breakthrough Assessment
8/10
Significantly advances vision-based agile flight by successfully bridging the gap between sample-efficient IL and high-performance RL, achieving results where baselines fail completely.