📝 Paper Summary
Code Generation
LLM Alignment
ACECode aligns CodeLLMs to generate both efficient and correct code using a reinforcement learning framework driven by a training-free reward signal derived directly from code execution runtimes and test cases.
Core Problem
While CodeLLMs generate functionally correct code, the resulting solutions are often highly inefficient (3-13x slower than human code), and existing optimization methods either require complex execution environments during inference or sacrifice correctness for speed.
Why it matters:
- Inefficient code hinders software performance and competitiveness, especially in resource-constrained environments like mobile devices and IoT systems.
- Optimizing code efficiency contributes to environmental sustainability by reducing energy consumption and carbon footprints of software products.
- Existing solutions like SOAP double inference time due to iterative execution, while PIE sacrifices correctness (functional accuracy) to achieve efficiency gains.
Concrete Example:
A CodeLLM might generate a functionally correct sorting algorithm that is significantly slower (e.g., O(n^2)) than a human-written reference (e.g., O(n log n)). Previous methods like PIE might tune the model to produce the faster algorithm but introduce bugs that fail edge cases, whereas SOAP would require running the slow code first to get feedback.
Key Novelty
ACECode (Aligning Code Correctness and Efficiency)
- Introduces a training-free reward mechanism that uses actual execution feedback (compiler status, test pass rate, and runtime comparison vs. reference) instead of a learned reward model.
- Uses a step-function reward design that penalizes incorrect code while adaptively rewarding correct code based on how much faster it is compared to a human-written reference.
- Optimizes the CodeLLM via PPO (Proximal Policy Optimization) to simultaneously maximize correctness and efficiency without requiring test cases during the final inference stage.
Architecture
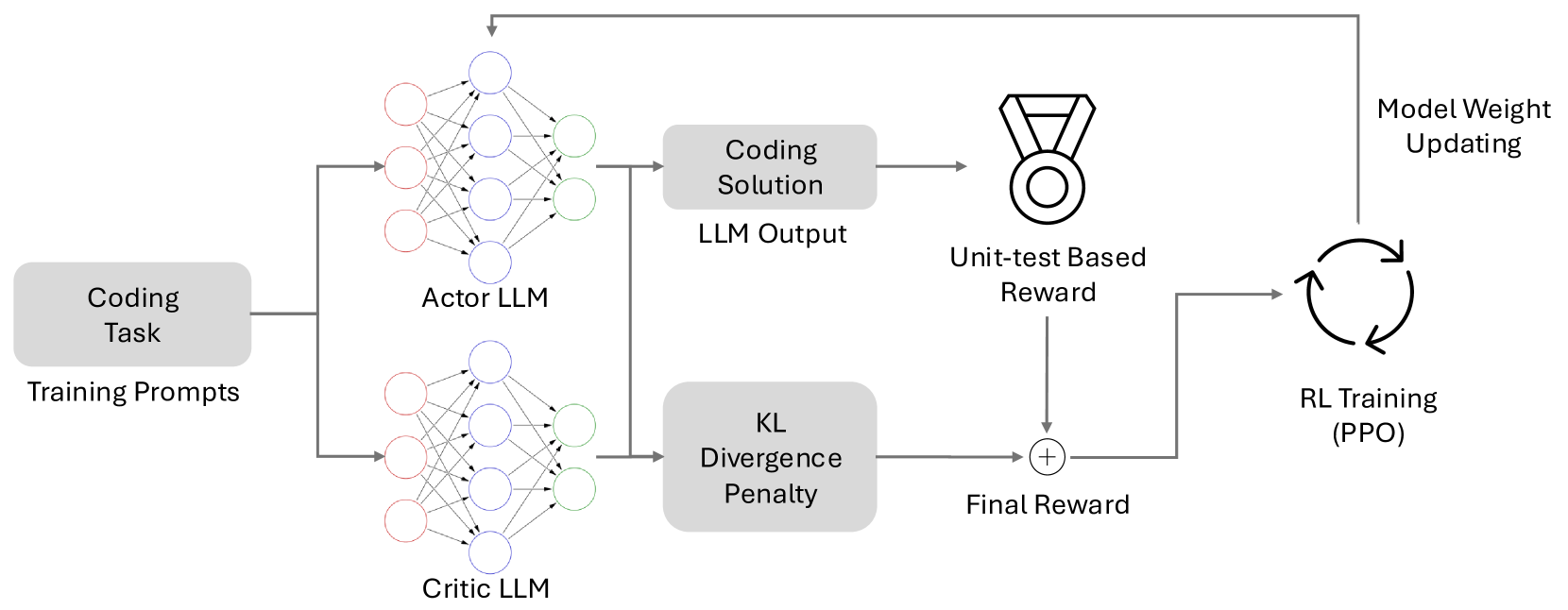
The architecture of ACECode, illustrating the interaction between the Actor LLM, Critic LLM, and the Rewarder.
Evaluation Highlights
- Improves pass@1 (correctness) by 1.84% to 14.51% compared to original CodeLLMs across four state-of-the-art models.
- Reduces runtime in 65% to 72% of generated solutions compared to original CodeLLMs.
- Outperforms the PIE baseline (instruction tuning for efficiency) by up to 14.41% in pass@1 and 11.45% in average execution time.
Breakthrough Assessment
8/10
Significantly advances code generation by successfully optimizing dual conflicting objectives (speed vs. correctness) without requiring inference-time execution or labeled preference datasets.