📝 Paper Summary
Multi-Agent Reinforcement Learning (MARL)
Cooperative AI
This survey paper provides a foundational overview of Centralized Training for Decentralized Execution (CTDE) in cooperative multi-agent reinforcement learning, detailing how agents can leverage global information during training while acting independently at test time.
Core Problem
In cooperative multi-agent settings, agents often have only partial views of the world, making coordination difficult; however, fully centralized control scales poorly with the number of agents.
Why it matters:
- Purely decentralized learning fails to coordinate effectively as agents treat others as part of the environment (non-stationarity)
- Purely centralized execution requires perfect, instantaneous communication at runtime, which is often impossible in real-world robotics or sensor networks
- Standard single-agent RL methods fail in multi-agent settings due to the moving target problem where other agents' policies change simultaneously
Concrete Example:
Consider a team of robots in a warehouse (Dec-POMDP). If each robot learns independently (DTE), they might collide or duplicate work because they can't see each other. If a central brain controls them (CTE), the action space grows exponentially (actions^robots), becoming unsolvable. CTDE allows the central brain to teach them during training, so they act intelligently alone later.
Key Novelty
Survey of the CTDE Paradigm
- CTDE assumes a simulator or laboratory setting where extra information (global state, other agents' actions) is available during training but not execution
- Categorizes methods into Value Decomposition (learning local utility functions that sum to a global value) and Centralized Critic (using a global critic to guide local actor policies)
- Provides a formal grounding of the cooperative MARL problem as a Dec-POMDP (Decentralized Partially Observable Markov Decision Process)
Architecture
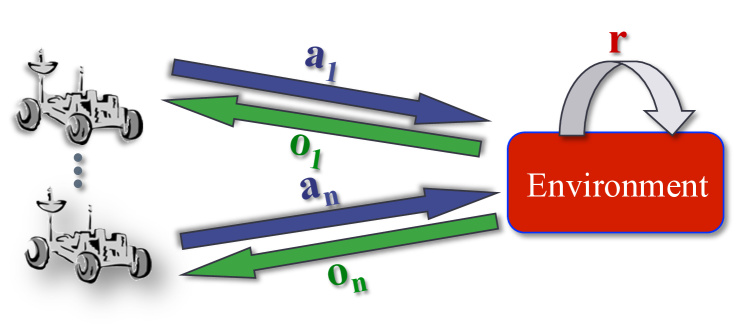
A schematic of the Dec-POMDP setting, illustrating the flow of decentralized execution and centralized rewards.
Evaluation Highlights
- Not applicable — this is a survey/introductory paper without new experimental results
- Qualitatively compares complexity: MDP (P-complete) < POMDP (PSPACE) < Dec-POMDP (NEXP-complete)
- Highlights scalability trade-off: CTE scales exponentially in action/observation space, while CTDE methods attempt to scale linearly or quadratically by factorizing the problem
Breakthrough Assessment
1/10
This is an introductory survey paper explaining existing concepts rather than proposing a new method. It is a high-quality educational resource but not a technical breakthrough.