📝 Paper Summary
Offline Reinforcement Learning
Conditional Sequence Modeling
QT combines a Transformer-based policy for trajectory modeling with a Q-value regularization term to effectively stitch optimal sub-trajectories from sub-optimal data while maintaining stability.
Core Problem
Conditional Sequence Modeling (CSM) methods like Decision Transformer struggle to stitch together optimal trajectories from sub-optimal data because they treat trajectories as whole units rather than leveraging optimal state-level transitions.
Why it matters:
- Standard CSM methods rely on high-return trajectories in the dataset; if the data is sub-optimal, the model cannot infer a policy better than the best demonstration.
- Traditional Dynamic Programming (DP) methods handle stitching well but are unstable in long-horizon or sparse-reward settings, leading to poor convergence.
- Existing hybrid methods (like QDT) often just use Q-values for data augmentation (relabeling returns), which fails to address unmatched return-to-go values during inference.
Concrete Example:
In a maze navigation task (Maze2D), a CSM model might see two sub-optimal paths: A->B (reward 5) and B->C (reward 5). It cannot combine them to form A->B->C (reward 10) if that full trajectory doesn't exist in the data. QT uses Q-learning to value the transition at B, enabling the Transformer to stitch these segments together.
Key Novelty
Q-value Regularized Transformer (QT)
- Integrates a conservative Q-learning objective directly into the Transformer's loss function, rather than just using it for data filtering or relabeling.
- Uses the Transformer's standard prediction loss as a form of implicit policy regularization (keeping the policy close to behavior distribution) while the Q-value term pushes for policy improvement.
- During inference, samples multiple candidate return-to-go tokens and uses the learned Q-function to select the action with the highest predicted value.
Architecture
The training and inference process of QT.
Evaluation Highlights
- +85% improvement over Decision Transformer (DT) on the AntMaze-Large-Diverse task (score 53.3 vs 0.0), a challenging sparse-reward environment.
- Achieves state-of-the-art average score of 129.6 on the Pen-Human Adroit task, significantly outperforming CQL (37.5) and IQL (71.5).
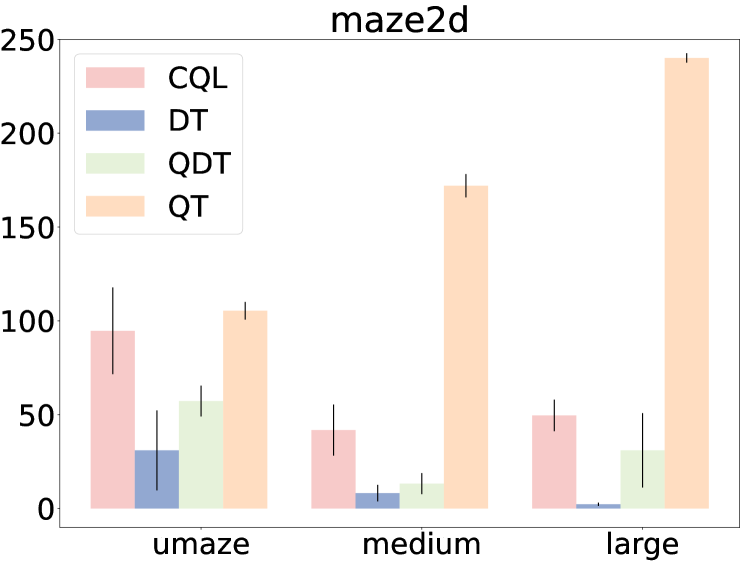
- Consistently surpasses pure Q-learning methods (CQL, IQL) and sequence modeling methods (DT) across Maze2D stitching tasks, achieving an average score of 172.5 vs 62.0 (CQL) and 13.8 (DT).
Breakthrough Assessment
8/10
Significantly improves upon Decision Transformer by solving its primary weakness (stitching) without losing its benefits in sparse-reward settings. The results on AntMaze and Adroit are exceptionally strong compared to robust baselines.