📝 Paper Summary
Deep Reinforcement Learning (RL)
Neural Network Pruning
Sparse Neural Networks
Gradual magnitude pruning enables value-based RL agents to scale effectively with network size, achieving significant performance gains with only a small fraction of the original parameters.
Core Problem
Deep RL agents struggle to utilize parameters effectively; simply scaling up network size often leads to performance degradation or instability, unlike in supervised learning.
Why it matters:
- Current deep RL methods under-utilize network parameters (dormant neurons), wasting computational resources.
- Scaling laws (getting better performance just by making networks bigger) have been difficult to replicate in RL due to instability and overfitting.
- Standard dense architectures often hit a performance ceiling or degrade when width is increased.
Concrete Example:
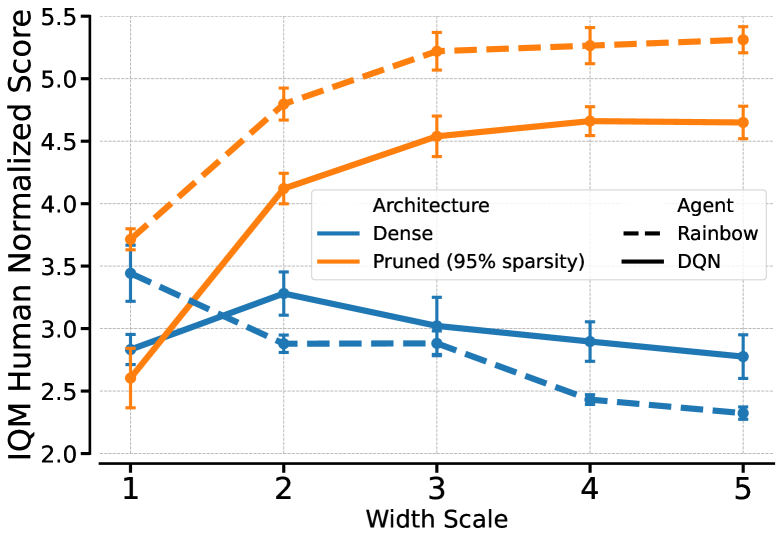
When a standard Rainbow agent's network width is increased by a factor of 4, its performance on Atari games drops significantly compared to the base width. In contrast, the pruned version's performance keeps climbing.
Key Novelty
Gradual Magnitude Pruning as a Scaling Enabler for RL
- Apply gradual magnitude pruning to large, dense networks during training, removing weights with low magnitude until a high sparsity target (e.g., 95%) is reached.
- Unlike dense networks which degrade when scaled up, pruned networks in RL monotonically improve as the base network size increases.
- This technique works as a general 'drop-in' improvement for value-based methods (DQN, Rainbow, IQN) and offline RL (CQL), effectively acting like a dynamic architecture search.
Architecture
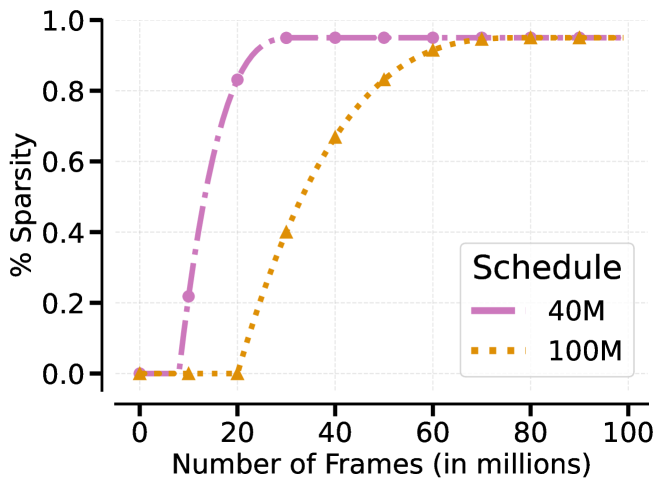
The polynomial schedule for sparsity over training steps.
Evaluation Highlights
- +60% (DQN) and +50% (Rainbow) improvement in Human Normalized Score over standard dense baselines on Atari 100k benchmarks when using pruned, scaled networks.
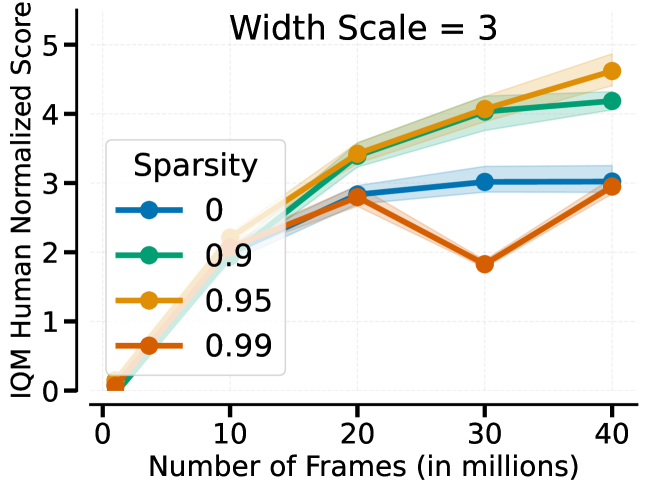
- Pruning maintains performance with only 1% of parameters (99% sparsity) and achieves significant gains at 95% sparsity compared to dense baselines.
- In offline RL (CQL), wider pruned networks achieve +173% improvement over standard dense baselines on Atari datasets.
Breakthrough Assessment
8/10
Provides a compelling solution to the long-standing problem of scaling deep RL networks. The finding that pruning turns scaling from harmful to helpful is a significant reversal of conventional wisdom in RL.