📝 Paper Summary
LLM Reasoning
Reinforcement Learning from Human Feedback (RLHF)
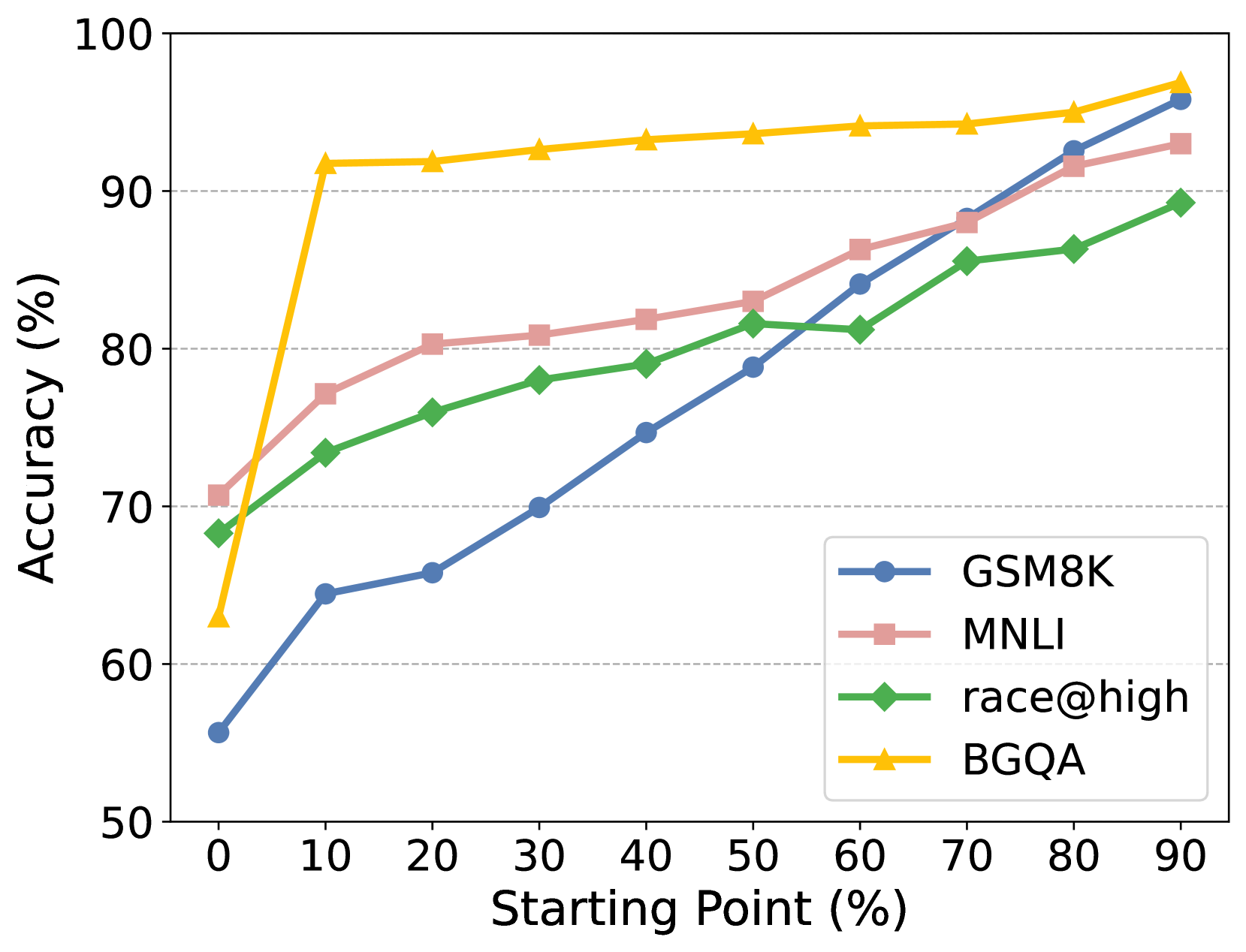
R³ improves LLM reasoning using only sparse outcome supervision by training on reverse sequences—starting near the solution and progressively working backward to the problem statement—creating a curriculum of increasing difficulty.
Core Problem
Reinforcement learning for complex reasoning faces a dilemma: Outcome Supervision (OS) is cheap but provides sparse rewards that fail to guide long reasoning chains, while Process Supervision (PS) offers dense guidance but requires expensive, expert step-by-step annotations.
Why it matters:
- LLMs struggle to optimize long reasoning chains because errors accumulate, and sparse rewards (only at the end) make it hard to identify which specific intermediate step caused failure
- Gathering step-by-step human annotations for Process Supervision is prohibitively expensive and hard to scale compared to just collecting final answers
- Existing RL methods often result in aimless exploration when the search space is large
Concrete Example:
In a multi-step math problem requiring 5 reasoning steps, a standard RL model starting from scratch might wander aimlessly and rarely hit the correct final answer (reward 0). Because it rarely succeeds, it learns nothing. R³ starts the model at step 4 (given the ground truth for steps 1-3), making it easy to find the answer and get a reward, then gradually moves the start point back to step 3, 2, etc.
Key Novelty
Reverse Curriculum Reinforcement Learning (R³)
- Instead of generating the full reasoning chain from scratch, the model starts training from intermediate states sampled from a correct demonstration
- The starting point progressively slides from the end of the demonstration (near the solution) to the beginning (the original question)
- This creates a curriculum where the model first solves 'easy' short-horizon completions before attempting full-horizon reasoning, providing dense-like signals using only outcome rewards
Architecture
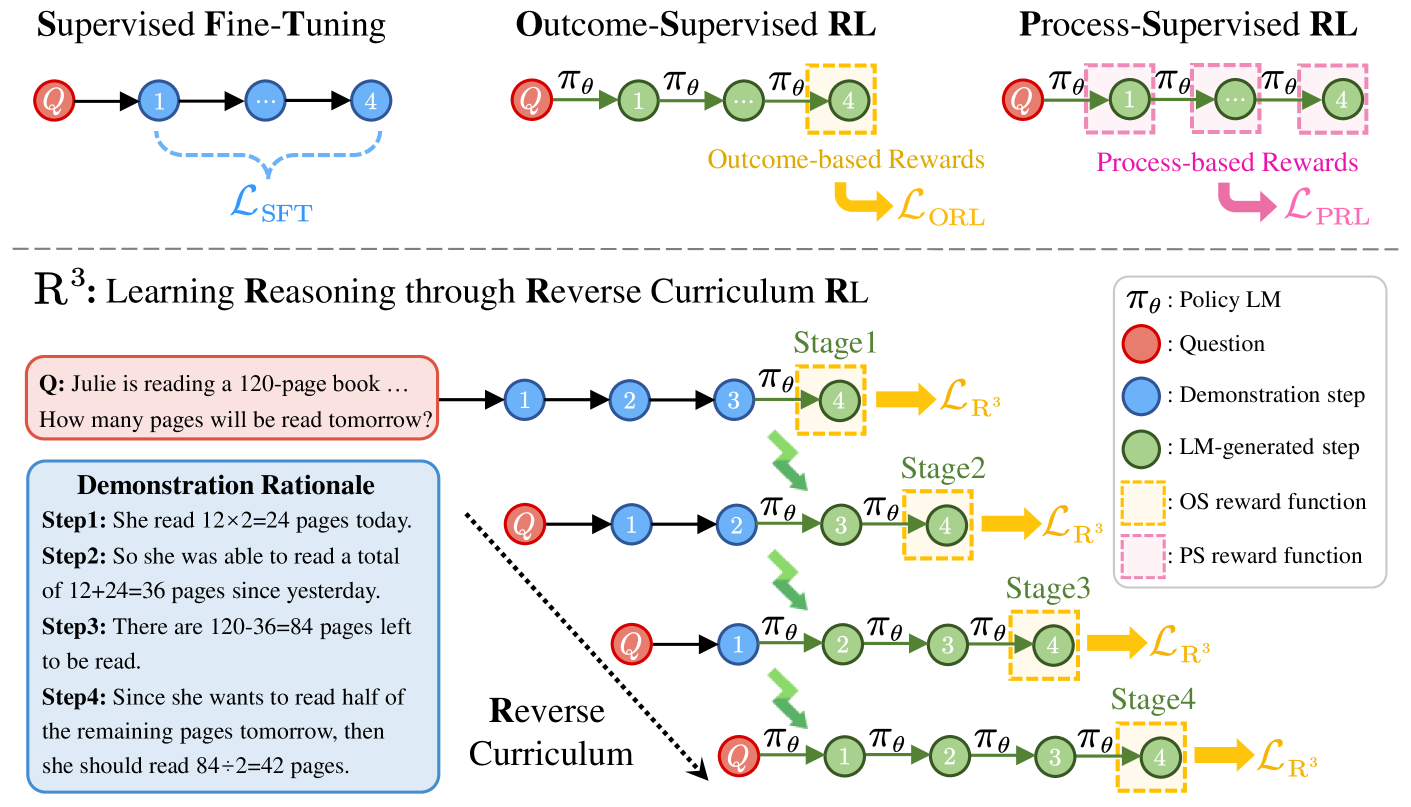
Comparison of Outcome Supervision, Process Supervision, and the proposed R³ method.
Evaluation Highlights
- Outperforms RL baseline (standard PPO) by 4.1 points on average across eight reasoning tasks using Llama2-7B
- Surpasses Supervised Fine-Tuning (SFT) baseline by 11.4 points on average for program-based reasoning on GSM8K
- CodeLlama-7B trained with R³ achieves comparable performance to much larger or closed-source models (like GPT-3.5-Turbo) on math tasks without using extra annotated data
Breakthrough Assessment
8/10
Elegantly solves the sparse reward problem in reasoning without expensive process labels. The 'reverse curriculum' analogy from robotics is successfully applied to LLMs with significant empirical gains.