📝 Paper Summary
Offline Reinforcement Learning
Data Augmentation
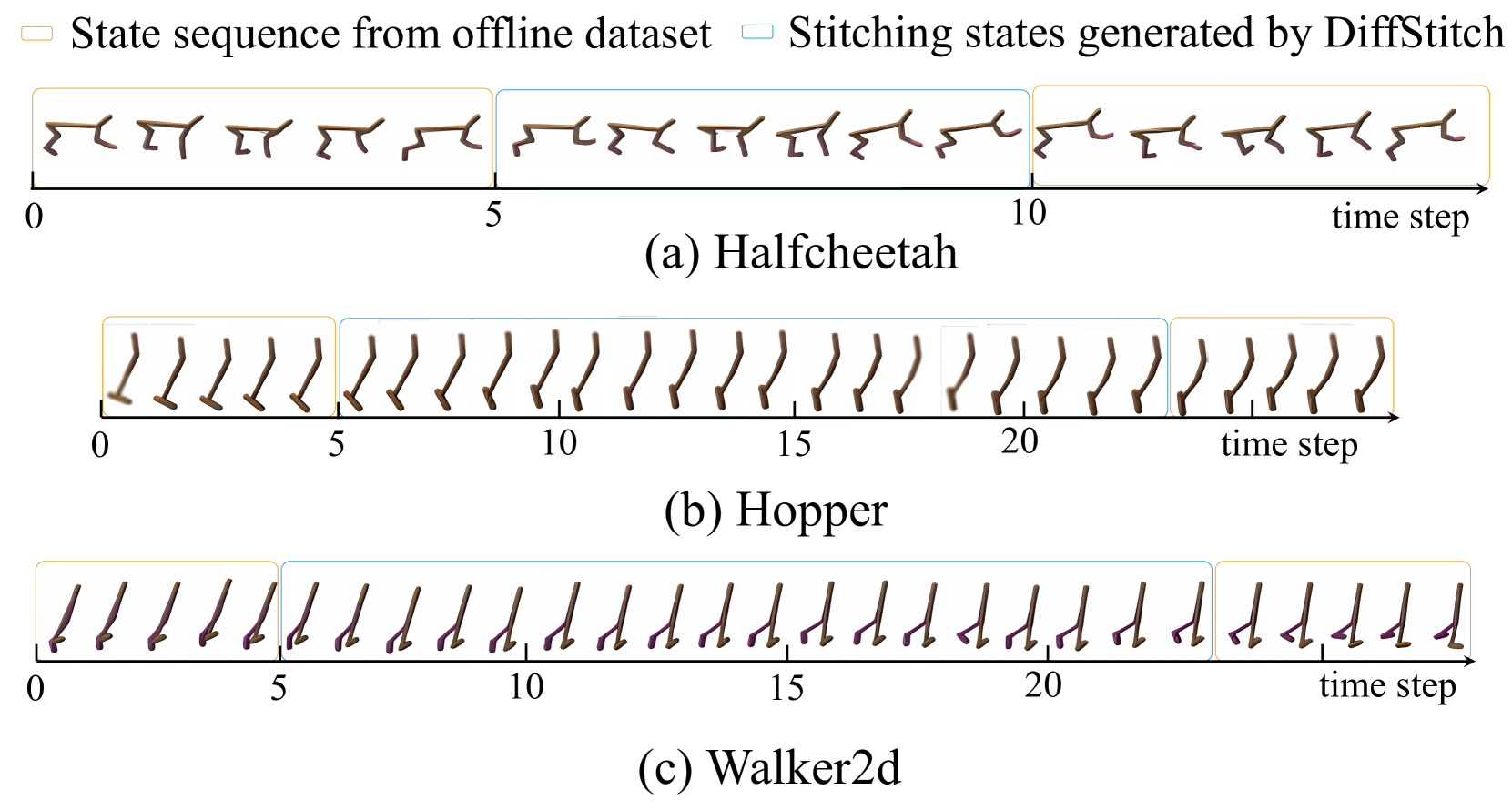
DiffStitch augments offline RL datasets by using diffusion models to generate realistic transition sub-trajectories that stitch low-reward trajectories to high-reward ones, enabling agents to learn paths to optimal regions.
Core Problem
Offline RL datasets often lack optimal trajectories or have disjoint low-reward and high-reward regions, preventing agents from learning how to transit to high-reward states.
Why it matters:
- Offline datasets in real-world scenarios (healthcare, autonomous driving) are often suboptimal and fragmented, limiting policy performance.
- Existing augmentation methods generate short random branches without a target, failing to connect the agent to high-reward regions effectively.
- Naive stitching (masking and filling) often creates physically impossible transitions because it cannot determine the correct number of time steps between disjoint states.
Concrete Example:
Consider a navigation task where one trajectory starts at S but gets low reward, and another disjoint trajectory ends at goal G with high reward. A standard offline RL agent cannot learn to go S→G because no data connects them. Existing augmentations might branch out from S randomly but never hit the specific path to G.
Key Novelty
Diffusion-based Trajectory Stitching (DiffStitch)
- Systematically connects any two trajectories (e.g., a low-reward start and high-reward end) by generating a bridging sub-trajectory.
- Uses a 'step estimation' module to first predict exactly how many time steps are needed to transit between two disjoint states, ensuring temporal consistency.
- Generates the bridging states using a diffusion model conditioned on the estimated steps, then fills in actions and rewards with inverse dynamics models.
Architecture
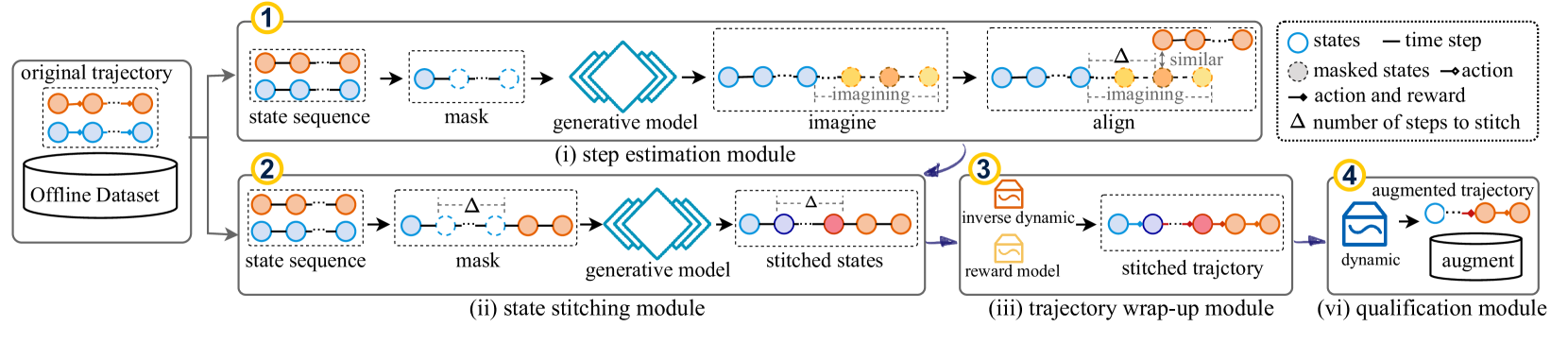
The complete DiffStitch pipeline for generating augmented data.
Evaluation Highlights
- DiffStitch improves IQL performance by +16.8% on average across D4RL locomotion datasets compared to vanilla IQL.
- DiffStitch combined with TD3+BC achieves a score of 109.1 on hopper-medium-expert-v2, outperforming the vanilla baseline of 98.0.
- On the sparse-reward antmaze-umaze-v0 dataset, DiffStitch boosts IQL success rate from 89.5 to 95.3.
Breakthrough Assessment
7/10
Solid contribution to data augmentation for offline RL. The explicit step estimation before generation addresses a key technical hurdle in trajectory stitching (temporal consistency). Improvements are consistent across multiple algorithm types.