📝 Paper Summary
Reward Engineering
Reward Shaping
Inverse Reinforcement Learning
Exploration Strategies
A comprehensive taxonomy and review of reward design techniques in Reinforcement Learning, categorizing methods into engineering and shaping to address sparse rewards, convergence speed, and agent alignment.
Core Problem
Designing effective reward functions is complex and prone to errors; manual specification often leads to sparse rewards, slow convergence, or 'reward hacking' where agents exploit loopholes.
Why it matters:
- Sparse or delayed rewards in complex environments (e.g., robotics) make learning inefficient or impossible without guidance
- Misaligned reward functions can cause agents to learn dangerous or unintended behaviors (reward hacking)
- The literature on reward design is fragmented, lacking a unified framework to categorize engineering and shaping techniques
Concrete Example:
In a grid-world navigation task, a simple reward function (+10 at goal, -1 elsewhere) may be too sparse, causing the agent to wander aimlessly. Without reward shaping (e.g., adding a potential function based on distance to goal), the agent struggles to find the target efficiently.
Key Novelty
Unified Taxonomy of Reward Design
- Distinguishes between Reward Engineering (creating the function from scratch) and Reward Shaping (modifying existing functions for efficiency)
- Integrates diverse methodologies—including Potential-Based Reward Shaping (PBRS), Inverse Reward Design (IRD), and exploration bonuses—into a single coherent framework
- Analyzes the role of reward design in bridging the 'Sim-to-Real' gap in robotics, contrasting scalar vs. vector reward perspectives
Architecture
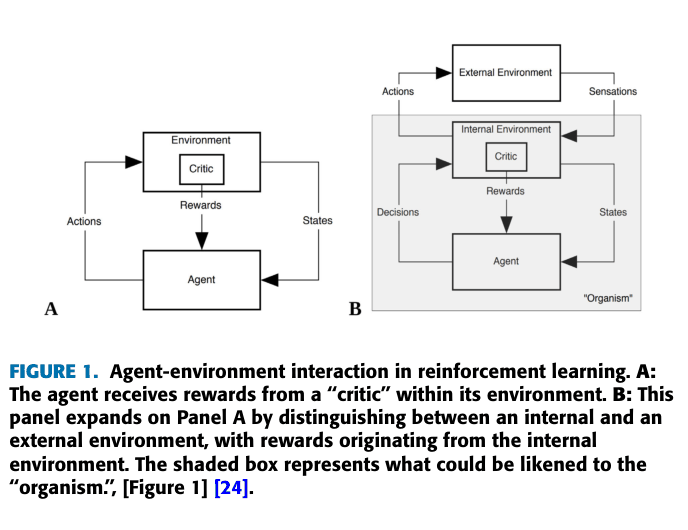
Conceptual diagram distinguishing between extrinsic and intrinsic motivation in RL agents.
Evaluation Highlights
- PBRS (Potential-Based Reward Shaping) is highlighted as a key technique that accelerates learning while mathematically guaranteeing the optimal policy remains unchanged
- Inverse Reward Design (IRD) is identified as a crucial method for safety, treating proxy rewards as evidence rather than ground truth to avoid reward hacking
- Exploration-guided shaping methods (e.g., VIME, RUNE) are shown to effectively handle sparse reward environments by adding intrinsic motivation
Breakthrough Assessment
7/10
While a survey paper, it provides a necessary consolidation of a fragmented field. The taxonomy is thorough and addresses the critical bottleneck of reward specification in modern RL.