📝 Paper Summary
Offline Reinforcement Learning
LLM Reasoning
Value-Guided Search
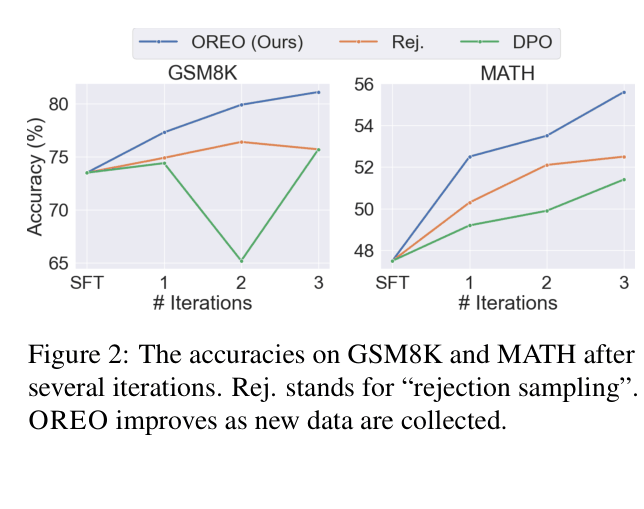
OREO improves LLM reasoning by jointly training a policy and a value function to satisfy the soft Bellman equation, enabling fine-grained credit assignment from sparse rewards without paired preference data.
Core Problem
Current offline alignment methods like DPO require paired preference data (scarce in reasoning) and struggle with credit assignment because they treat entire trajectories uniformly, while rejection sampling ignores valuable failure data.
Why it matters:
- Training LLMs with online RL (like PPO) is prohibitively expensive for most users due to data generation costs
- Reasoning tasks typically provide only sparse terminal rewards (correct/incorrect), making it difficult to identify which specific step caused an error
- Discarding incorrect trajectories (as in Rejection Sampling) wastes significant information about failure modes that could improve robustness
Concrete Example:
In a math problem, a model might make a small calculation error in step 2 but fail at the final step 10. DPO penalizes the entire sequence equally against a correct one. OREO's value function identifies the drop in expected reward specifically at step 2, providing precise feedback.
Key Novelty
Offline REasoning Optimization (OREO)
- Adapts Path Consistency Learning to LLMs by minimizing the difference between the current value and the target value (reward + next state value) at every token step
- Explicitly learns a value function alongside the policy from offline data, allowing the model to estimate expected future rewards for intermediate steps even when only terminal rewards are known
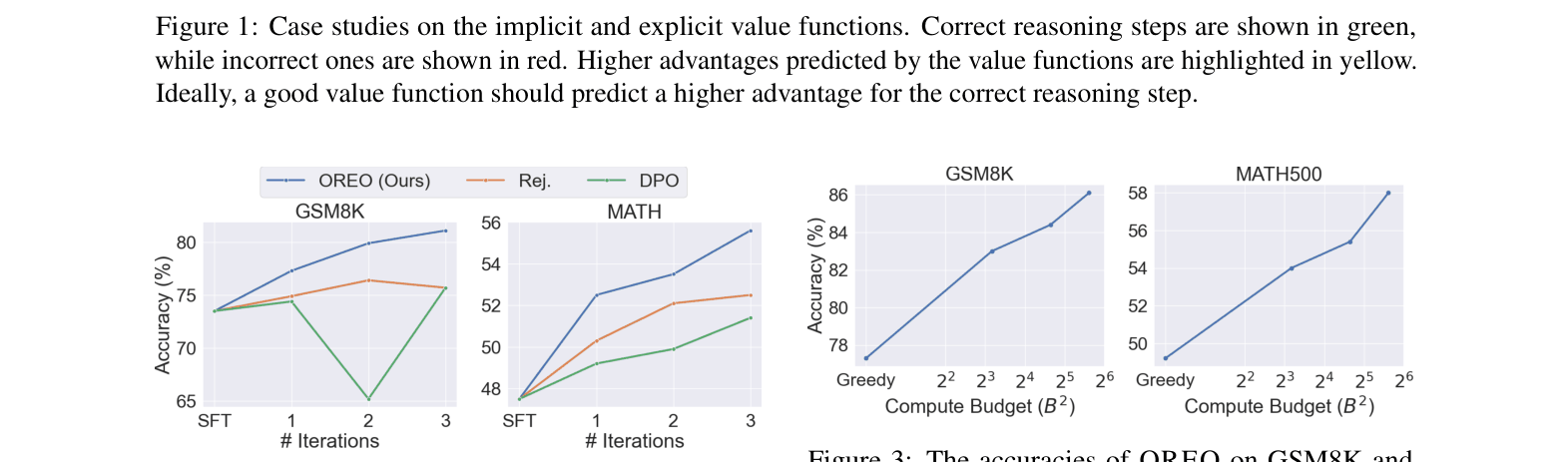
- Uses the learned value function 'for free' at test time to guide beam search or select the best-of-K actions, filtering out incorrect reasoning paths early
Architecture
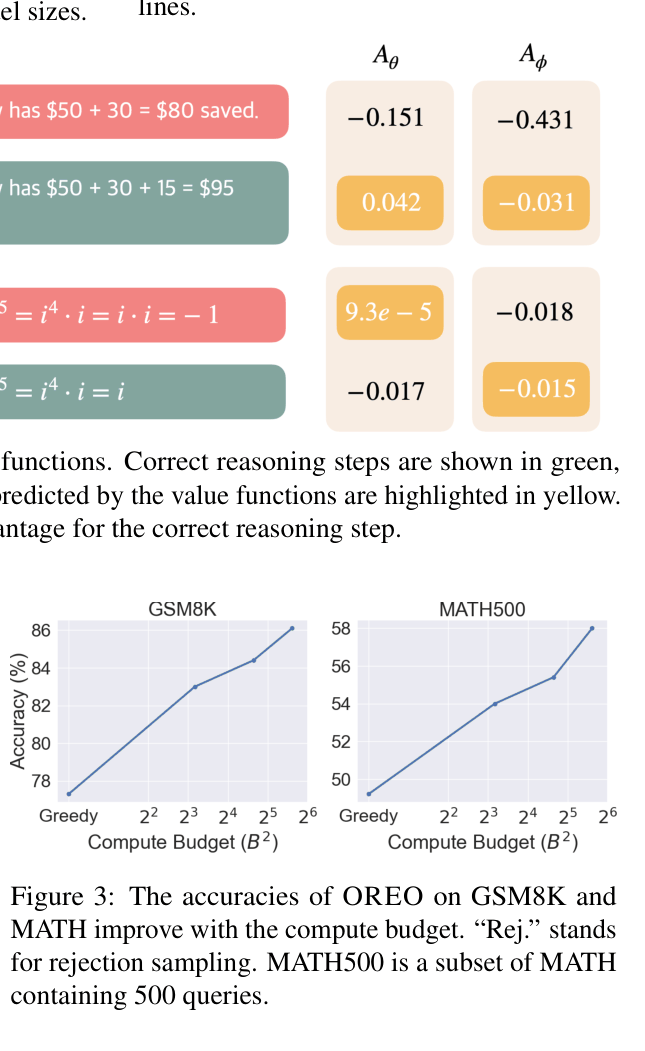
Comparison of implicit (policy-based) vs explicit (OREO) value functions on math problems.
Evaluation Highlights
- Outperforms Rejection Sampling by +10.4% success rate on ALFWorld (Unseen split) using MiniCPM-2B, demonstrating superior generalization
- Achieves 52.5% accuracy on MATH with Qwen2.5-Math-1.5B, surpassing DPO (49.2%) and Rejection Sampling (50.3%)
- Test-time beam search guided by the learned value function improves MATH accuracy by 17.9% relative to greedy decoding
Breakthrough Assessment
8/10
Offers a principled theoretical correction to DPO's limitations in reasoning. The method consistently beats strong baselines (Rejection Sampling, DPO) and provides a practically useful value model for inference scaling.