📝 Paper Summary
LLM Alignment
Post-training optimization
This survey systematically categorizes reinforcement learning techniques for LLMs, analyzing the shift from complex reward-model-based methods (RLHF) to direct preference optimization and reasoning-focused self-evolution.
Core Problem
Implementing reinforcement learning for LLMs is highly complex, involving unstable algorithms and reward modeling, and the lack of a comprehensive survey hinders systematic understanding of recent advancements.
Why it matters:
- RL is critical for aligning LLMs with human expectations, producing safer and more helpful responses than supervised fine-tuning alone
- Recent state-of-the-art models like DeepSeek-R1 and Llama 3 rely heavily on RL, yet the techniques (PPO vs. DPO) vary significantly in complexity and stability
- The field is fragmenting between traditional reward-based RL and newer reward-free methods, creating a need for consolidated knowledge
Concrete Example:
A base LLM might generate a mathematically correct but rude or poorly formatted response. Without RL alignment, the model is confined to its pre-training distribution; applying RL (as in DeepSeek-R1) allows it to 'self-evolve' to solve hard reasoning tasks where standard supervised data is scarce.
Key Novelty
Systematic Taxonomy of RL-Enhanced LLMs
- Classifies RL approaches into two main lines: Traditional RL (RLHF/RLAIF with PPO) which requires a separate reward model, and Simplified approaches (DPO/RPO) which optimize preferences directly without a reward model
- Provides a detailed breakdown of the 'Cold Start' to 'Reasoning-Oriented RL' pipeline used by cutting-edge reasoning models like DeepSeek-R1
Architecture
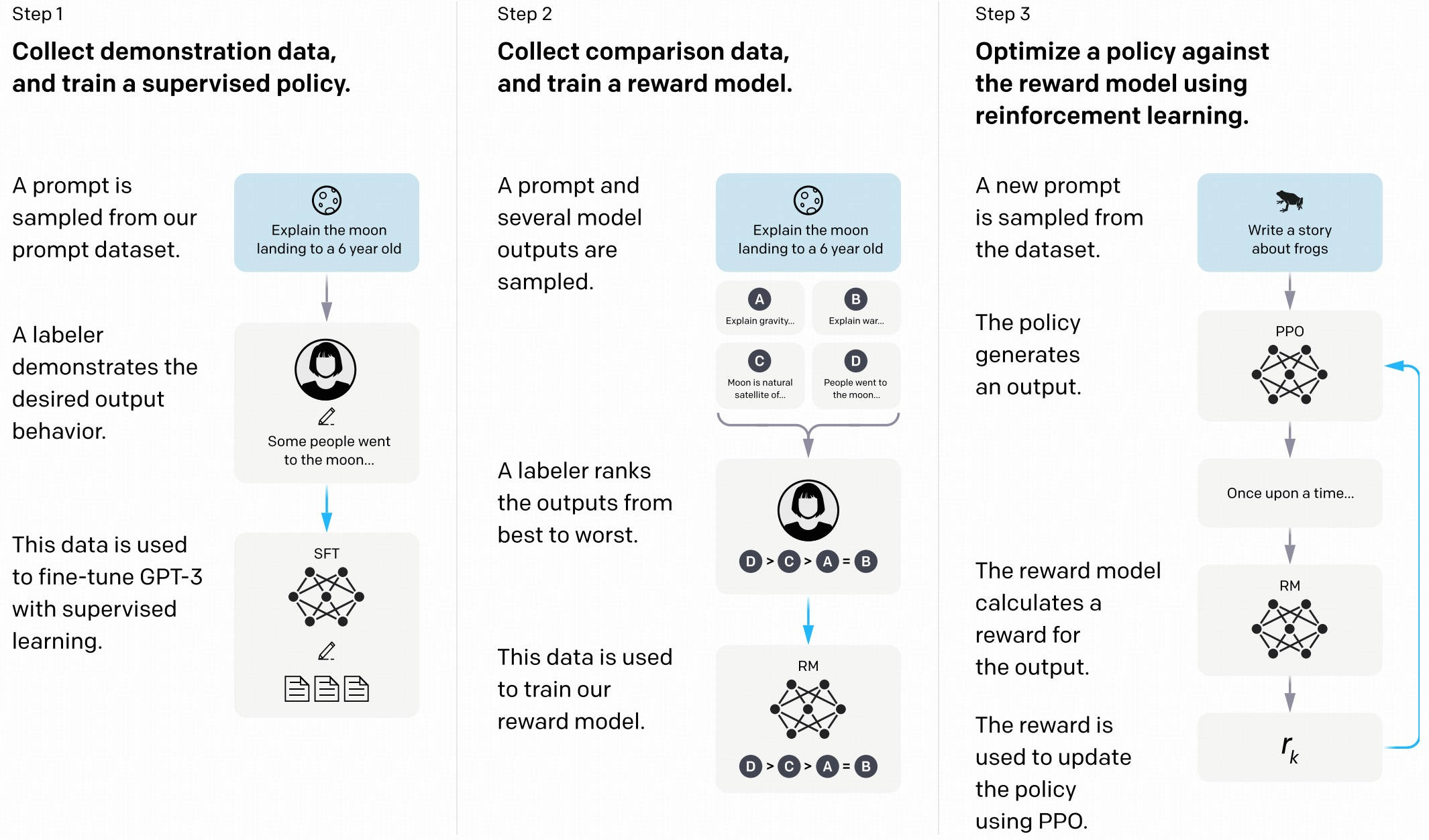
The standard RLHF pipeline for LLMs as proposed by Ouyang et al. (2022)
Evaluation Highlights
- DeepSeek-R1-Zero (RL only) improves pass@1 on AIME 2024 from 15.6% to 71.0%, demonstrating the power of pure RL for reasoning
- DeepSeek-R1 (with majority voting) achieves 86.7% on AIME 2024, matching OpenAI-o1-0912
- Kimi-k1.5 achieves up to 550% improvement on short-context tasks by transferring reasoning capabilities from long-CoT models using Long2Short RL strategies
Breakthrough Assessment
9/10
Timely and comprehensive survey covering the most recent and impactful models (DeepSeek-R1, Llama 3) and effectively categorizing the rapid shift from PPO to DPO and reasoning-based RL.