📝 Paper Summary
Online Reinforcement Learning
Diffusion Policies
QVPO adapts diffusion models for online RL by deriving a Q-weighted variational loss that serves as a tight lower bound for the policy objective, enhanced by novel entropy regularization.
Core Problem
Diffusion models, while expressive, have training objectives (Variational Lower Bound) that do not directly maximize expected return in online RL, and existing adaptations rely on inaccurate Q-function gradients or score matching.
Why it matters:
- Unimodal policies (like Gaussian) limit exploration and performance in complex continuous control tasks.
- Existing diffusion RL methods are mostly offline; online integration is difficult because 'good' actions are not available a priori to train the diffusion model as a generator.
- Methods like DIPO and QSM suffer from gradient inaccuracies or approximation errors, preventing convergence to optimality.
Concrete Example:
In a complex locomotion task, a standard Gaussian policy might get stuck in a local optimum due to limited expressiveness. A standard diffusion model can model complex distributions but doesn't know *which* actions lead to high rewards. DIPO tries to fix this by taking gradient steps on actions, but this relies on a potentially flawed Q-function gradient, leading to suboptimal updates.
Key Novelty
Q-weighted Variational Policy Optimization (QVPO)
- Re-weights the standard diffusion training loss (VLO) using Q-values, mathematically proving this weighted loss is a tight lower bound for the true RL maximization objective.
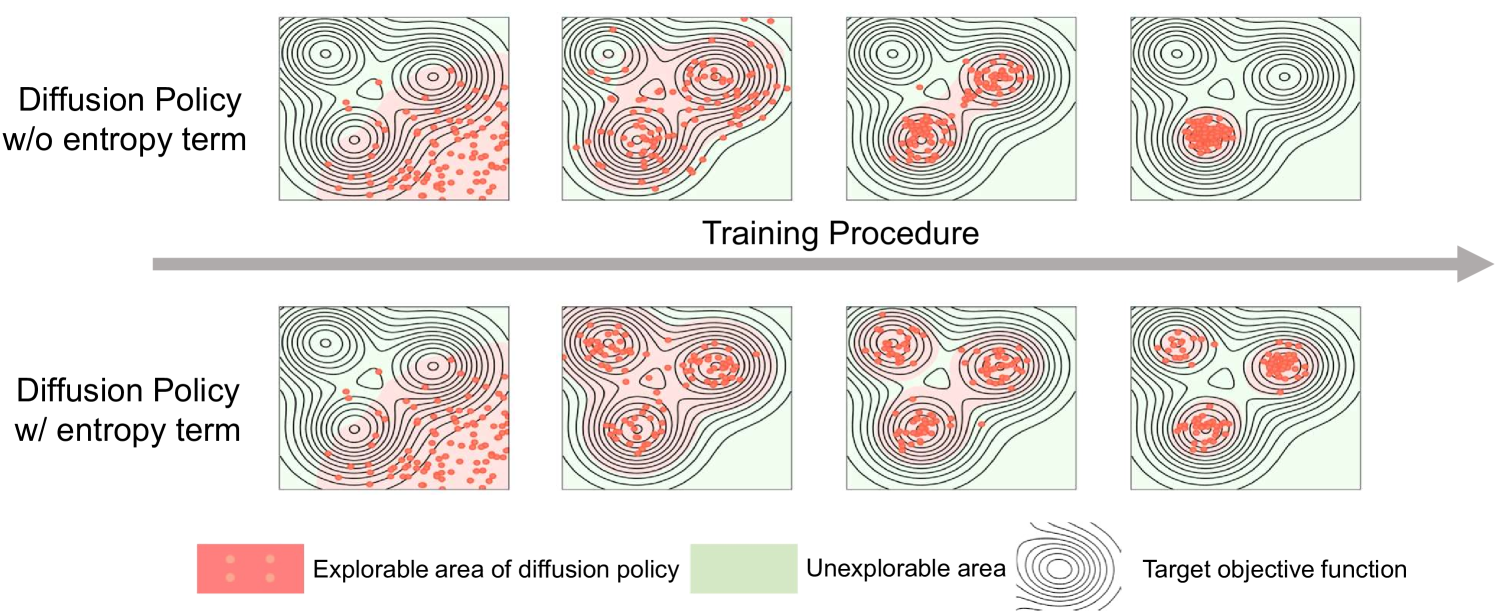
- Introduces a tractable entropy regularization term specifically designed for diffusion policies (where exact likelihood is unknown) to prevent premature convergence.
- Selects the best action from multiple diffusion samples during inference to act as an efficient behavior policy, reducing variance and improving data collection.
Architecture
The overall framework of the QVPO algorithm.
Evaluation Highlights
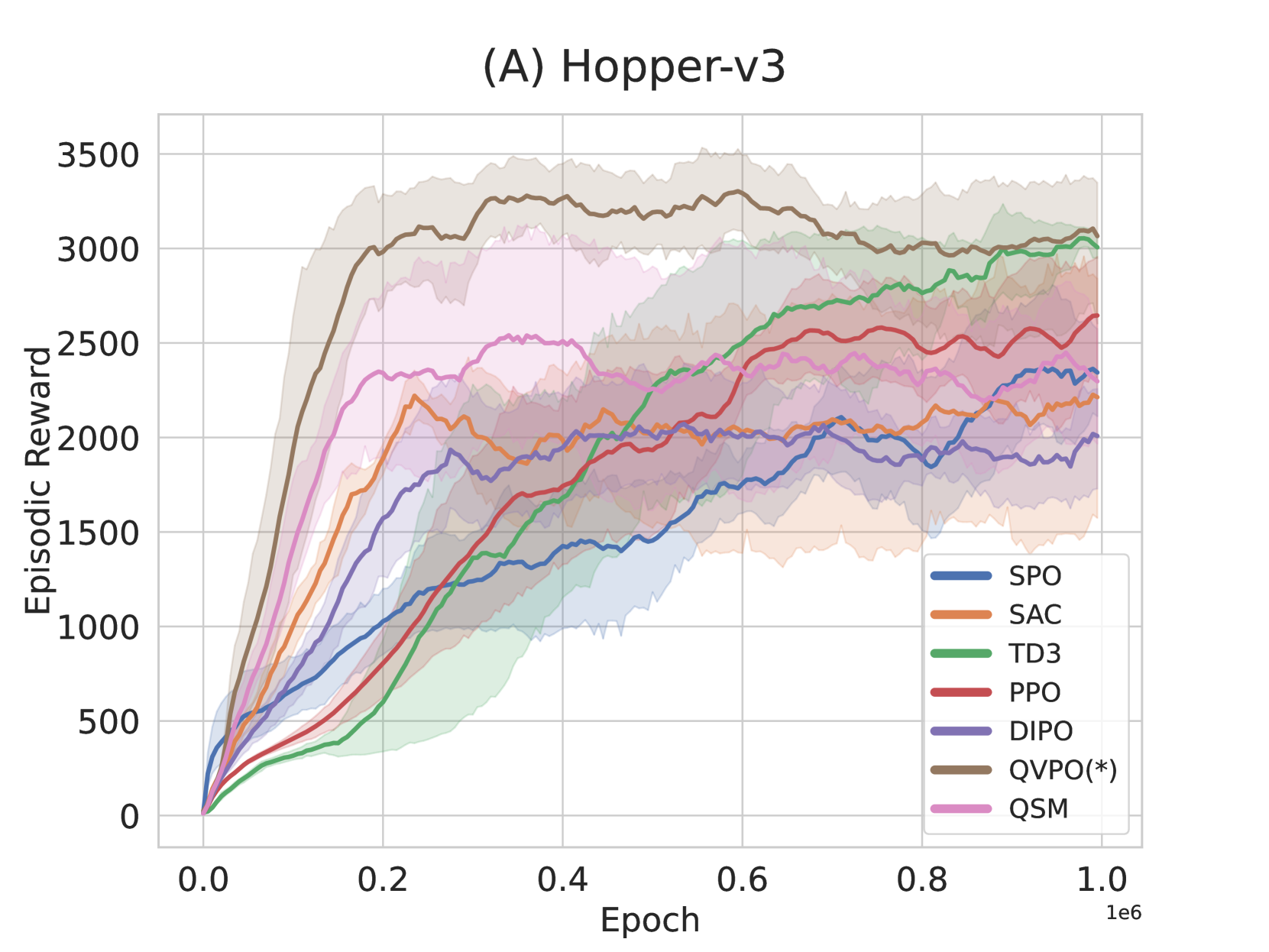
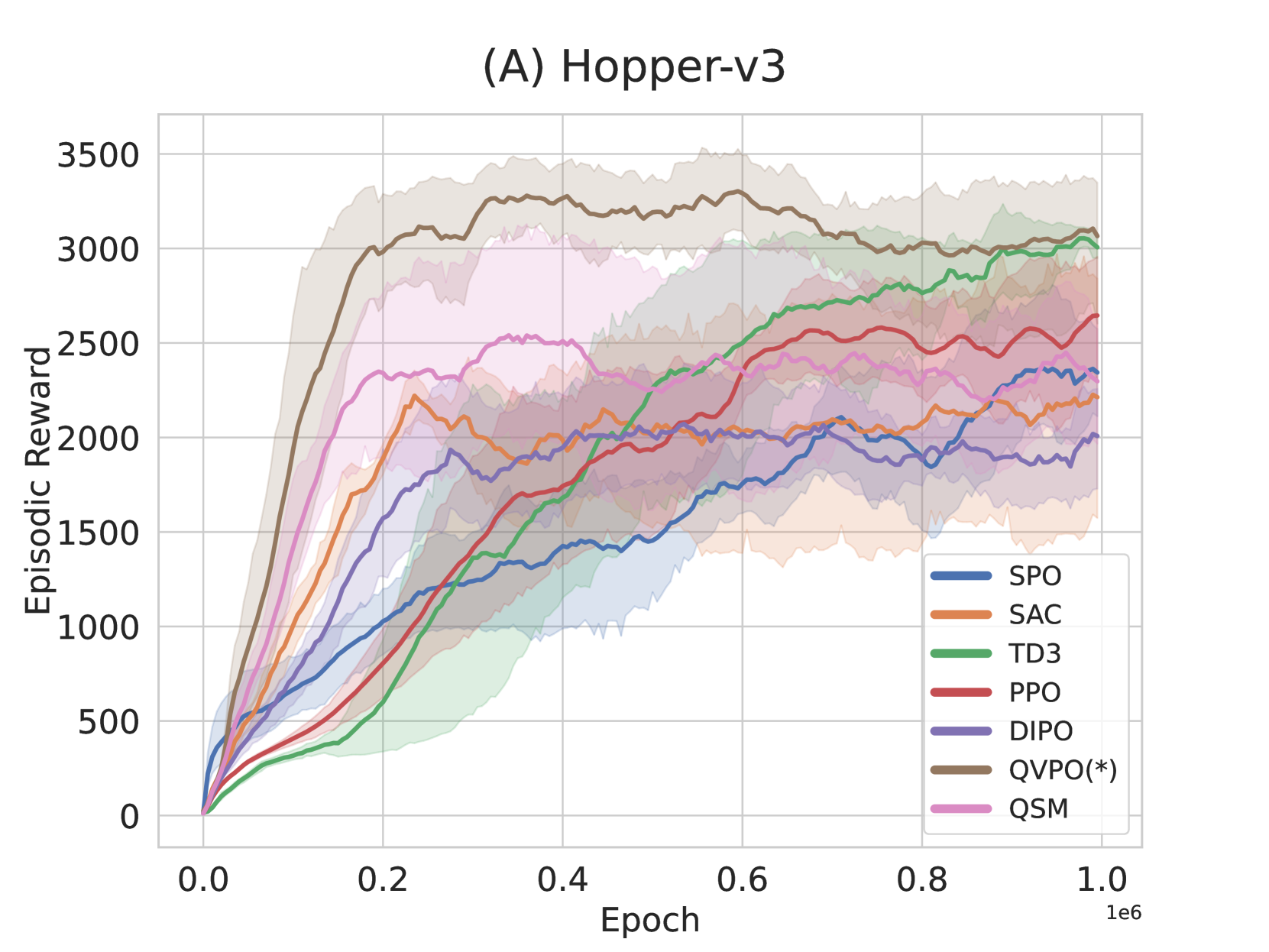
- Achieves state-of-the-art cumulative reward on MuJoCo continuous control benchmarks compared to both traditional (SAC, PPO) and diffusion-based (DIPO, QSM) baselines.
- Demonstrates superior sample efficiency, reaching higher rewards with fewer environment interactions than prior diffusion online RL methods.
- Significantly reduces performance variance compared to standard diffusion policies through the proposed efficient behavior policy mechanism.
Breakthrough Assessment
8/10
Provides a theoretically grounded way to use diffusion models in online RL without relying on ad-hoc gradient guidance, solving a major integration hurdle for expressive policies.