📝 Paper Summary
Reinforcement Learning for Generative Models
Text-to-Image Alignment
The paper presents a scalable reinforcement learning framework for diffusion models that fine-tunes base models on millions of prompts to simultaneously improve human preference, fairness, and compositionality.
Core Problem
Pre-trained text-to-image models suffer from misalignments like poor compositionality, aesthetic mismatch with human preferences, and societal biases due to uncurated web-scale training data.
Why it matters:
- Models often fail to respect complex prompts (e.g., incorrect object relationships), limiting their utility for controllable generation
- Biases in training data lead to stereotypical outputs (e.g., predominantly light-skinned professionals), raising ethical concerns
- Existing alignment methods are either small-scale (optimizing few prompts) or memory-intensive (requiring differentiable rewards), preventing general-purpose improvement
Concrete Example:
When prompted for 'a portrait of a dentist', a standard Stable Diffusion model predominantly generates images of light-skinned individuals, reflecting dataset bias. Similarly, prompts like 'an apple next to an avocado' often result in merged or missing objects due to poor compositional understanding.
Key Novelty
Large-Scale Multi-Objective RL for Diffusion
- Scales RL fine-tuning to millions of diverse prompts (vs. dozens in prior work) using efficient batch-based reward normalization instead of per-prompt tracking
- Introduces distribution-based rewards (Statistical Parity) computed over minibatches to enforce diversity and fairness across the model's output distribution
- Jointly optimizes conflicting objectives (aesthetics, fairness, compositionality) in a single training run, mitigating the 'alignment tax' where improving one metric degrades others
Architecture

The RL training loop treating diffusion as an MDP
Evaluation Highlights
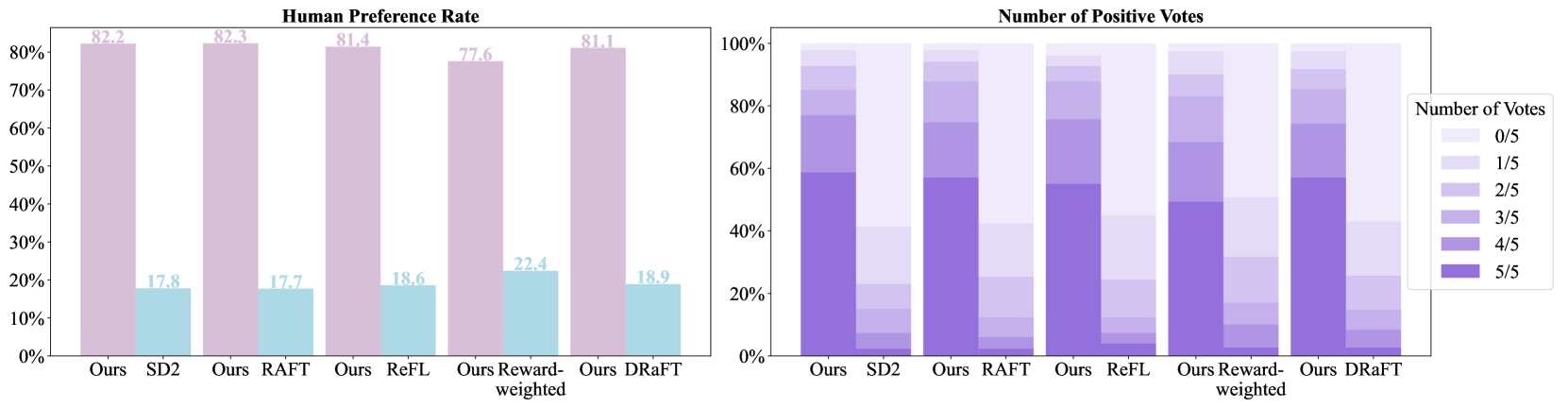
- Fine-tuned model generates samples preferred by humans 80.3% of the time over the base Stable Diffusion v2 model
- Outperforms state-of-the-art alignment methods (RAFT, ReFL) on PartiPrompts benchmark, achieving highest Human Preference and Aesthetic Scores
- Significantly reduces skintone bias: generates balanced demographics for occupations like 'dentist' where the base model is heavily biased
Breakthrough Assessment
8/10
Demonstrates the first successful application of RL to diffusion models at a scale comparable to pre-training (millions of prompts), effectively solving multi-objective alignment problems that previously required separate models.