📝 Paper Summary
Code Generation
Reinforcement Learning from Compiler Feedback
StepCoder improves code generation by decomposing difficult exploration into a curriculum of easier code completion sub-tasks and optimizing models using only executed code segments.
Core Problem
RL for code generation struggles with exploration due to long sequences and sparse rewards, and optimization is noisy because unit test feedback is applied to the entire sequence, including unexecuted code.
Why it matters:
- Complex human requirements require long code sequences, making the search space for RL exponentially large and exploration difficult
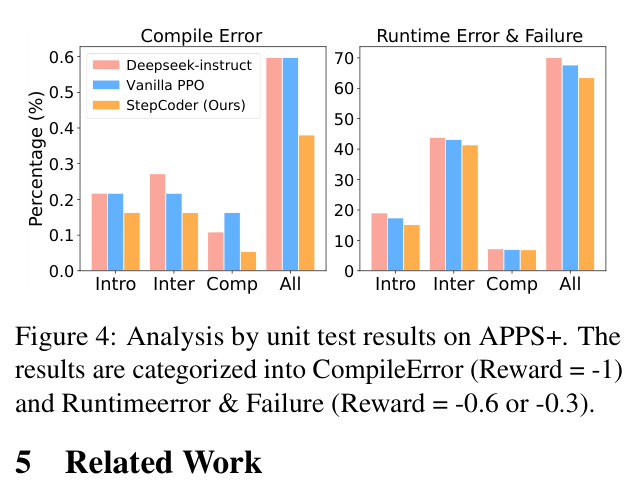
- Standard RL updates the policy for the entire generated code, but unexecuted branches (e.g., inside an un-triggered 'if') are irrelevant to the reward, causing imprecise optimization
- Existing datasets like APPS contain noise (syntax errors, missing outputs) that hampers effective RL training
Concrete Example:
In a solution with an `if-else` block, if a specific unit test input only triggers the `if` branch, the `else` branch is unexecuted. Standard RL rewards/punishes the entire code based on the result, incorrectly updating the policy for the unexecuted `else` branch.
Key Novelty
StepCoder (CCCS + FGO)
- CCCS (Curriculum of Code Completion Subtasks): Breaks generation into a reverse curriculum, starting exploration from the end of the solution (easy completion) and gradually moving the start point backward to the beginning.
- FGO (Fine-Grained Optimization): Dynamically masks unexecuted code tokens during the RL update step so the model is only reinforced on code that actually contributed to the unit test result.
Architecture
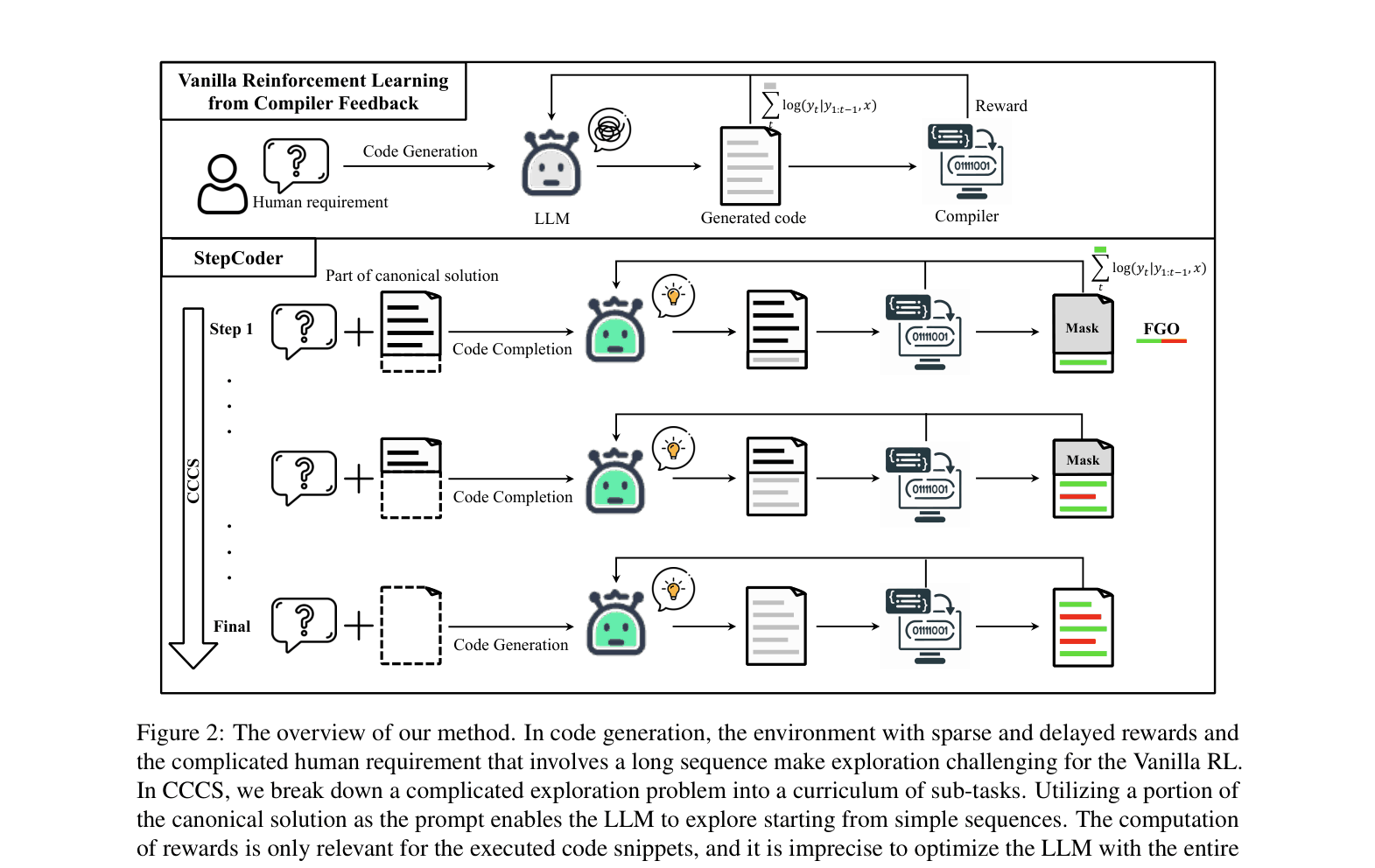
The StepCoder framework overview illustrating the CCCS and FGO components within the RL loop.
Evaluation Highlights
- +4.4% pass@1 improvement on APPS+ Overall compared to Vanilla PPO using the same DeepSeek-Coder-Instruct-6.7B backbone
- +1.7% pass@1 on MBPP compared to the Supervised Fine-Tuned (SFT) baseline, achieving 67.0%
- Achieves 59.7% pass@1 on APPS+ Introductory level, outperforming state-of-the-art RL methods like RLTF (55.1%) and PPOCoder (54.4%)
Breakthrough Assessment
7/10
Solid methodological improvements for RL exploration and optimization in code gen. The dataset contribution (APPS+) is valuable. Results are consistent but incremental over strong base models.