📝 Paper Summary
Robotic Manipulation
Real-World Reinforcement Learning
Human-in-the-Loop Learning
HIL-SERL integrates sample-efficient off-policy RL with human corrections and a pretrained visual backbone to master complex, high-precision, and dynamic robotic manipulation tasks in the real world within hours.
Core Problem
Real-world robotic RL struggles with sample inefficiency, optimization instability, and the difficulty of acquiring complex dexterous skills (like dynamic or dual-arm tasks) without extensive engineering or simulation.
Why it matters:
- Achieving human-level dexterity in robotics remains an unsolved grand challenge
- Current methods often rely on brittle hand-designed controllers or extensive simulation-to-reality transfer which fails on contact-rich tasks
- Pure imitation learning often fails to recover from distribution drift, while pure RL is too slow for real hardware
Concrete Example:
In a dynamic Jenga block whipping task, an imitation learning agent might learn the initial whip motion but fail to adjust if the block doesn't dislodge immediately, whereas HIL-SERL learns to retry or adjust force based on visual feedback.
Key Novelty
Human-in-the-Loop Sample-Efficient Robotic Reinforcement Learning (HIL-SERL)
- Combines off-policy RL (RLPD) with online human corrections: a human operator intervenes when the robot struggles, and these 'correction' trajectories are treated as high-value training data
- Uses a 'relative' proprioceptive state space where the target is virtualized relative to the end-effector, allowing the policy to succeed even if objects move during execution
- Separates continuous arm control from discrete gripper control (using a separate DQN critic for grasping) to simplify the learning of hybrid action spaces
Architecture
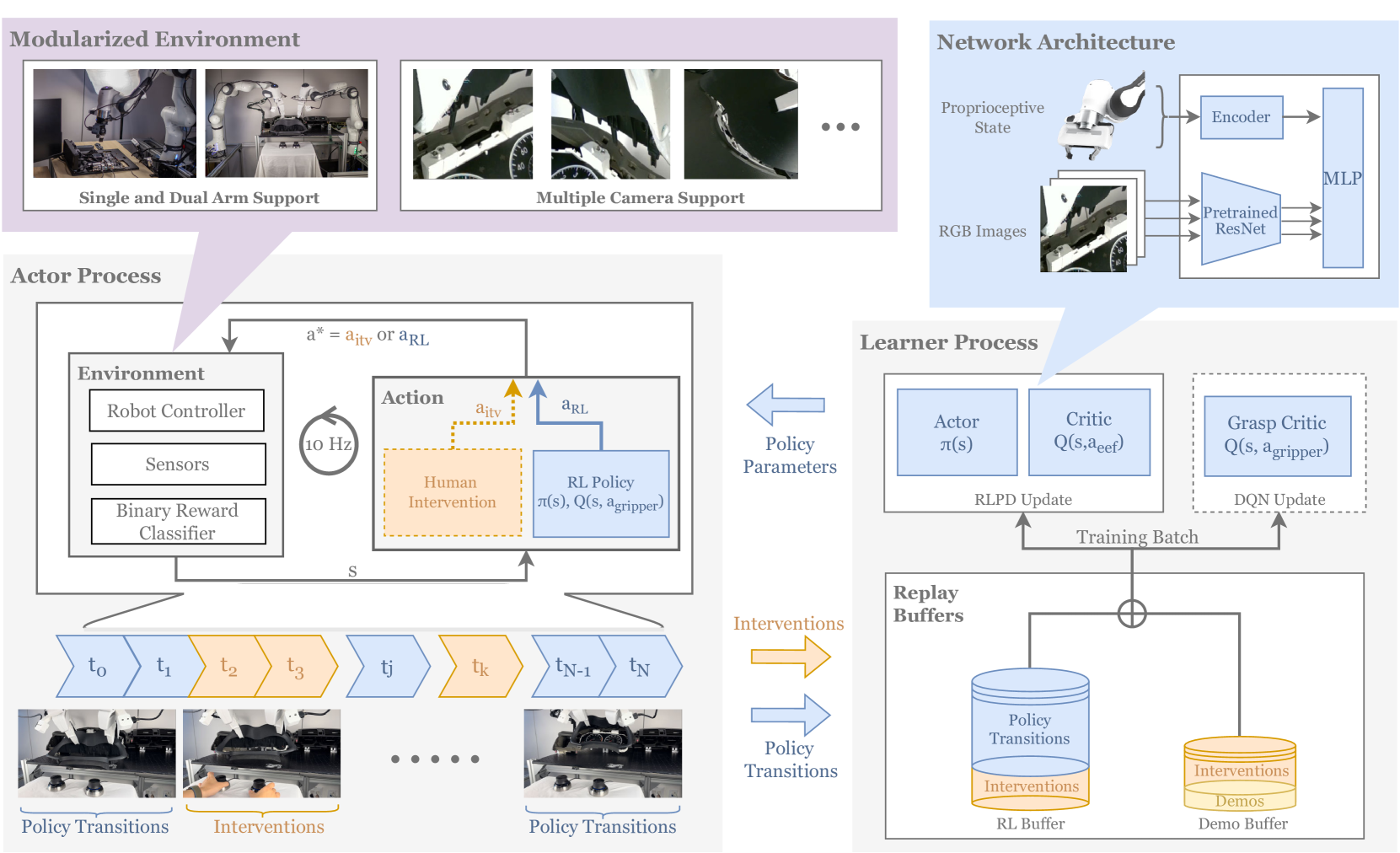
The HIL-SERL system architecture, illustrating the flow of data between the robot, human operator, and learning algorithm.
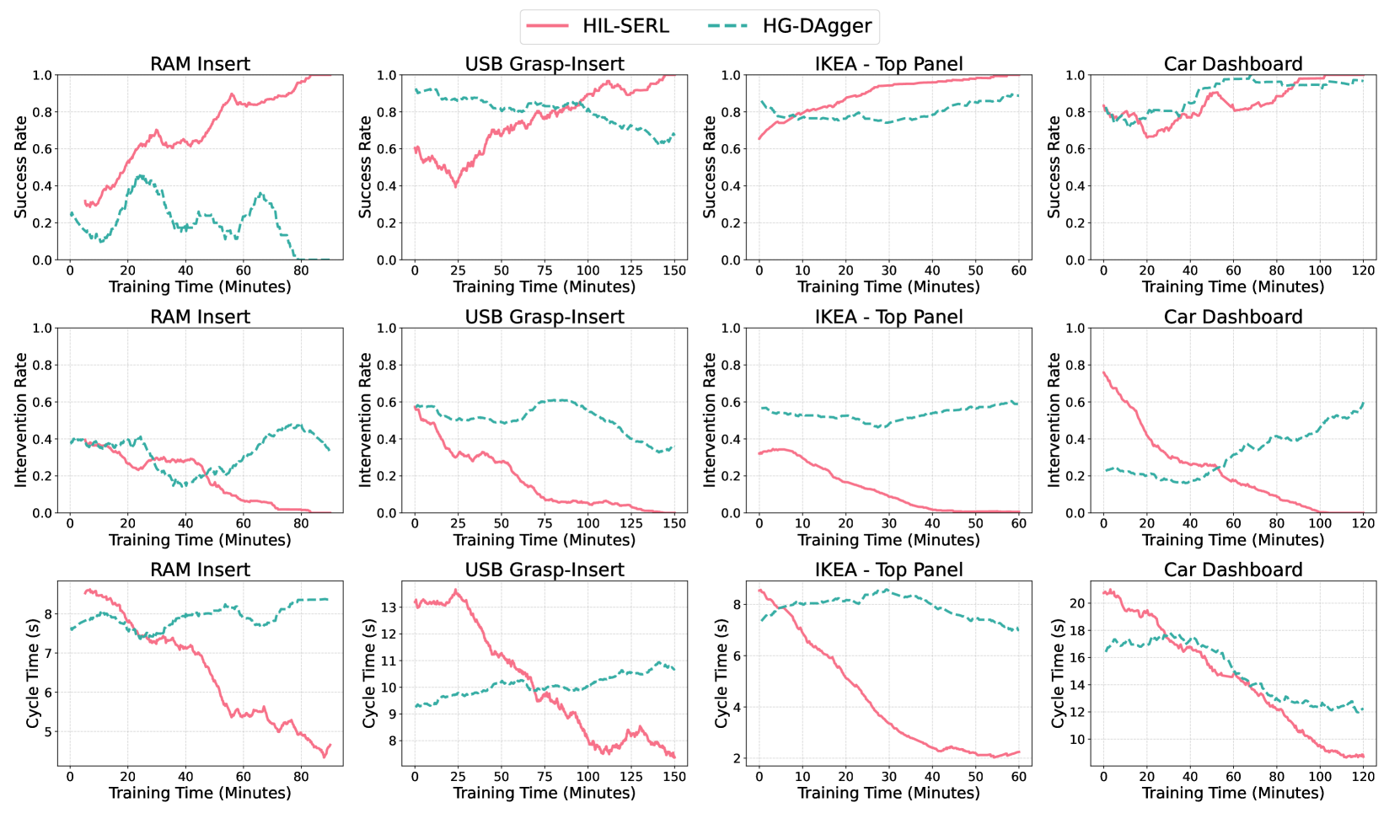
Evaluation Highlights
- Achieves near-perfect success rates on complex tasks like PCB assembly and dynamic pan flipping within 1 to 2.5 hours of real-world training
- Outperforms imitation learning baselines by an average of 101% in success rate given the same amount of human data
- Executes tasks 1.8x faster on average compared to imitation learning baselines due to RL's ability to optimize for cycle time
Breakthrough Assessment
9/10
Demonstrates RL solving tasks previously considered infeasible for real-world learning (e.g., dual-arm belt assembly, Jenga whipping) with extremely short training times. A significant step forward for practical robotic learning.