📝 Paper Summary
Robotic Manipulation
Reinforcement Learning (RL)
SERL provides a complete, high-quality open-source software stack for real-world robotic reinforcement learning that achieves high success rates on contact-rich tasks in under an hour of training.
Core Problem
Despite algorithmic advances, real-world robotic RL remains inaccessible due to the difficulty of implementing effective reward functions, resets, safe controllers, and efficient learning loops.
Why it matters:
- Implementation details often impact performance more than the choice of algorithm, creating a high barrier to entry for practitioners
- Real-world training requires handling safety, resets, and physical contact, which simulation-focused libraries ignore
- Widespread adoption of robotic RL is bottlenecked by the lack of a standardized, high-quality full-stack implementation
Concrete Example:
In a PCB assembly task, standard controllers might be too stiff (bending pins) or too compliant (failing to insert). Without SERL's impedance controller design and reward infrastructure, a robot fails to learn precise insertion even after extensive training.
Key Novelty
Full-Stack Vertical Integration for Robotic RL
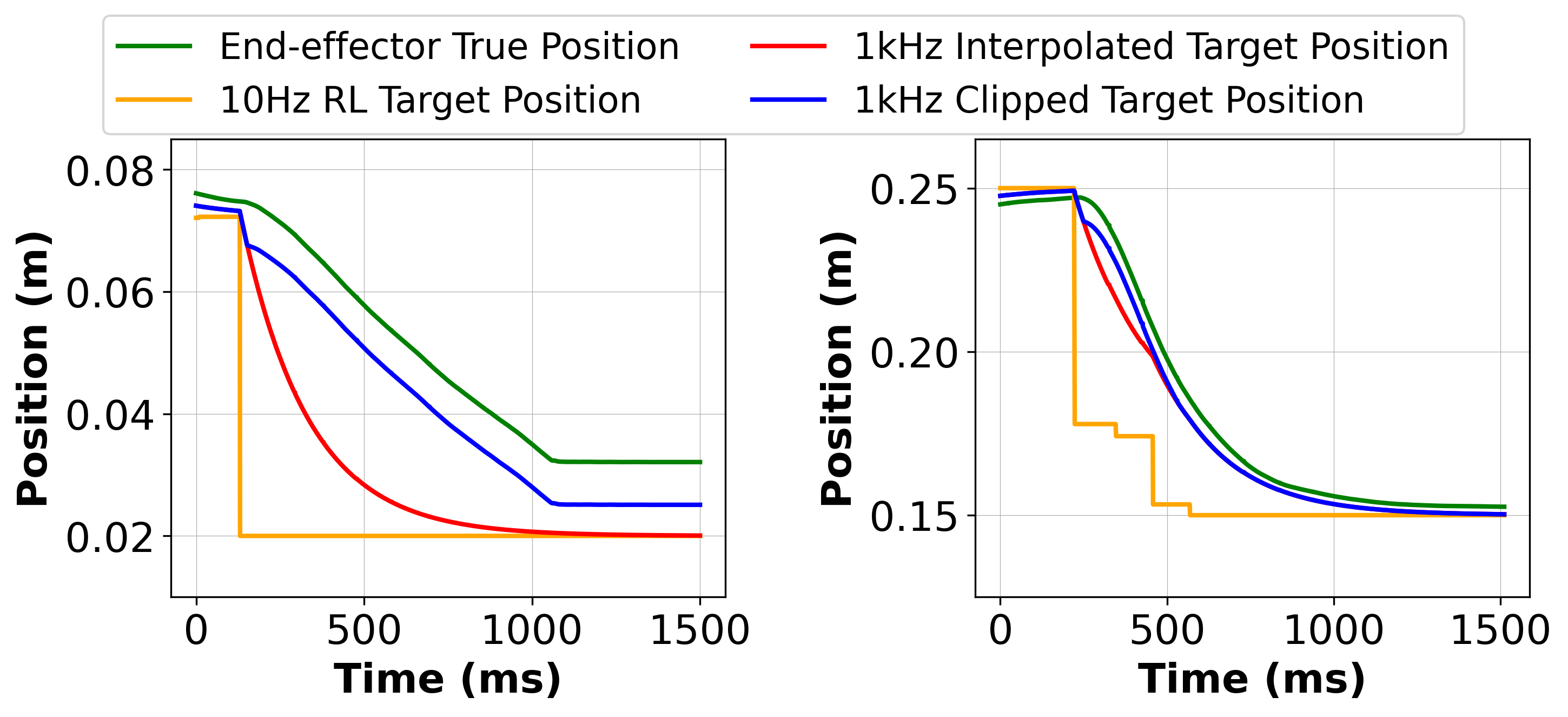
- Integrates high-UTD off-policy RL (RLPD) with a specialized impedance controller that clamps reference targets to ensure safe, compliant contact-rich manipulation
- Provides ready-made infrastructure for difficult real-world components: classifier-based rewards (including VICE), forward-backward reset controllers, and non-blocking asynchronous learner/actor threads
Architecture
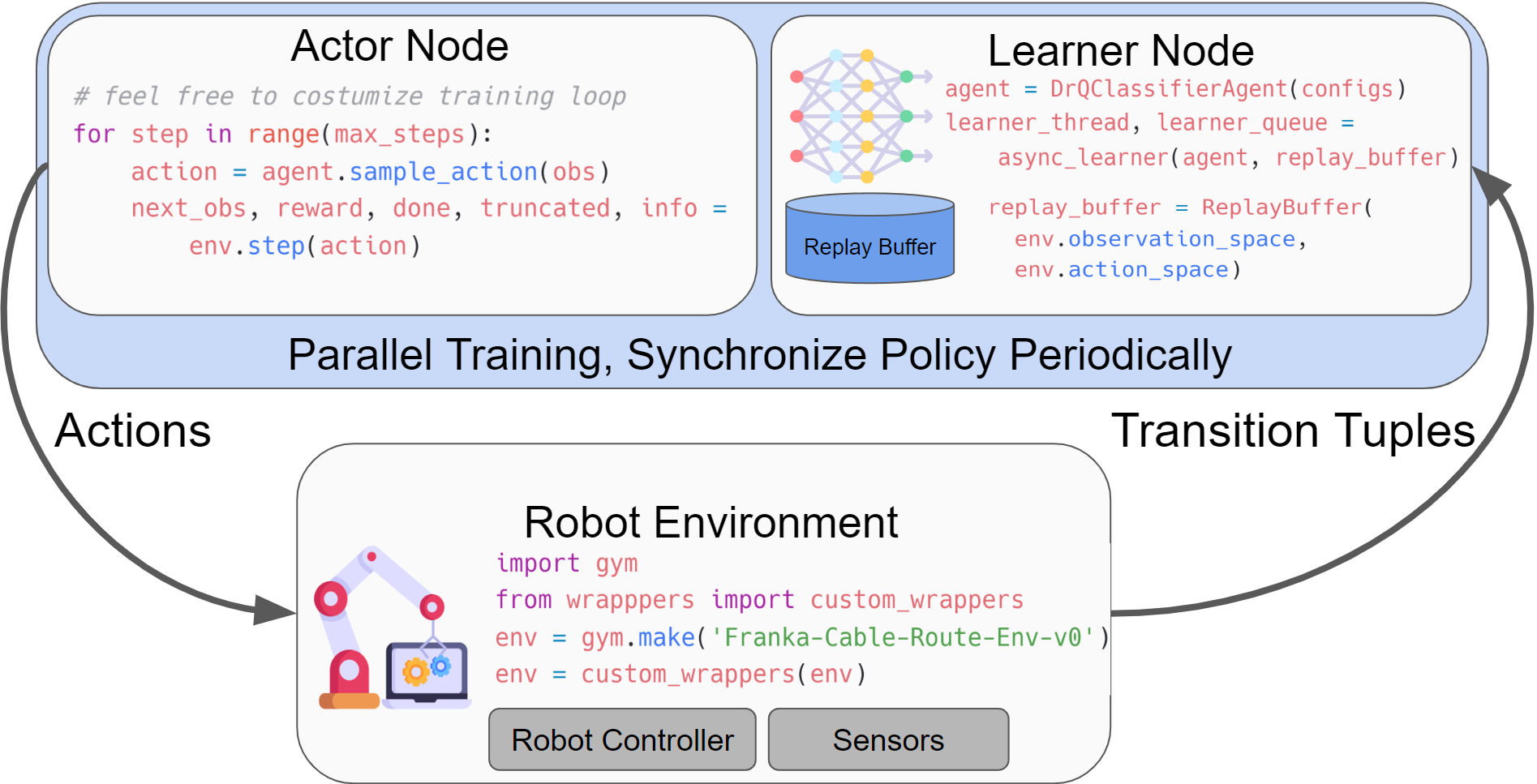
The software architecture of SERL, illustrating the interaction between the User, Learner, Actor, and Robot.
Evaluation Highlights
- Achieves 100% success rate on PCB insertion, cable routing, and object relocation tasks within 25 to 50 minutes of real-world training per policy
- Outperforms standard controllers on PCB insertion, reaching 100% success compared to 20% for variable impedance control baselines
- Demonstrates robust recovery from external perturbations (e.g., human interference) during execution, which imitation learning baselines fail to handle
Breakthrough Assessment
9/10
While not proposing new core algorithms, it solves the critical 'implementation gap' in robotic RL. Achieving <1 hour training for contact-rich tasks with a public codebase is a major enabler for the field.