📝 Paper Summary
Formal Theorem Proving
Mathematical Reasoning
DeepSeek-Prover-V1.5 integrates reinforcement learning from compiler feedback and a curiosity-driven tree search to generate correct formal proofs by iteratively truncating and resuming from valid intermediate states.
Core Problem
Whole-proof generation models often hallucinate intermediate states in long proofs, while step-by-step methods are computationally expensive and struggle with sparse rewards.
Why it matters:
- Formal theorem proving requires rigorous correctness; a single invalid step invalidates the entire proof.
- Existing models like GPT-4 struggle to align abstract reasoning with precise formal syntax (e.g., Lean 4).
- Prior whole-proof generators suffer from compounding errors because they lack access to the actual intermediate states returned by the verifier.
Concrete Example:
In a long proof, the model might assume a tactic `rewrite [h]` succeeds and proceeds, but if the tactic actually fails or produces an unexpected state, all subsequent generated code is invalid garbage.
Key Novelty
Truncate-and-Resume Mechanism within Monte-Carlo Tree Search (MCTS)
- The system generates a proof segment, verifies it, and if an error occurs, truncates the code at the error. It then resumes generation using the verifier's actual state feedback.
- RMaxTS (R-Max Tree Search): A tree search algorithm that uses intrinsic rewards (curiosity) to explore diverse proof paths even when external rewards (success/fail) are sparse.
Architecture
The truncate-and-resume inference loop coupled with tree search.
Evaluation Highlights
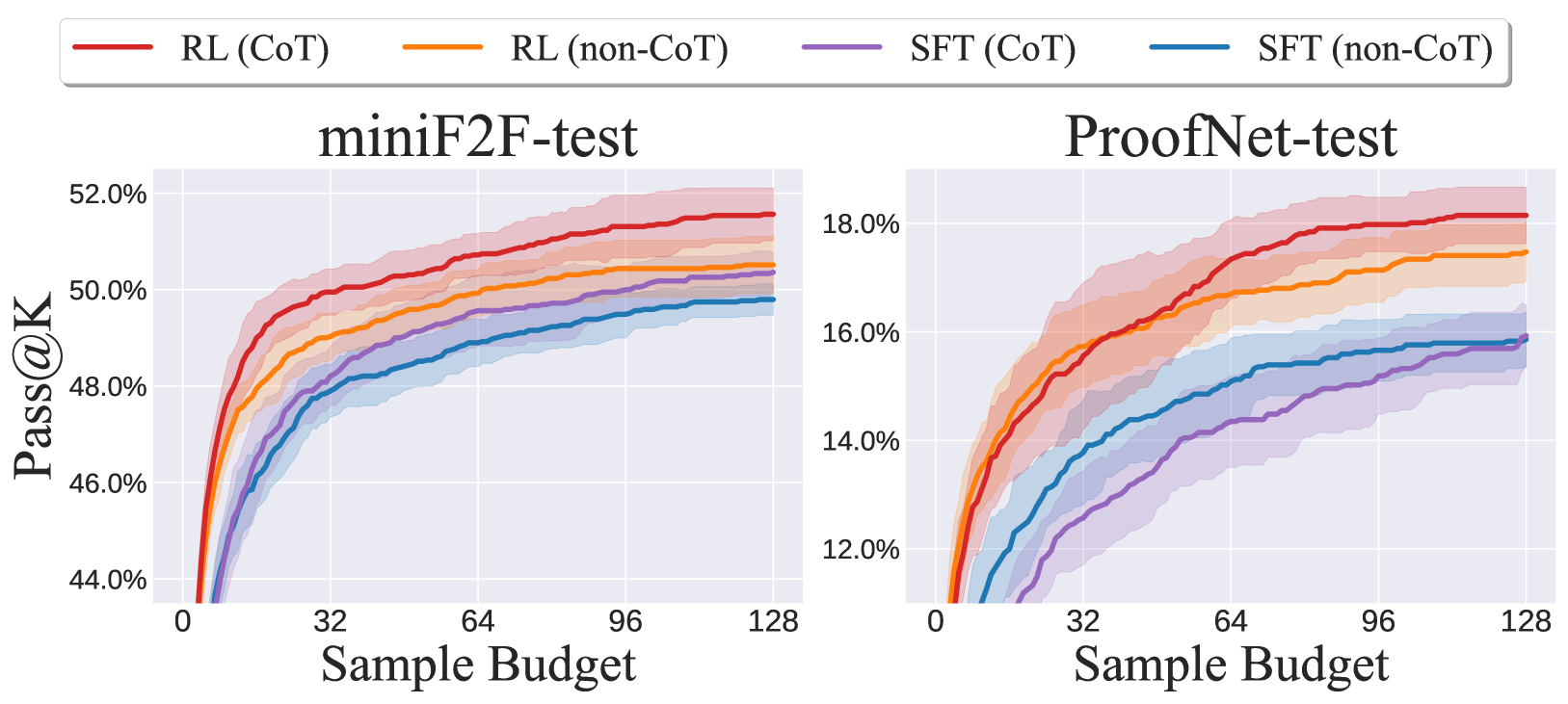
- Achieved 63.5% pass rate on the miniF2F-test benchmark, establishing a new state-of-the-art for open-source models.
- Achieved 25.3% pass rate on the undergraduate-level ProofNet benchmark (test set).
- RL training improved performance from 55.7% (SFT) to 60.2% on miniF2F even without tree search, demonstrating the effectiveness of proof assistant feedback.
Breakthrough Assessment
9/10
Significant jump in SOTA performance on standard benchmarks (miniF2F, ProofNet) by effectively combining RL from compiler feedback with a novel tree search integration.