📊 Experiments & Results
Evaluation Setup
Online fine-tuning starting with offline datasets
Benchmarks:
- D4RL Adroit (Sparse reward dexterous manipulation)
- D4RL AntMaze (Sparse reward navigation)
- D4RL Locomotion (Dense reward continuous control)
- V-D4RL (Pixel-based locomotion)
Metrics:
- Normalized Return (0-100 scale)
- Statistical methodology: Mean and standard deviation reported across 10 seeds
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| RLPD consistently outperforms prior state-of-the-art methods across diverse benchmarks, particularly in sparse reward settings. | ||||
| Adroit (Aggregated) | Normalized Return | 60 | 80 | +20 |
| AntMaze (Aggregated) | Normalized Return | 90 | 95 | +5 |
| Humanoid Walk (Pixels) | Normalized Return | 500 | 3000 | +2500 |
| AntMaze Large | Normalized Return | 0 | 100 | +100 |
| Adroit (Expert Sparse) | Normalized Return | 0 | 800 | +800 |
Experiment Figures
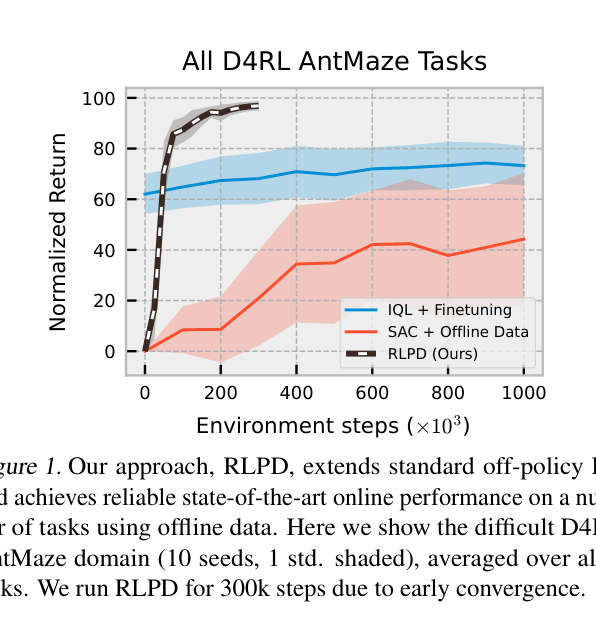
Performance curves on D4RL AntMaze comparing RLPD, SAC+Offline Data, and IQL+Finetuning
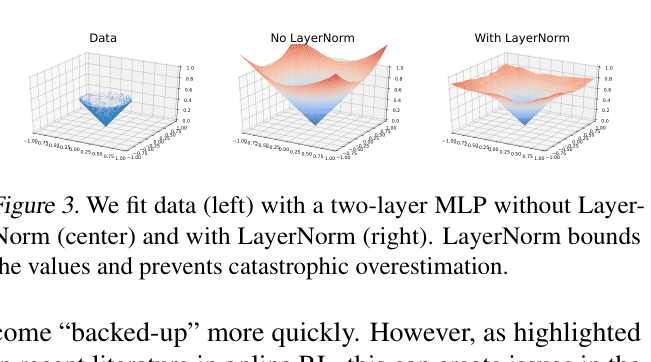
Visualization of function fitting with and without Layer Normalization on a 2D toy regression task
Main Takeaways
- Layer Normalization is the critical component preventing value divergence; without it, standard off-policy RL fails on offline data.
- Symmetric sampling (50/50) is robust and generally optimal, outperforming buffer initialization or imbalanced ratios.
- Ensembles and high UTD ratios are essential for sample efficiency, allowing the agent to squeeze more information from limited data.
- Environment-specific design choices (e.g., removing entropy, adjusting CDQ) follow a predictable workflow that further boosts performance.