📝 Paper Summary
Reinforcement Learning Systems
LLM Post-Training Frameworks
ROLL is a scalable RL library that unifies training, inference, and environment interaction within a single controller, utilizing sample-level scheduling to optimize large-scale LLM post-training.
Core Problem
Existing RL frameworks for LLMs typically employ rigid, multi-stage pipelines that manage data at the batch level, leading to resource inefficiencies (GPU idle time) and engineering complexity when coordinating multiple models (Actor, Critic, Reward).
Why it matters:
- Batch-level barriers cause significant latency in agentic tasks where environment interaction times vary wildly (e.g., long vs. short reasoning chains)
- Managing separate clusters for Actor and Critic models wastes GPU memory when workloads are imbalanced
- Scaling RL to models with hundreds of billions of parameters requires fault tolerance and efficient hardware utilization that ad-hoc scripts cannot provide
Concrete Example:
In standard RLHF training, if one prompt in a batch requires a long environment interaction (e.g., 50 steps in a web browser) while others finish in 2 steps, the entire GPU cluster waits for the slowest sample. ROLL's 'Rollout Scheduler' detects finished samples individually and immediately schedules them for reward computation or starts new samples, eliminating this idle time.
Key Novelty
Sample-Level Rollout Lifecycle Management
- Replaces batch-level barriers with a scheduler that manages the lifecycle of individual samples, enabling asynchronous execution of generation, environment interaction, and reward computation
- Abstracts RL components (Actor, Critic, Environment) into 'Parallel Workers' managed by a single controller, allowing flexible rewiring of the training dataflow without infrastructure changes
Architecture
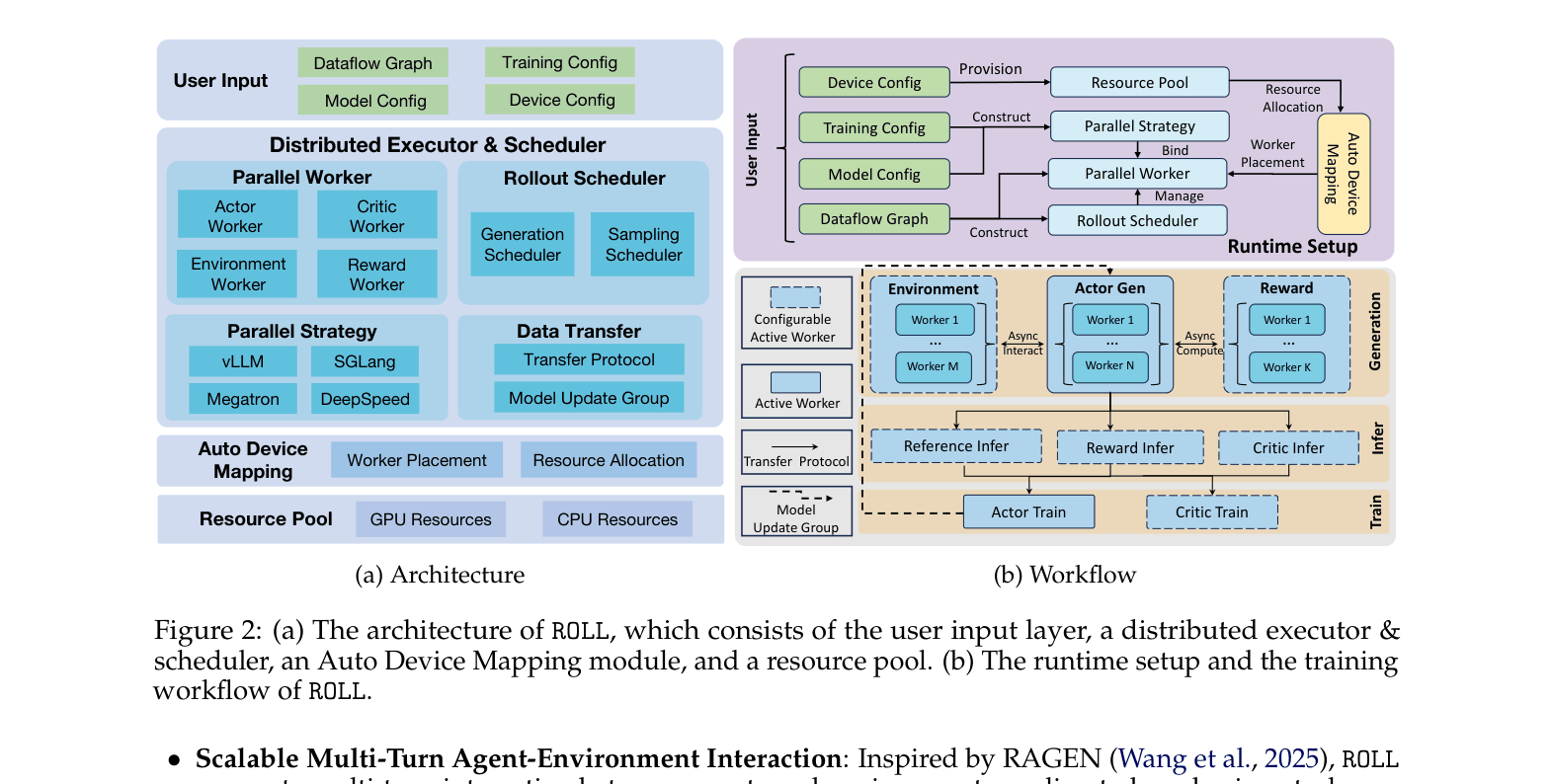
The hierarchical architecture of ROLL, illustrating how user inputs flow through the scheduler to various resource-mapped workers.
Evaluation Highlights
- Scaled in-house training of a 200B+ parameter Mixture-of-Experts (MoE) model across thousands of GPUs for two weeks without interruption
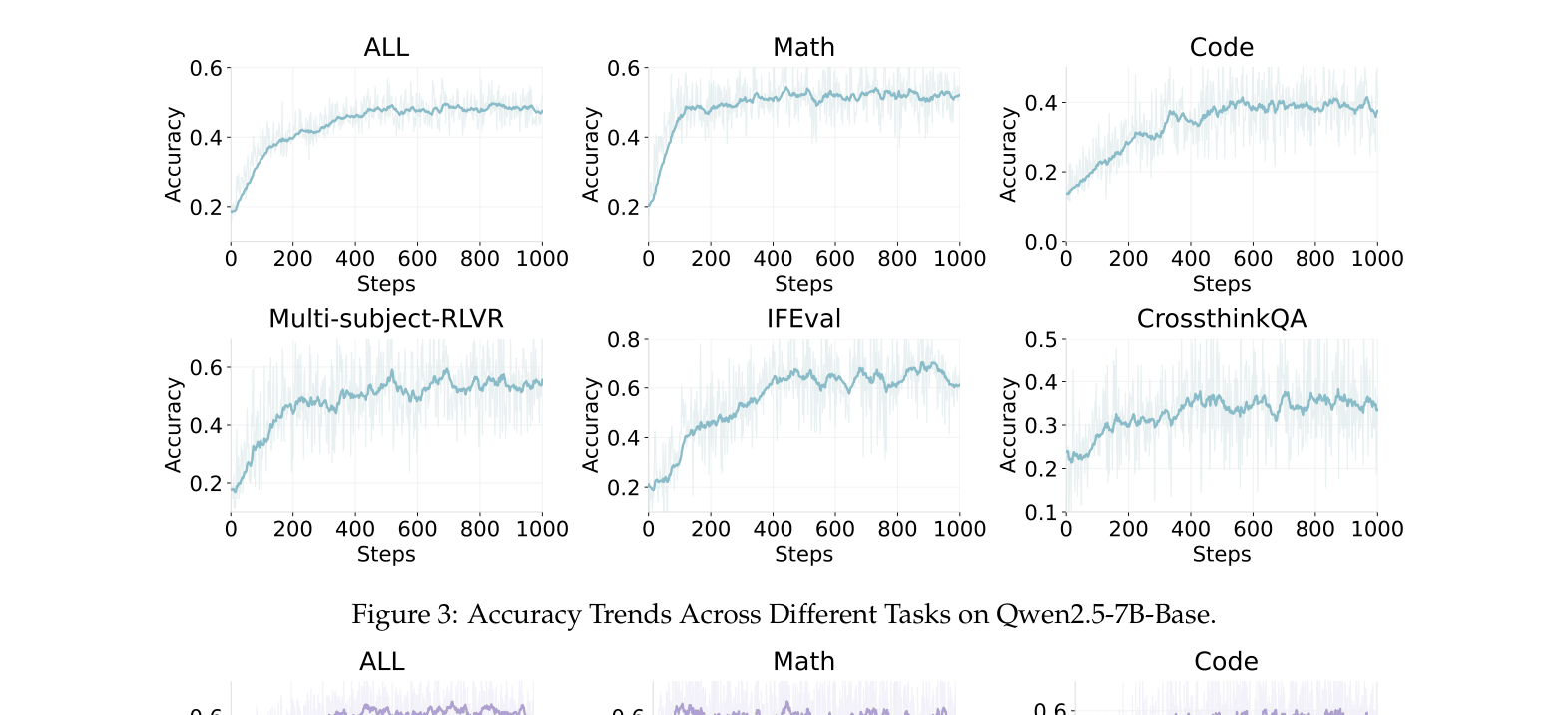
- Improved Qwen2.5-7B-Base accuracy by 2.89x (0.18 to 0.52) on a multi-domain RLVR benchmark (Math, Code, General)
- Achieved >85% success rate on the WebShop agentic task with Qwen-2.5-7B-Instruct, up from a baseline of 37%
Breakthrough Assessment
8/10
Strong system-level contributions with the sample-level scheduler and unified worker abstraction. Proven scalability on massive models (200B+) differentiates it from academic-only libraries.