📝 Paper Summary
Deep Reinforcement Learning Optimization
Normalization Techniques in RL
SimbaV2 stabilizes large-scale reinforcement learning by constraining weight, feature, and gradient norms onto hyperspheres and using distributional value estimation to prevent optimization collapse.
Core Problem
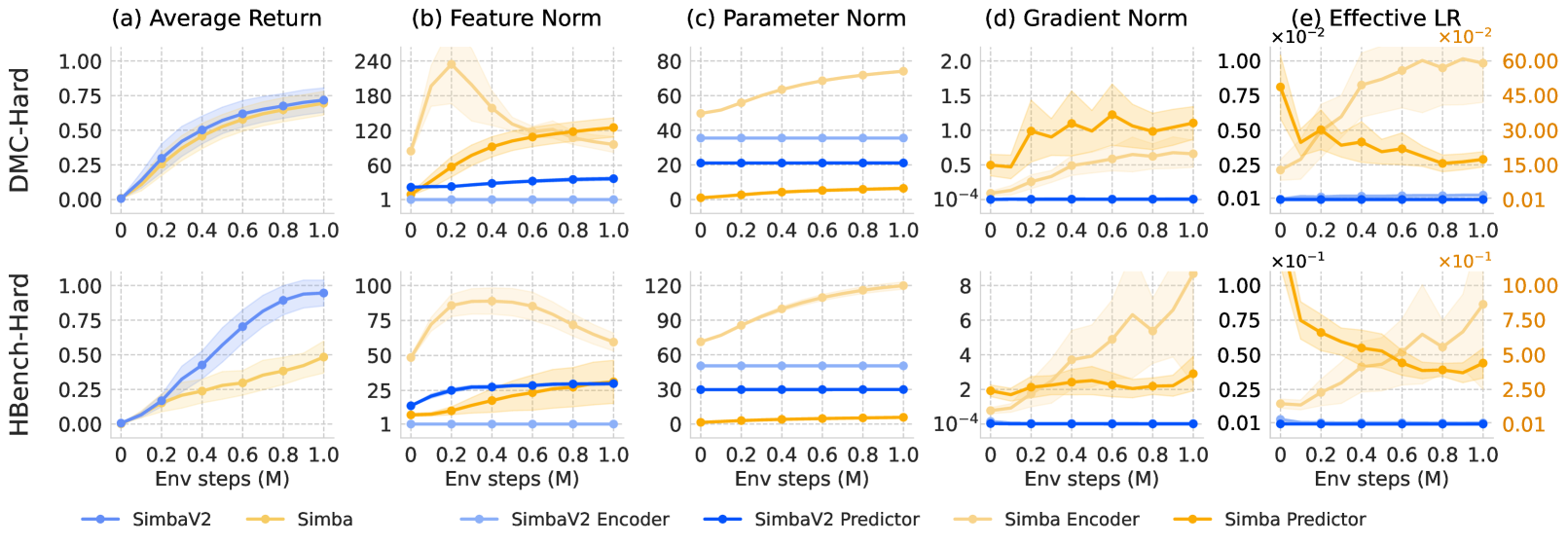
Reinforcement learning fails to scale like supervised learning because non-stationary data leads to uncontrolled growth in feature, parameter, and gradient norms, causing overfitting and unstable optimization.
Why it matters:
- Standard scaling laws (increasing model size/compute) often degrade performance in RL due to the 'scaling paradox' where capacity leads to overfitting early experiences.
- Unbounded parameter norm growth reduces effective learning rates, making weight updates increasingly difficult as training progresses.
- Current solutions like periodic weight reinitialization incur computational overhead and performance drops, making them impractical for safety-critical applications.
Concrete Example:
In standard RL, the implicit bias of Temporal Difference (TD) loss causes feature norms to grow uncontrollably, where dominant dimensions emerge and reduce the agent's plasticity (adaptability), leading to collapse when the task distribution shifts.
Key Novelty
SimbaV2 (Spherical Normalization Architecture)
- Replaces standard normalization (LayerNorm) with Hyperspherical Normalization (L2-norm), forcing all features and weights to lie on a unit-radius sphere to strictly control magnitude.
- Replaces residual connections with Learnable Linear Interpolation (LERP) to maintain spherical constraints while allowing information flow.
- Integrates a distributional critic with reward scaling to bound gradient norms, ensuring that varying reward magnitudes do not destabilize the optimization.
Architecture
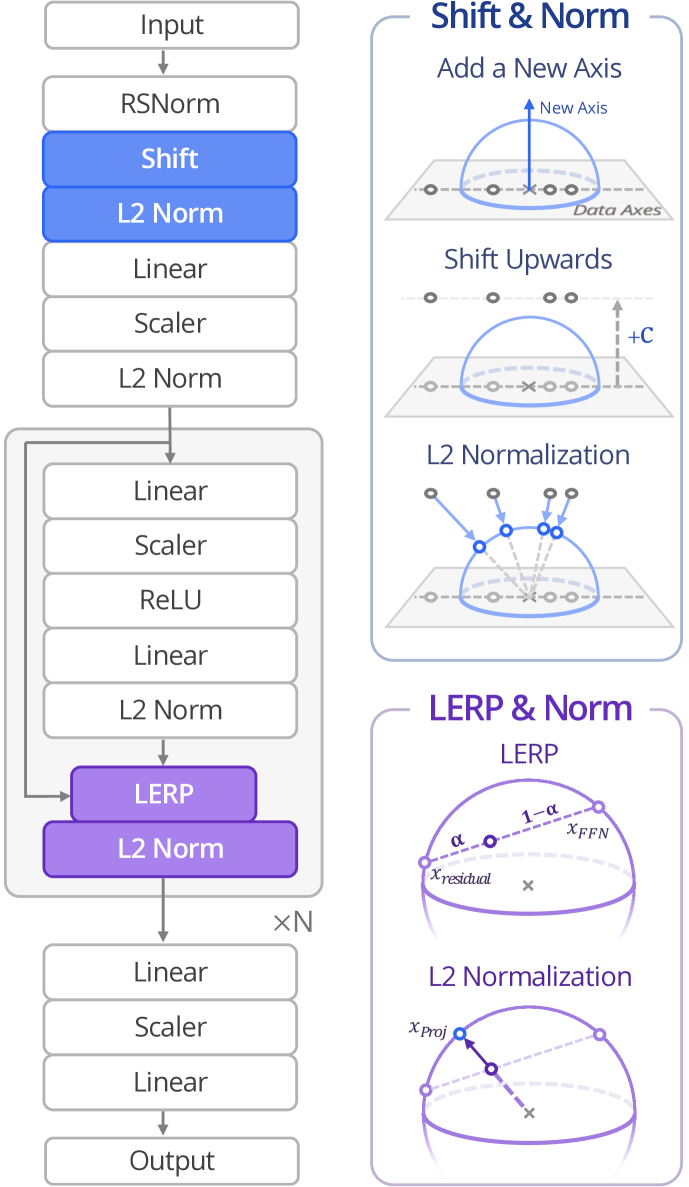
Comparison of SimbaV2's hyperspherical embedding vs. standard methods
Evaluation Highlights
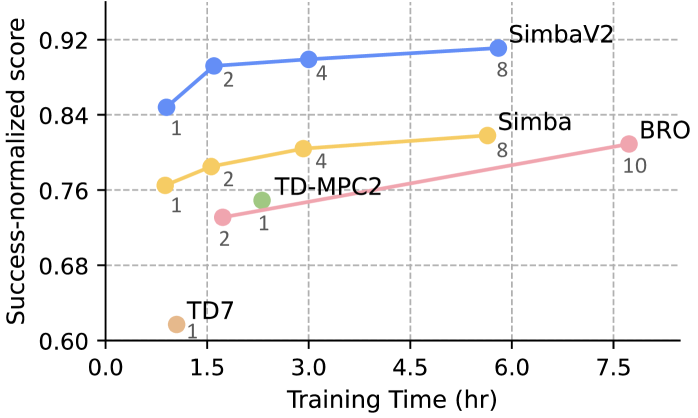
- Achieves state-of-the-art performance across 57 continuous control tasks in the DeepMind Control (DMC) Suite.
- Scales effectively with increased model size and computation on 4 domains (MuJoCo, DMC, MyoSuite, HumanoidBench) without requiring periodic reinitialization.
Breakthrough Assessment
8/10
Proposes a unified, theoretically grounded framework for norm stabilization that addresses the fundamental 'scaling paradox' in RL, showing SOTA results across extensive benchmarks without complex hacks like reinitialization.