📊 Experiments & Results
Evaluation Setup
Evaluated on 4 standard RL benchmarks with a total of 118 environments, using a fixed hyperparameter configuration.
Benchmarks:
- Gym Locomotion (Continuous control (state vectors))
- DMC Proprioceptive (Robotics control (state vectors))
- DMC Visual (Robotics control (pixels))
- Atari 100k (evaluated at 10M frames) (Discrete arcade games (pixels))
Metrics:
- Total Reward
- Human-Normalized Score
- Training FPS
- Evaluation FPS
- Statistical methodology: 95% stratified bootstrap confidence intervals over 10 seeds
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Gym (HalfCheetah-v4) | Training FPS | 14 | 49 | +35 |
| Gym (HalfCheetah-v4) | Evaluation FPS | 236 | 1900 | +1664 |
| Atari (Any) | Parameter Count (Millions) | 187.3 | 4.4 | -182.9 |
| Atari - 1M | Human-Normalized Score Impact | 0.0 | -1.35 | -1.35 |
| Gym - Locomotion | TD3-Normalized Score Impact | 0.0 | -1.17 | -1.17 |
Experiment Figures
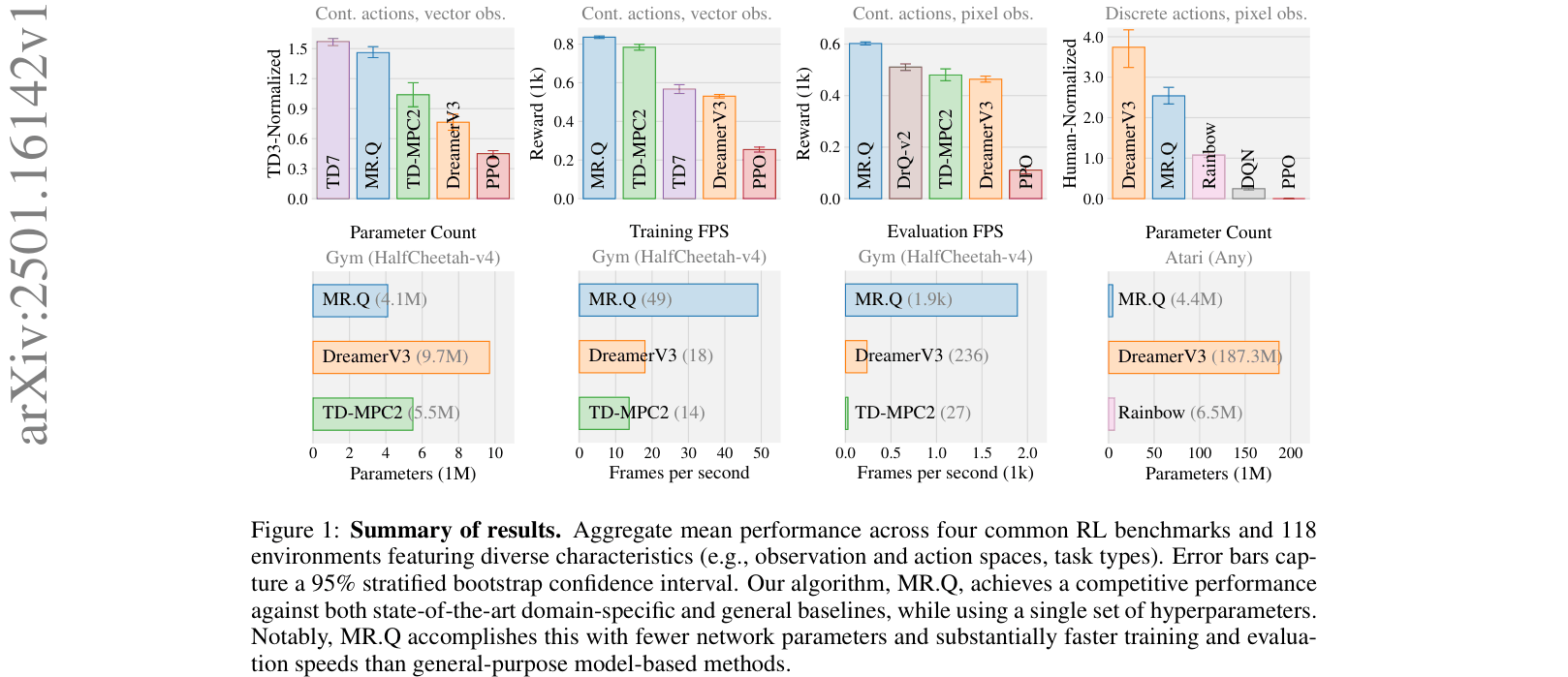
Aggregate performance bar charts across 4 benchmarks and efficiency metrics (FPS/Params).
Main Takeaways
- Model-based representations can replace explicit planning: MR.Q matches or beats planning-based agents (TD-MPC2) on DMC benchmarks without runtime search.
- Generalization across modalities: The same algorithm handles pixels (Atari/DMC Visual) and state vectors (Gym/DMC Proprio) effectively.
- Parameter efficiency: MR.Q achieves competitive generalist performance with <5M parameters, whereas DreamerV3 requires >180M for similar generality.
- Design choices matter differently per domain: 'MSE reward loss' helps slightly in Gym (+0.10) but hurts significantly in Atari (-0.79), highlighting the difficulty of finding truly universal hyperparameters.