📝 Paper Summary
Maximum Entropy Reinforcement Learning
Diffusion Models for Control
DIME integrates diffusion models into Maximum Entropy RL by deriving a tractable lower bound on the entropy objective, enabling expressive non-Gaussian policies with principled exploration.
Core Problem
Standard MaxEnt-RL relies on Gaussian policies with limited expressivity, while diffusion policies are expressive but have intractable marginal entropy, making them difficult to integrate into the MaxEnt framework.
Why it matters:
- Gaussian policies struggle to represent complex, multi-modal behaviors required for sophisticated control tasks.
- Existing diffusion RL methods often rely on heuristic exploration (e.g., adding Gaussian noise) rather than leveraging the diffusion model's inherent generative capabilities for exploration.
- Accurate entropy estimation is crucial for the MaxEnt framework to balance exploration and exploitation effectively.
Concrete Example:
In a complex task like 'Dog Run', a Gaussian policy might get stuck in a local optimum due to unimodal exploration. A standard diffusion policy might fail to explore effectively without adding arbitrary noise. DIME uses the diffusion process itself to generate diverse, non-Gaussian exploratory actions.
Key Novelty
Diffusion-Based Maximum Entropy RL (DIME)
- Casts the policy improvement step as an approximate inference problem where the diffusion backward process (policy) attempts to match the time-reversal of a forward noising process.
- Derives a tractable lower bound on the intractable marginal entropy of the diffusion policy using the difference between the forward and backward diffusion trajectories.
- Proposes a policy iteration scheme that provably converges to the optimal diffusion policy by maximizing this lower-bound objective.
Architecture
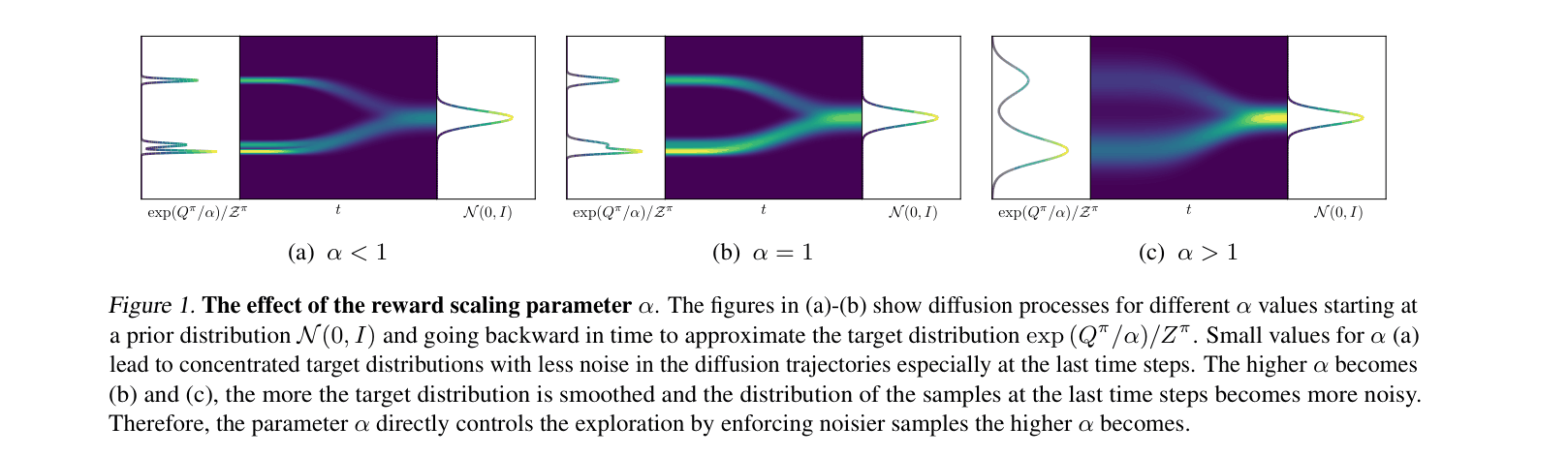
Illustration of the diffusion process for different reward scaling parameters (alpha). It visualizes how the backward denoising process approximates the target distribution.
Evaluation Highlights
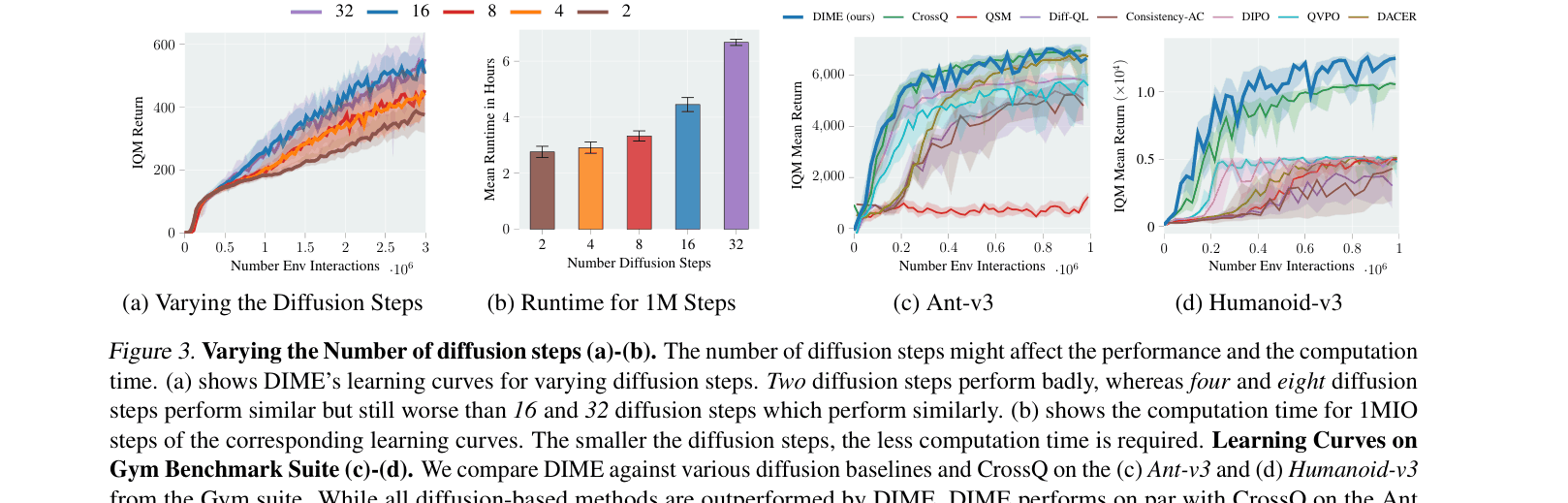
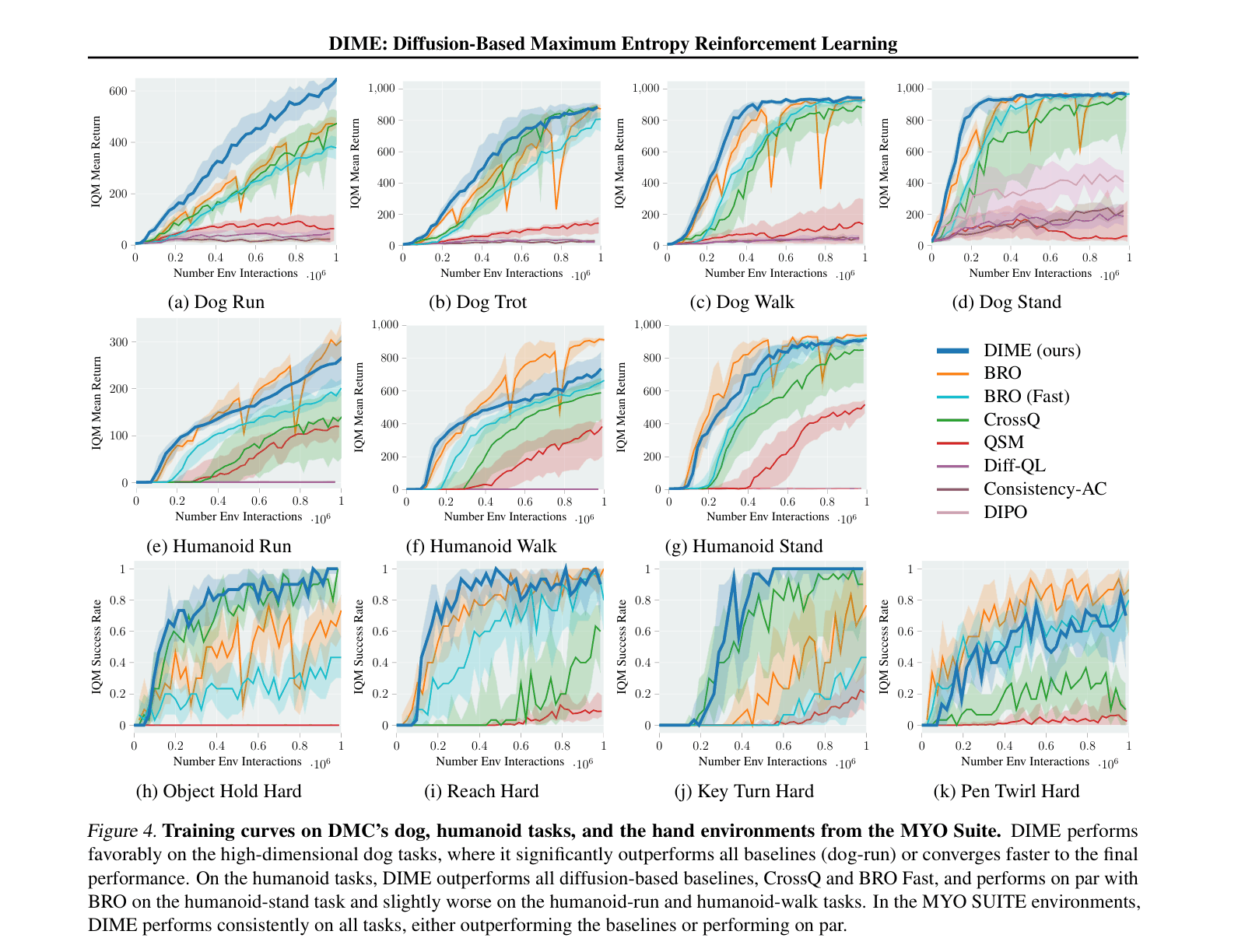
- Outperforms state-of-the-art diffusion baselines (e.g., DIPO, QSM, DACER) on 13 high-dimensional control benchmarks (DeepMind Control Suite, MyoSuite, Gym).
- Achieves competitive or superior performance compared to Gaussian-based SOTA (CrossQ, BRO) while requiring fewer algorithmic design choices (e.g., no target networks).
- Demonstrates superior exploration in high-dimensional tasks like 'Dog Run', reaching significantly higher returns than Gaussian baselines.
Breakthrough Assessment
8/10
The theoretical unification of diffusion models with the MaxEnt-RL framework via a tractable entropy bound is a significant conceptual advance, backed by strong empirical results on difficult benchmarks.