📝 Paper Summary
Offline-to-online Reinforcement Learning
Temporal Difference Learning
Action Chunking
Q-chunking improves reinforcement learning by training agents to predict and evaluate sequences of actions, enabling faster unbiased value learning and more coherent exploration.
Core Problem
In long-horizon, sparse-reward tasks, standard reinforcement learning struggles with efficient exploration and slow value propagation, while offline data often contains non-Markovian behaviors that standard single-step policies fail to capture.
Why it matters:
- Solving complex robotic manipulation tasks from scratch is prohibitively expensive due to the difficulty of stumbling upon sparse rewards
- Current offline-to-online methods struggle to utilize offline data effectively for exploration, often resulting in pessimistic policies that do not improve online
- Standard n-step returns, used to speed up learning, introduce bias when used with off-policy data, destabilizing training
Concrete Example:
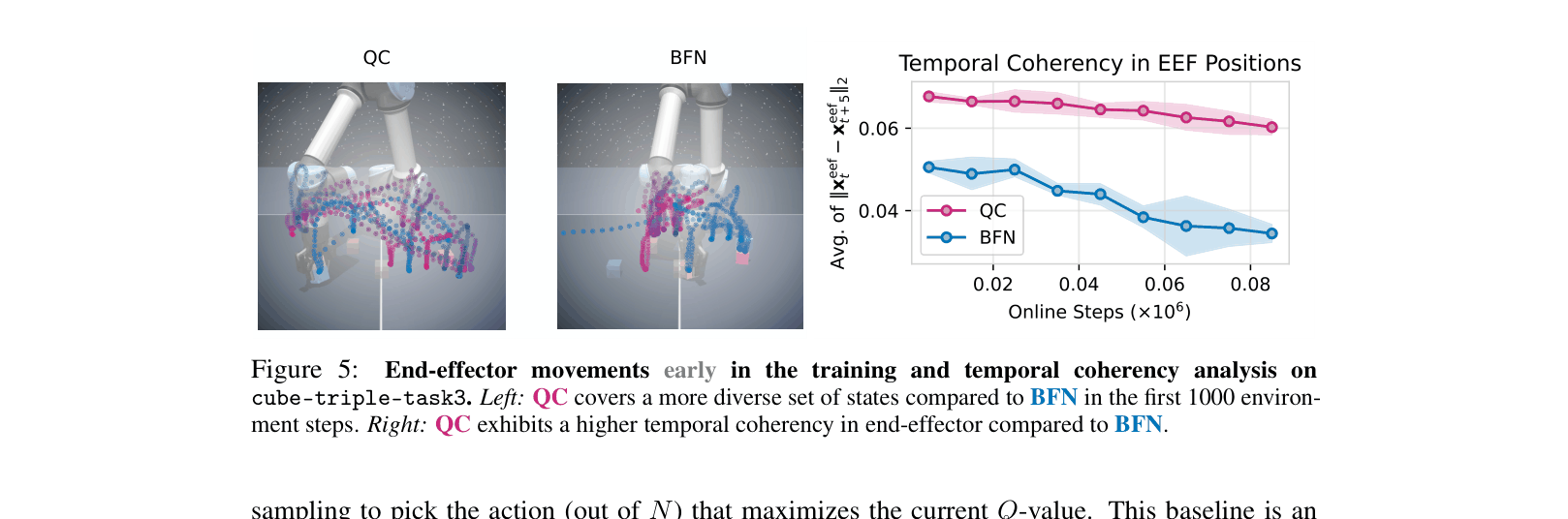
In a robotic manipulation task like lifting a cube, a standard RL agent might twitch randomly (jittery motion) and fail to grasp the object. A Q-chunking agent predicts a coherent 5-step sequence (e.g., 'reach down smoothly'), which is more likely to interact with the object and discover rewards.
Key Novelty
Q-learning with Action Chunking (Q-chunking)
- Redefines the RL problem to operate on 'chunks' (sequences) of actions for both the actor and the critic, rather than single steps
- Uses the chunked critic to perform n-step value backups that are unbiased (unlike standard n-step returns) because the critic explicitly conditions on the full action sequence
- Leverages flow-matching policies to model complex, non-Markovian behavior distributions from offline data, enabling temporally coherent exploration
Architecture
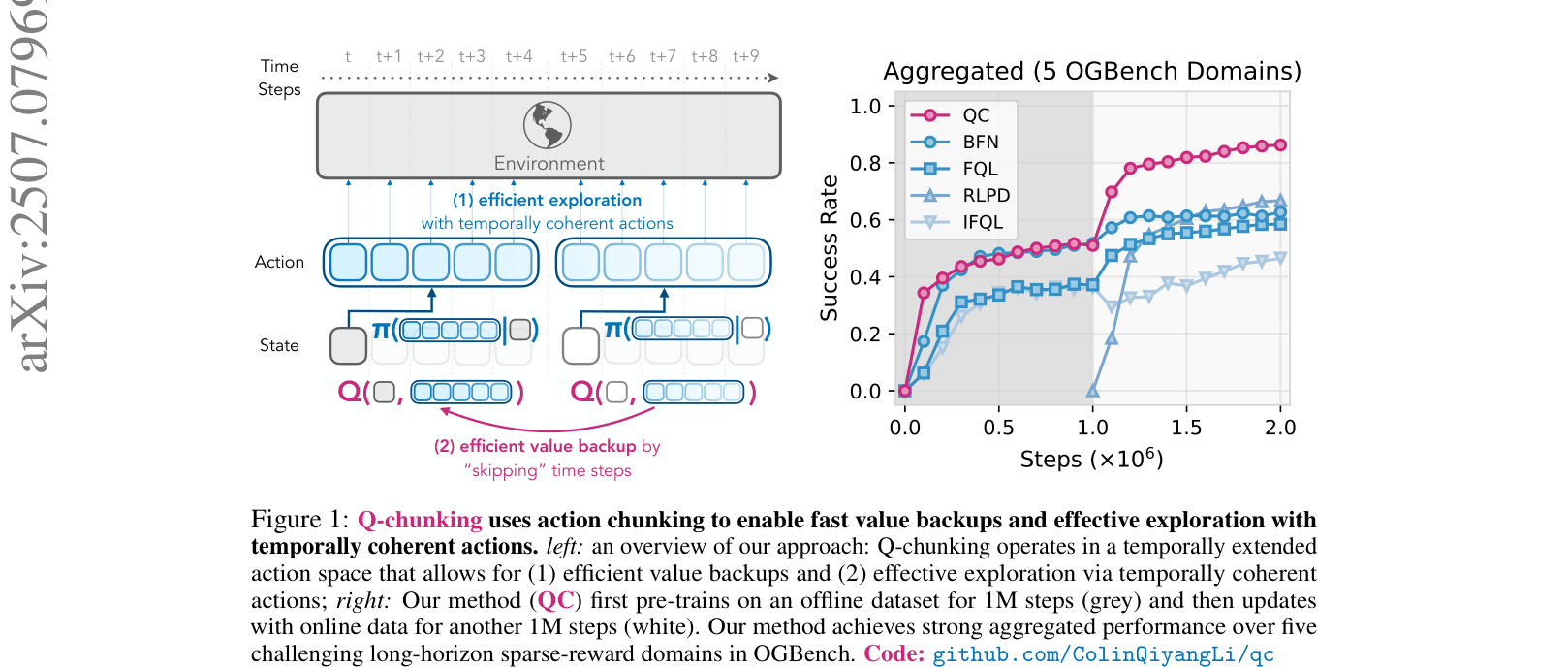
Overview of Q-chunking method compared to standard RL. Shows the timeline of interactions and value backups.
Evaluation Highlights
- Achieves 86% success rate on the challenging Cube-Quadruple task where strong baselines like RLPD and FQL achieve <1% and ~60% respectively
- Outperforms prior state-of-the-art offline-to-online methods on 5 out of 5 aggregated OGBench domains
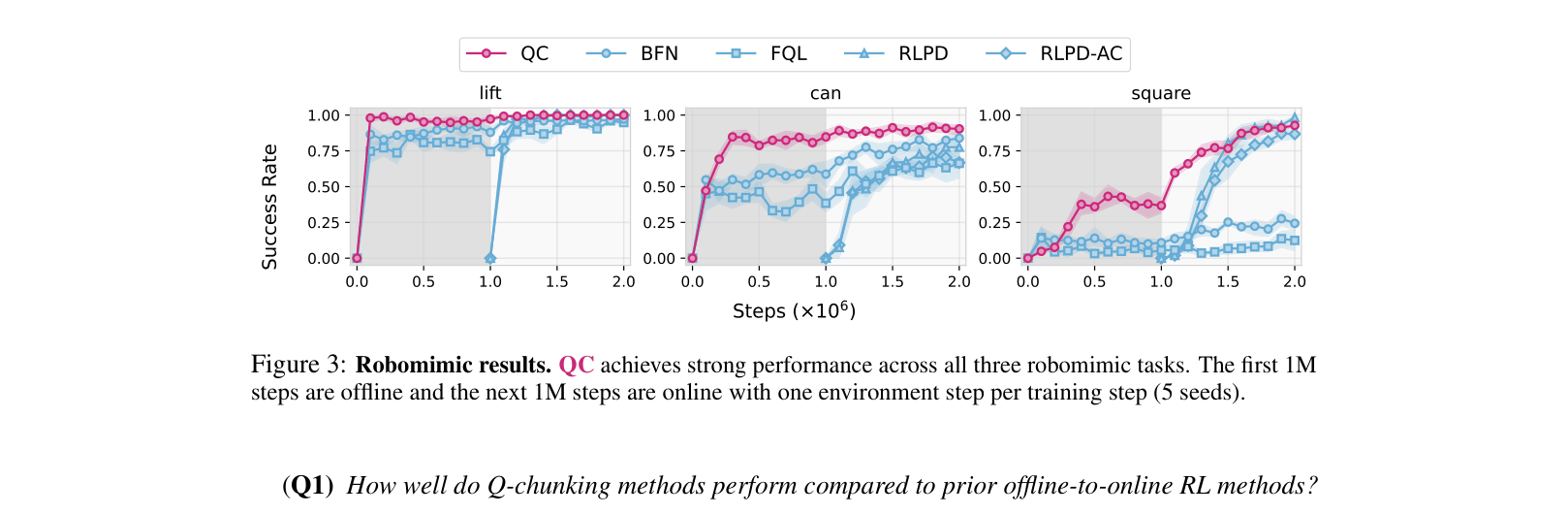
- Demonstrates superior sample efficiency on Robomimic tasks compared to n-step and 1-step TD baselines
Breakthrough Assessment
8/10
Simple yet highly effective recipe that solves a fundamental bias issue in n-step returns while significantly boosting exploration in hard sparse-reward tasks. The performance gap on the hardest tasks is substantial.