📝 Paper Summary
Online Reinforcement Learning
Diffusion Models for Control
The paper introduces Reweighted Score Matching (RSM) to train diffusion policies in online RL without requiring samples from the optimal policy, enabling efficient max-entropy and mirror descent policy optimization.
Core Problem
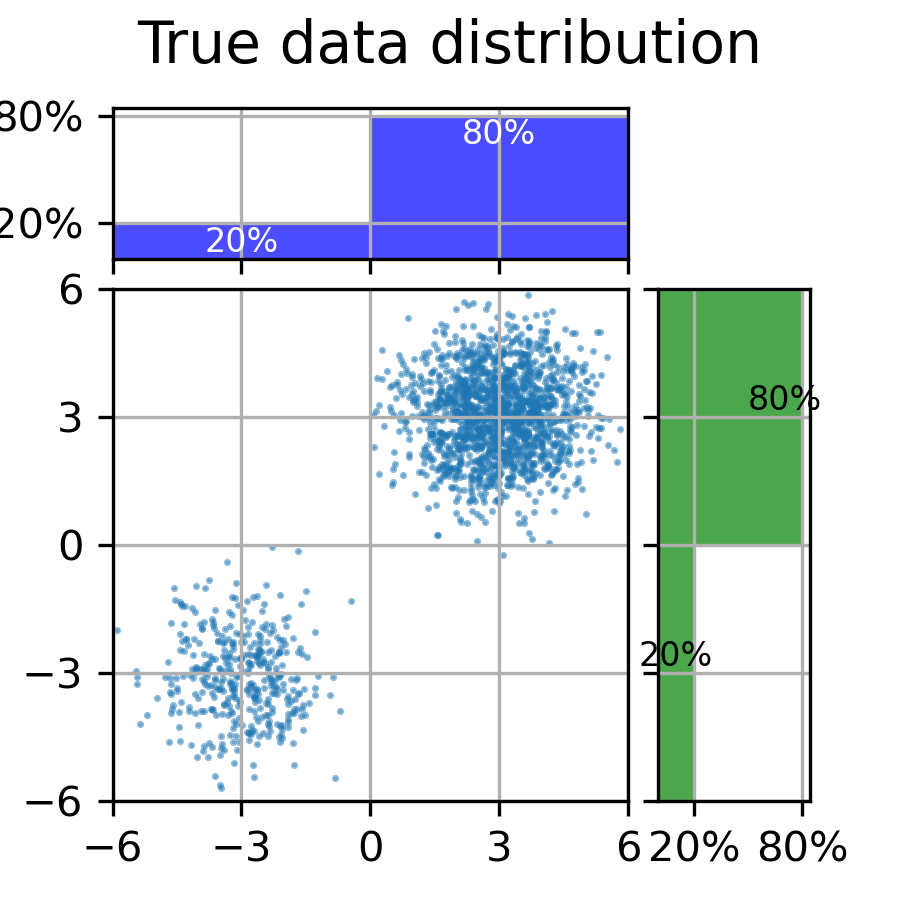
Standard diffusion model training (denoising score matching) requires samples from the target distribution, but in online RL, we cannot sample from the optimal policy (the target) because it is unknown and being learned.
Why it matters:
- Backpropagating policy gradients through the diffusion reverse process is computationally expensive and unstable
- Existing methods to bypass sampling suffer from high bias or extreme memory costs, limiting diffusion policies to offline or imitation learning settings
- Projecting expressive energy-based policies onto restrictive Gaussian distributions (as in SAC) sacrifices the multimodality and expressiveness needed for complex tasks
Concrete Example:
In standard diffusion training, you need a dataset of 'good' images to learn the score function. In online RL, the 'good' actions (target policy) are defined by an evolving value function (Q-function). Since we can't sample actions from this theoretical optimal policy to train the score network, standard DSM fails or requires expensive inner-loop sampling.
Key Novelty
Reweighted Score Matching (RSM)
- Generalizes standard denoising score matching by introducing a weighting term that allows training on samples from the *current* policy rather than the *optimal* target policy
- Derives two specific algorithms (DPMD and SDAC) by equating the reweighting term to specific policy optimization objectives (Policy Mirror Descent and Max-Entropy RL)
- Eliminates the need for backpropagation through the diffusion chain or expensive MCMC sampling during training
Architecture
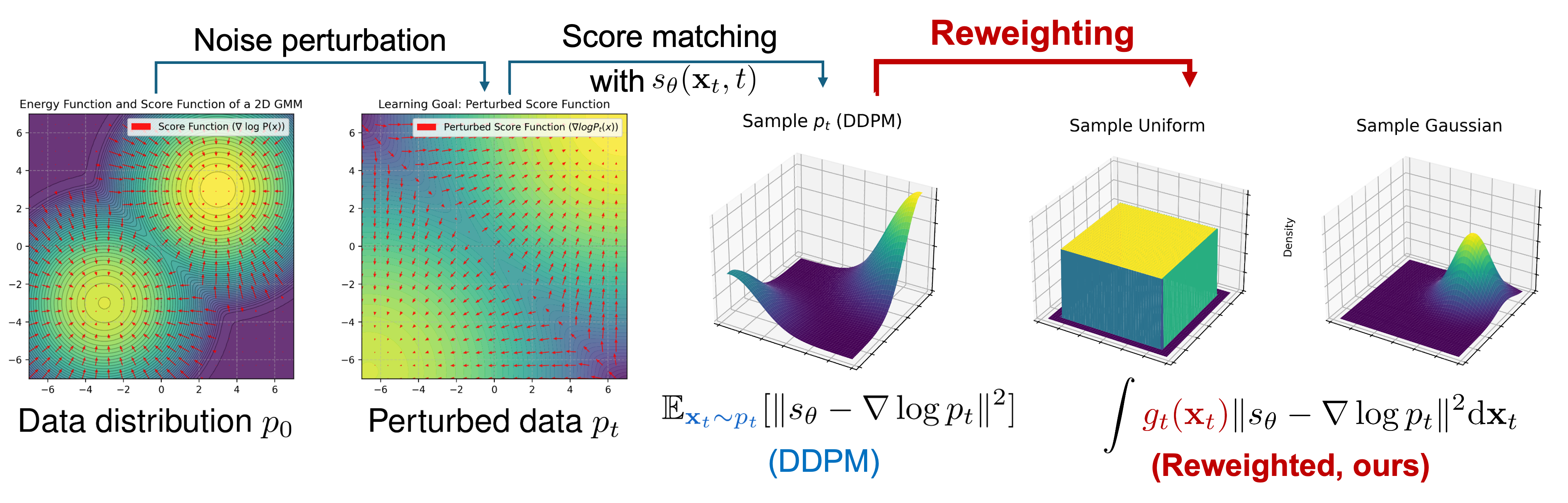
Conceptual comparison between standard Denoising Score Matching (DSM) and Reweighted Score Matching (RSM).
Evaluation Highlights
- +120% improvement over Soft Actor-Critic (SAC) on Humanoid and Ant tasks in MuJoCo
- Outperforms recent diffusion-RL baselines (Score-SDE, IDQL) on most MuJoCo benchmarks
- Achieves comparable or better computational efficiency (runtime) than baselines like IDQL while reaching higher returns
Breakthrough Assessment
8/10
Significant methodological contribution bridging diffusion models and online RL. It solves the fundamental 'sampling from unknown target' issue elegantly via reweighting, unlocking diffusion's expressiveness for online control.