📝 Paper Summary
Reinforcement Learning for LLMs
Scaling Laws
Reasoning Models
The paper establishes a sigmoidal scaling framework for RL to predict asymptotic performance and proposes ScaleRL, a recipe optimizing efficiency and stability for large-scale reasoning training.
Core Problem
Reinforcement learning for LLMs lacks predictive scaling laws comparable to pre-training, forcing practitioners to rely on expensive, ad-hoc trial-and-error without understanding how algorithms behave at scale.
Why it matters:
- Frontier models like Deepseek-R1-Zero consume massive compute (100,000 GPU hours) for RL, making blind experimentation cost-prohibitive
- Current academic research focuses on isolated algorithms that may work at small scales but fail to scale up (the 'Bitter Lesson')
- There is no principled way to distinguish between algorithmic improvements that increase maximum performance versus those that merely speed up convergence
Concrete Example:
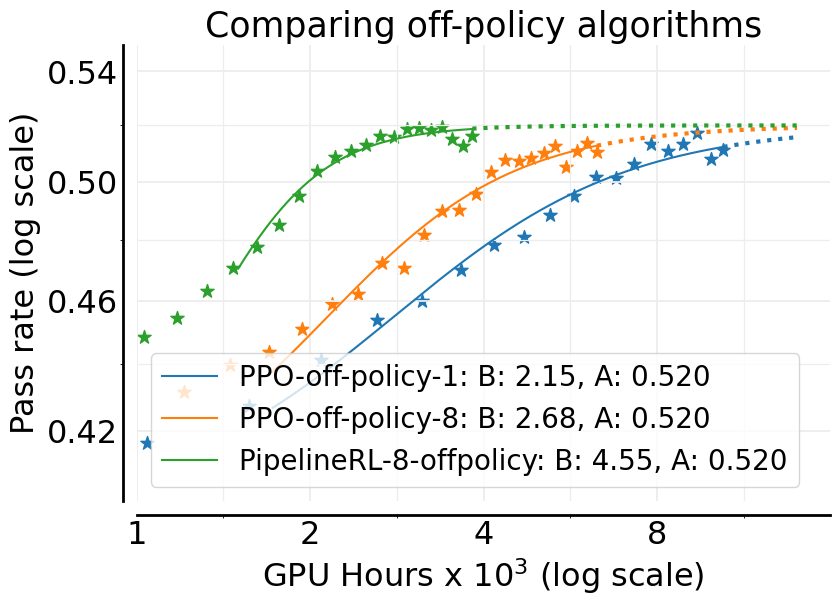
A researcher might choose the DAPO algorithm because it performs well at 1,000 GPU hours. However, the paper shows that at 16,000 GPU hours, DAPO hits a lower performance ceiling (asymptote) compared to CISPO, wasting vast compute resources on a method that cannot scale.
Key Novelty
Predictive Sigmoidal Scaling for RL & ScaleRL Recipe
- Models RL performance (pass rate) as a function of compute using a sigmoidal curve, parameterized by asymptotic ceiling (A) and efficiency (B), allowing extrapolation from short runs
- Identifies 'ScaleRL', a specific combination of loss functions, normalization techniques, and system optimizations (like PipelineRL) that maximizes the asymptotic ceiling while maintaining stability
- Demonstrates that common tricks (e.g., advantages normalization) often only improve efficiency (speed), while loss choice and precision determine the absolute performance ceiling
Architecture
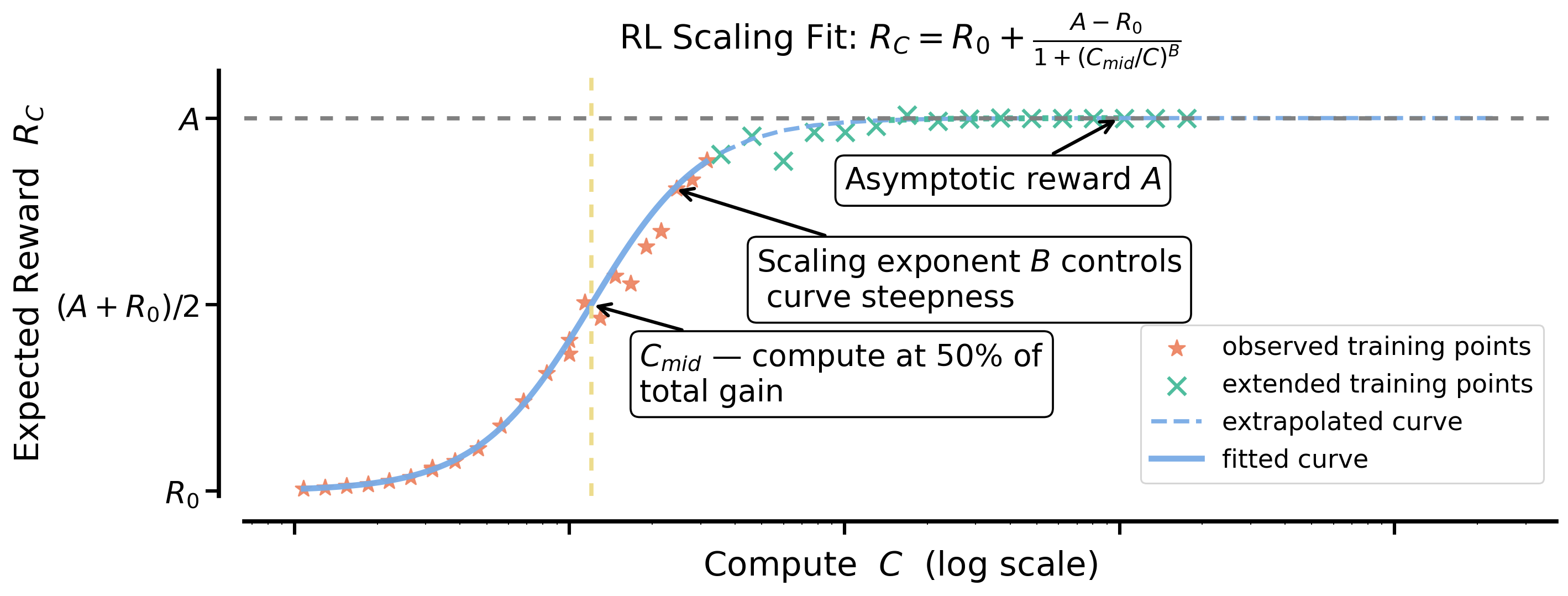
Schematic of the Sigmoidal Scaling Law used to model RL performance.
Evaluation Highlights
- Precision fix (FP32 at logits) improves asymptotic pass rate (A) significantly from 0.52 to 0.61 on verifiable math problems
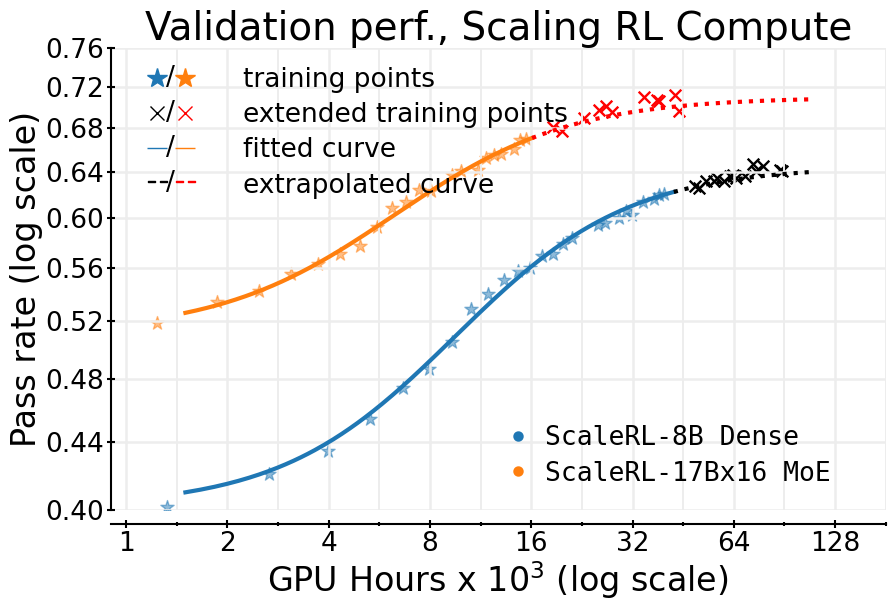
- ScaleRL recipe maintains predictive scaling on a massive 100,000 GPU-hour run, matching the trajectory extrapolated from the first ~8,000 hours
- CISPO loss function consistently achieves a higher performance ceiling than the widely used DAPO baseline in large-scale regimes
Breakthrough Assessment
9/10
Establishes the first rigorous 'scaling law' analog for RL, backed by massive compute (400k GPU hours). The distinction between efficiency-improving and ceiling-raising interventions is a critical contribution for the field.