📝 Paper Summary
LLM-as-a-Judge
Reward Modeling
Reasoning/Chain-of-Thought
J1 transforms subjective preference tasks into verifiable RL challenges to train a thinking judge that produces chain-of-thought reasoning before outputting verdicts, achieving state-of-the-art evaluation performance using only synthetic data.
Core Problem
Standard reward models output scores without explicit reasoning, limiting their accuracy and interpretability, while existing LLM-as-a-Judge methods often rely on costly human data or lack direct optimization for reasoning quality.
Why it matters:
- Evaluation quality bottlenecks AI progress; poor judges cannot reliably distinguish better models during training (RLHF) or benchmarking
- Subjective tasks (e.g., chat) lack ground truth, making it difficult to apply verifiable reinforcement learning rewards to improve judgment capabilities
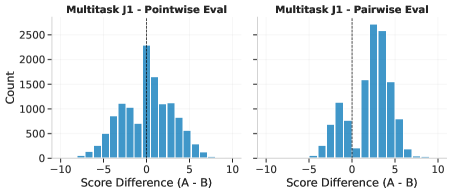
- Standard pairwise judges suffer from severe positional bias (preferring the first option), reducing reliability
Concrete Example:
When evaluating a math problem response, a standard judge might fail to notice a subtle calculation error in step 3. J1 explicitly reasons: 'Checking step 3... calculation is wrong', identifies the error, and penalizes the response, whereas a non-thinking judge might hallucinate correctness based on surface form.
Key Novelty
J1 (Thinking-LLM-as-a-Judge via RL)
- Unifies verifiable (math) and subjective (chat) tasks into a single format where 'correctness' is defined by verifiable rewards on synthetic preference pairs, allowing RL to optimize judgment across domains
- Trains a 'thinking' judge using GRPO (Group Relative Policy Optimization) to generate explicit reasoning traces before the verdict, incentivized by verdict correctness and consistency rewards
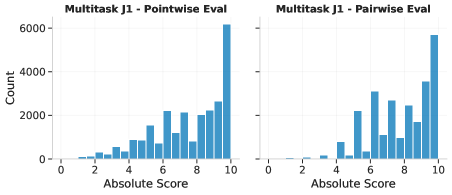
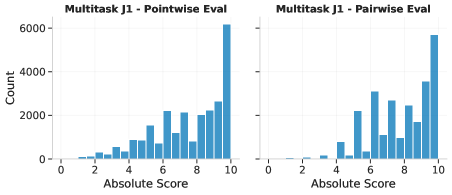
- Develops a multitask architecture that learns both pairwise (comparison) and pointwise (scoring) evaluation simultaneously to mitigate position bias and improve robustness
Architecture
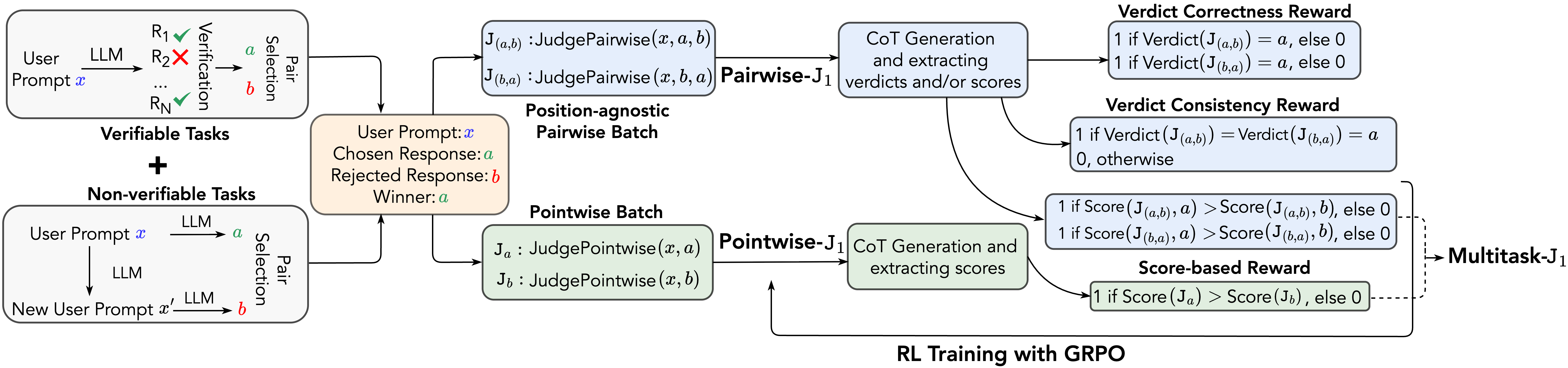
The J1 training framework pipeline, illustrating the flow from synthetic data generation to RL training with verifiable rewards.
Evaluation Highlights
- J1-Qwen-32B-MultiTask achieves 93.6 on RewardBench, outperforming all previous generative reward models and significantly larger scalar reward models
- On PPE Correctness, J1-Qwen-32B-MultiTask scores 76.8%, outperforming DeepSeek-GRM-27B (+17%) and EvalPlanner (+6.8%) while using significantly less training data
- J1-Llama-8B outperforms larger 27B scalar reward models (Skywork-Reward-Gemma-2-27B) on PPE Correctness (59.2 vs 54.7)
Breakthrough Assessment
9/10
Demonstrates that strong reasoning (thinking) can be induced in judges via RL on purely synthetic data, beating closed-source models (o1-mini) and much larger open models on judgment tasks.