📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Reinforcement Learning (RL) Post-training
Perception-R1 adapts rule-based reinforcement learning to visual perception, showing that accurate reward matching and removing explicit reasoning chains enable multimodal models to achieve state-of-the-art detection and counting performance.
Core Problem
Standard reasoning-based RL (like Chain-of-Thought) fails in visual perception tasks because they lack semantic search space and involve multi-object outputs that are hard to score without order.
Why it matters:
- Current reasoning MLLMs focus on language/math, leaving visual perception (detection, counting) lagging behind
- Directly applying language-based RL strategies (CoT) to perception often degrades performance due to unnecessary verbose reasoning
- Perception tasks require recognizing multiple objects simultaneously, creating a 'matching' problem for rewards that single-step RL doesn't naturally handle
Concrete Example:
In a visual counting task with three apples, if the model predicts three bounding boxes, a standard reward function struggles to know which predicted box corresponds to which ground truth apple to calculate IoU, often penalizing correct but unordered predictions.
Key Novelty
Perception-R1 (Perception Policy via GRPO)
- Adapts Group Relative Policy Optimization (GRPO) to visual tasks by removing the 'thinking' process and focusing on perceptual perplexity
- Introduces a bipartite graph matching mechanism (via Hungarian algorithm) into the reward function to correctly align unordered multi-object predictions with ground truth
- Uses 'physical truth' rewards (IoU, Euclidean distance) rather than semantic rewards, providing dense and objective feedback for policy updates
Architecture
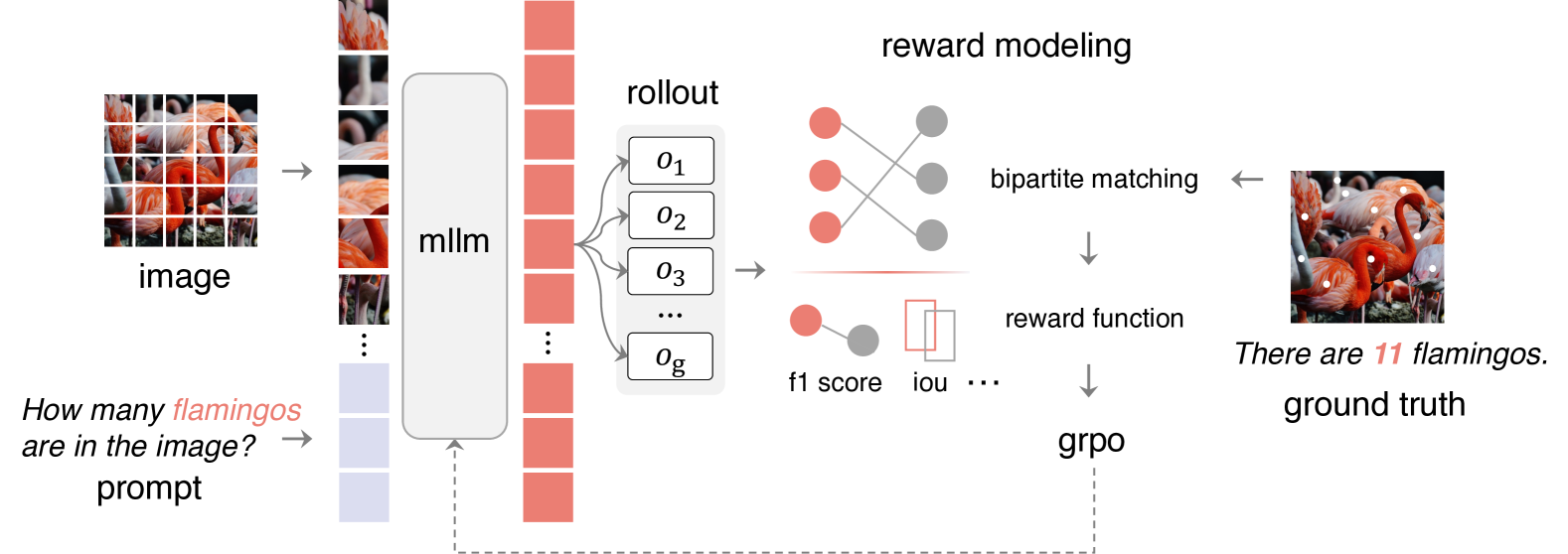
The Perception-R1 framework showing the GRPO training process applied to visual perception.
Evaluation Highlights
- Achieves 31.9% mAP on COCO2017 val, becoming the first pure MLLM to surpass the 30% AP threshold on general object detection
- Outperforms the Qwen2-VL-2B-Instruct baseline by +17.9% on the PixMo-Count benchmark
- Attains 98.1% F1-score on PageOCR, surpassing both the strong generalist LLaVA-NeXT (64.7%) and the expert model GOT (97.2%)
Breakthrough Assessment
8/10
Significant because it successfully applies RL to low-level vision tasks (detection/counting) within a general MLLM, proving CoT is unnecessary for perception and establishing a strong pure-MLLM baseline for COCO.