📝 Paper Summary
GUI Agents
Multimodal Large Language Models (MLLMs)
Reinforcement Fine-Tuning (RFT)
UI-R1 adapts DeepSeek-R1's reinforcement learning paradigm to GUI agents using a novel coordinate-based reward function, achieving strong performance with minimal training data.
Core Problem
Supervised fine-tuning (SFT) for GUI agents requires massive labeled datasets, is computationally expensive, and often fails to generalize to out-of-domain (OOD) interfaces.
Why it matters:
- Existing open-source GUI agents struggle with OOD scenarios (e.g., different operating systems or apps) when trained via SFT
- Previous RL methods for vision focus on Intersection over Union (IoU) for bounding boxes, which is less effective for precise action prediction (clicks/scrolls) needed in GUI control
Concrete Example:
When given a low-level instruction like 'Click the menu icon', SFT agents often predict the wrong coordinates on unfamiliar apps. UI-R1 fixes this by optimizing specifically for the click coordinate distance rather than just visual element overlap.
Key Novelty
Rule-Based RL for GUI Action Prediction (UI-R1)
- Introduces a GUI-specific reward function that evaluates 'Action Type' correctness and 'Coordinate Accuracy' (distance to target) rather than standard visual grounding metrics like IoU
- Demonstrates that a very small, high-quality dataset (136 samples) combined with Group Relative Policy Optimization (GRPO) can rival large-scale SFT models
- Proposes an 'Efficient' variant that trains the model to bypass explicit reasoning steps for simpler grounding tasks, increasing speed
Architecture
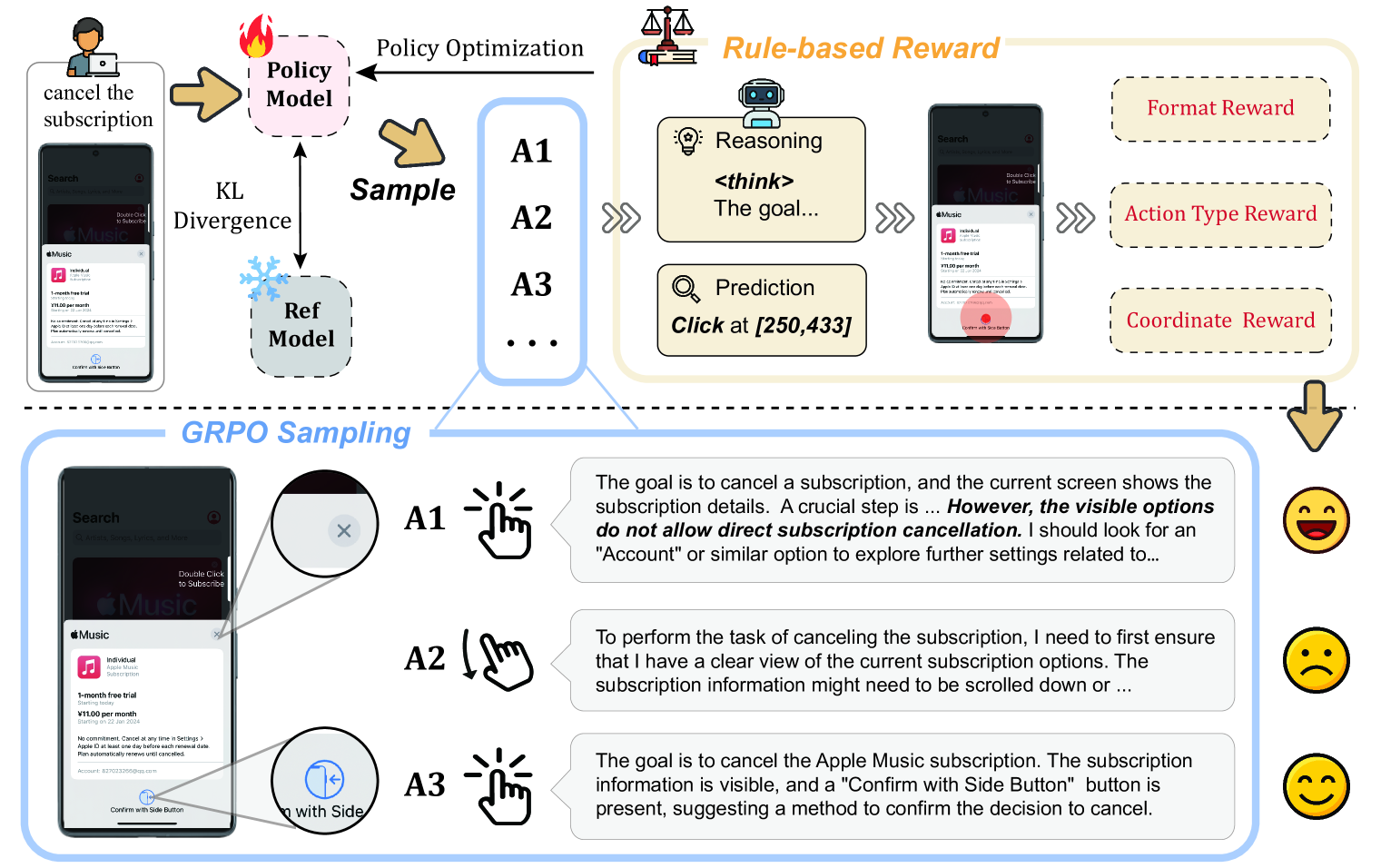
The UI-R1 framework illustrating the RL training pipeline with Group Relative Policy Optimization (GRPO).
Evaluation Highlights
- Achieves average accuracy gains of +22.1% on the ScreenSpot benchmark (in-domain) compared to the Qwen2.5-VL-3B base model
- Improves out-of-domain performance with a +12.7% gain on AndroidControl and +6.0% on ScreenSpot-Pro benchmarks
- Reasoning processes (Chain-of-Thought) improve performance by approximately +6% compared to direct action prediction
- UI-R1-3B delivers performance competitive with OS-Atlas-7B, a larger model trained on 76,000 samples (vs. 136 for UI-R1)
Breakthrough Assessment
8/10
Successfully transfers the 'R1' RL paradigm to multimodal GUI agents. The ability to outperform baselines with only 136 training samples vs 76k is a significant efficiency breakthrough.