📝 Paper Summary
Robotic Manipulation
Vision-Language-Action (VLA) Models
Reinforcement Learning (RL)
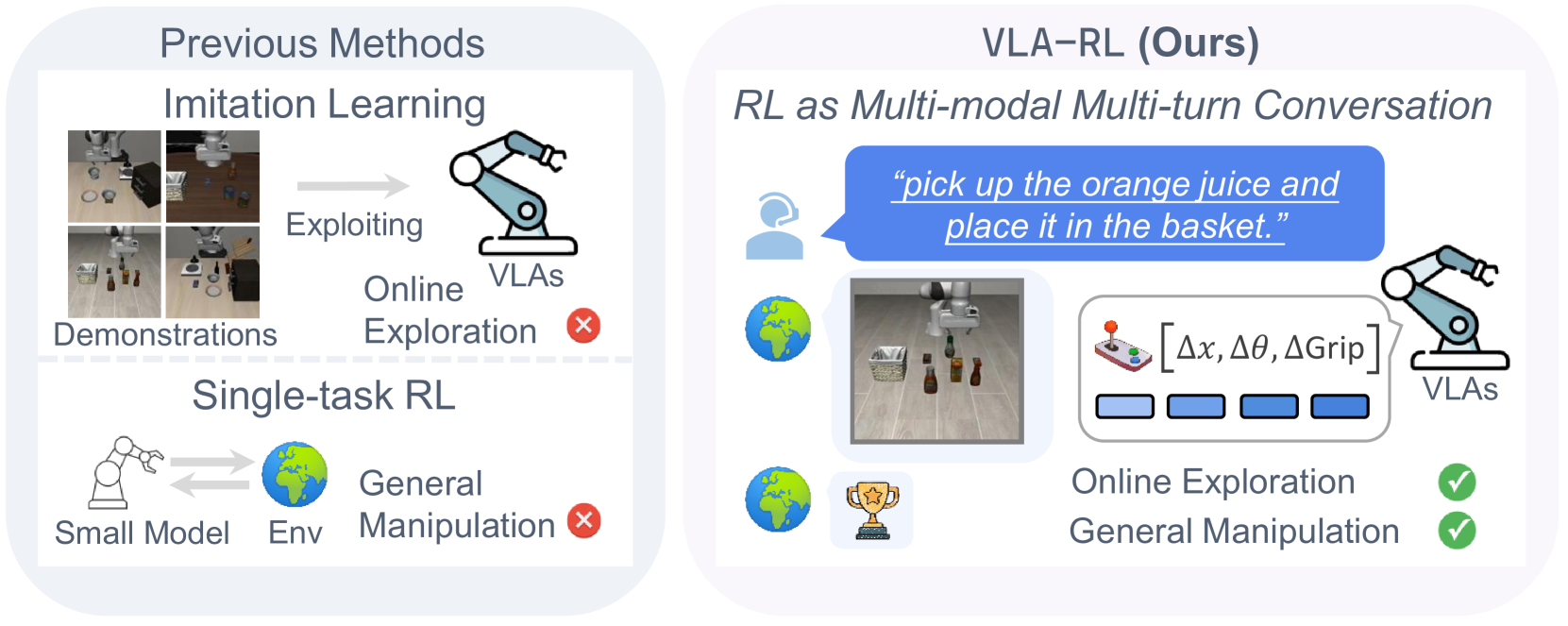
VLA-RL improves generalist robot manipulation by fine-tuning pretrained Vision-Language-Action models using online reinforcement learning guided by a visual process reward model.
Core Problem
Robotic models trained solely on offline imitation learning suffer from distribution shift, failing when they encounter states not covered in the demonstration data (the Out-of-Distribution problem).
Why it matters:
- Pure imitation learning hits a performance ceiling because it cannot correct errors or explore new solutions outside its training data
- Traditional RL from scratch is too data-inefficient for complex, general-purpose robotic tasks
- Existing VLAs like OpenVLA fail execution in novel scenarios due to lack of test-time exploration capabilities
Concrete Example:
In an Out-of-Distribution (OOD) scenario not seen in expert demonstrations, an imitation-trained agent may drift slightly from the optimal path and, lacking knowledge of how to recover, cause execution failure.
Key Novelty
Trajectory-Level RL with Visual Process Rewards
- Formulates robotic manipulation as a multi-turn, multi-modal conversation where the 'response' is a sequence of action tokens, enabling the use of LLM-based RL algorithms like PPO
- Introduces a Robotic Process Reward Model (RPRM) that acts like a visual verifier, predicting the probability of success at each step to provide dense feedback in sparse-reward environments
Architecture
The VLA-RL algorithmic and systematic framework, illustrating the interaction between the Actor, Critic, and Reward Model.
Evaluation Highlights
- Surpasses the strongest fine-tuned baseline by +4.5% success rate across 40 challenging robotic manipulation tasks in the LIBERO benchmark
- Matches the performance of advanced commercial models such as π0-FAST despite using open-source foundations
- Demonstrates evidence of inference scaling laws in robotics, where performance improves with increased test-time computation
Breakthrough Assessment
8/10
Successfully transfers the 'System 2' reasoning/RL paradigm from LLMs to Robotics (VLA), showing that online RL with process rewards can significantly boost pretrained generalist robot policies.