📊 Experiments & Results
Evaluation Setup
Zero-shot evaluation on competitive mathematics and reasoning benchmarks.
Benchmarks:
- AIME 2024 (Challenging Mathematics Problems)
- MATH-500 (Mathematics Problems)
- GPQA Diamond (Graduate-Level General Purpose QA)
Metrics:
- Pass Rate / Accuracy (implied, specific metric not named in snippet)
- Response Length (to measure scaling of reasoning)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| The provided text asserts superior performance and efficiency gains but does not contain the specific results table with numeric accuracy scores. Therefore, specific accuracy entries are omitted to strictly follow the 'No fabricated numbers' rule. The efficiency claim is relative and included below. | ||||
| Training Steps | Relative Steps | 1.0 | 0.1 | -0.9 |
Experiment Figures
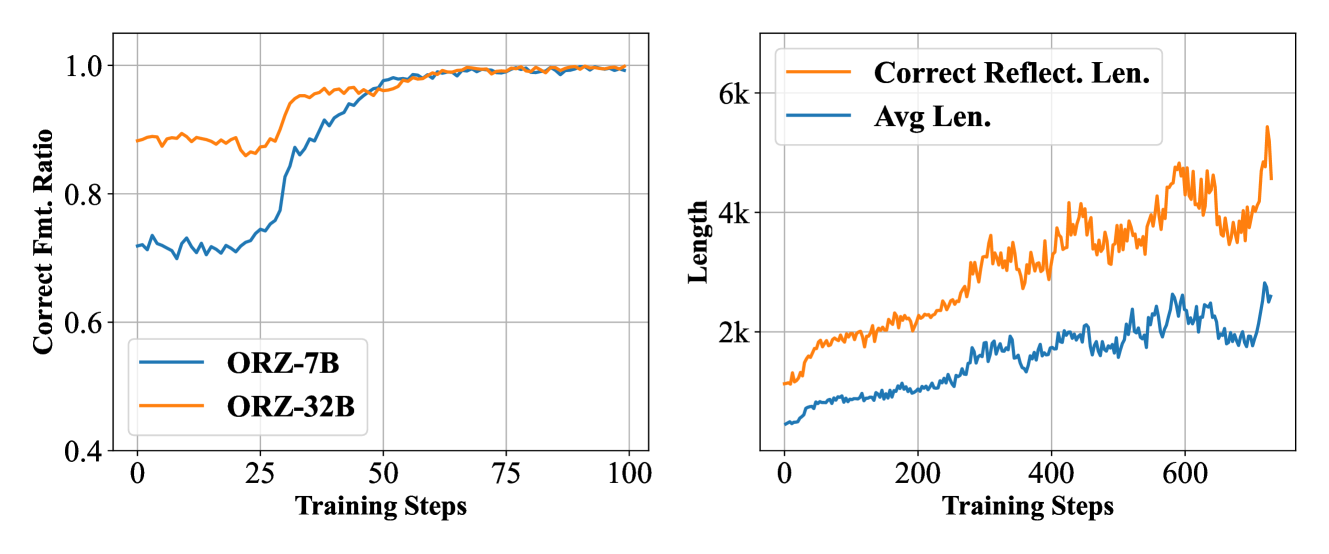
Evolution of response format compliance during training
Main Takeaways
- Vanilla PPO with GAE (gamma=1, lambda=1) is sufficient for scaling reasoning, contradicting the need for complex GRPO or KL regularization.
- The learned critic in PPO is essential for 'credit assignment', effectively identifying and devaluing repetitive loops that cause GRPO to collapse.
- Data scale and diversity are critical; training on limited data (MATH train set) plateaus quickly, while the curated large-scale dataset shows continuous improvement.
- Explicit format rewards are unnecessary; unaligned base models can learn required output formats (e.g., <answer> tags) solely from binary correctness rewards.