📝 Paper Summary
Test-Time Training (TTT)
Reinforcement Learning for Reasoning
Unsupervised Learning
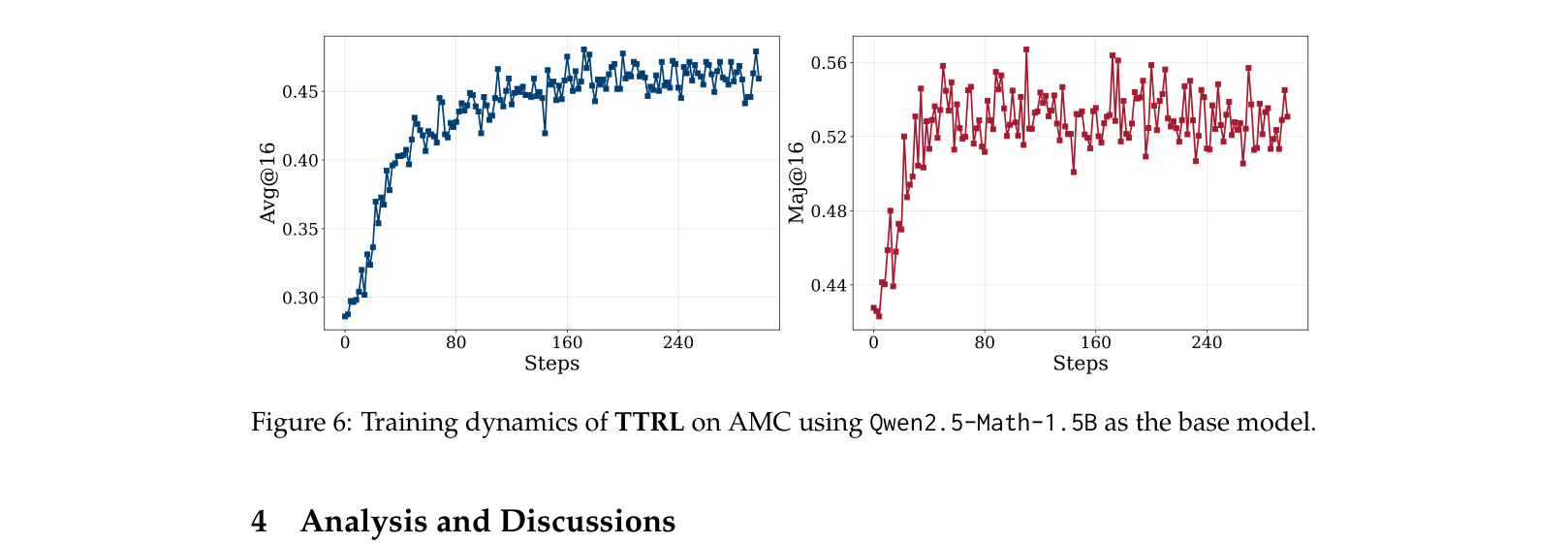
TTRL updates large language models at inference time using reinforcement learning guided by pseudo-labels derived from the majority vote of the model's own sampled outputs.
Core Problem
Enhancing reasoning capabilities usually requires expensive human-labeled data or large-scale compute for test-time scaling, but models struggle to adapt to new, hard unlabeled questions at inference time.
Why it matters:
- Models cannot currently self-evolve or adapt to distribution shifts on difficult benchmarks (e.g., ARC-AGI-2) where ground truth labels are unavailable
- Standard Test-Time Scaling (like majority voting) improves results but does not update the model's parameters, missing the opportunity for cumulative learning during inference
Concrete Example:
On the difficult AIME 2024 math benchmark, Qwen2.5-Math-7B achieves only 12.9% accuracy. Standard methods freeze the model, but TTRL updates the model on the test questions themselves, raising accuracy to 40.2%.
Key Novelty
Test-Time Reinforcement Learning (TTRL)
- Instead of just selecting the majority answer (Test-Time Scaling), TTRL uses the majority consensus as a proxy ground-truth label to calculate rewards and update the model's weights via RL
- Leverages the 'Lucky Hit' phenomenon: even if the majority vote is wrong, the resulting reward signal (punishing disagreement with the vote) is often still correct for other wrong answers, guiding the model effectively
Architecture
The Test-Time Reinforcement Learning (TTRL) pipeline compared to standard LLM Querying and Test-Time Scaling.
Evaluation Highlights
- +211% relative improvement (12.9% → 40.2%) on AIME 2024 using Qwen-2.5-Math-7B compared to the base model
- +40.3% absolute improvement (32.7% → 73.0%) on MATH-500 using Qwen2.5-Math-1.5B
- Surpasses the Maj@64 baseline of the initial model, effectively exceeding the quality of its own supervision signal
Breakthrough Assessment
9/10
Demonstrates massive gains (+27% absolute on AIME) without any labeled data, challenging the assumption that ground truth is needed for effective RL fine-tuning. Approaches 'oracle' performance.