📝 Paper Summary
Zero Reinforcement Learning (Zero RL)
Post-training of Large Language Models
Reasoning Emergence in LLMs
SimpleRL-Zoo demonstrates that applying reinforcement learning directly to diverse open base models triggers emergent reasoning and significant performance gains without supervised fine-tuning, provided format rewards and data difficulty are carefully managed.
Core Problem
Prior work on zero RL training (training RL directly on base models) primarily focused on the Qwen2.5 series, which already possesses strong instruction-following and reasoning capabilities, leaving it unclear if these benefits extend to weaker or more diverse base models.
Why it matters:
- It is unknown whether the 'aha moment' (emergent self-verification) is a general phenomenon or specific to high-capability base models like DeepSeek-V3 or Qwen2.5
- Current recipes often rely on rigid format rewards (e.g., answer boxing) or SFT warm-starts, which may actually hinder exploration and reasoning development in weaker models
- Understanding the minimal ingredients for reasoning emergence is crucial for democratizing advanced AI capabilities beyond top-tier proprietary labs
Concrete Example:
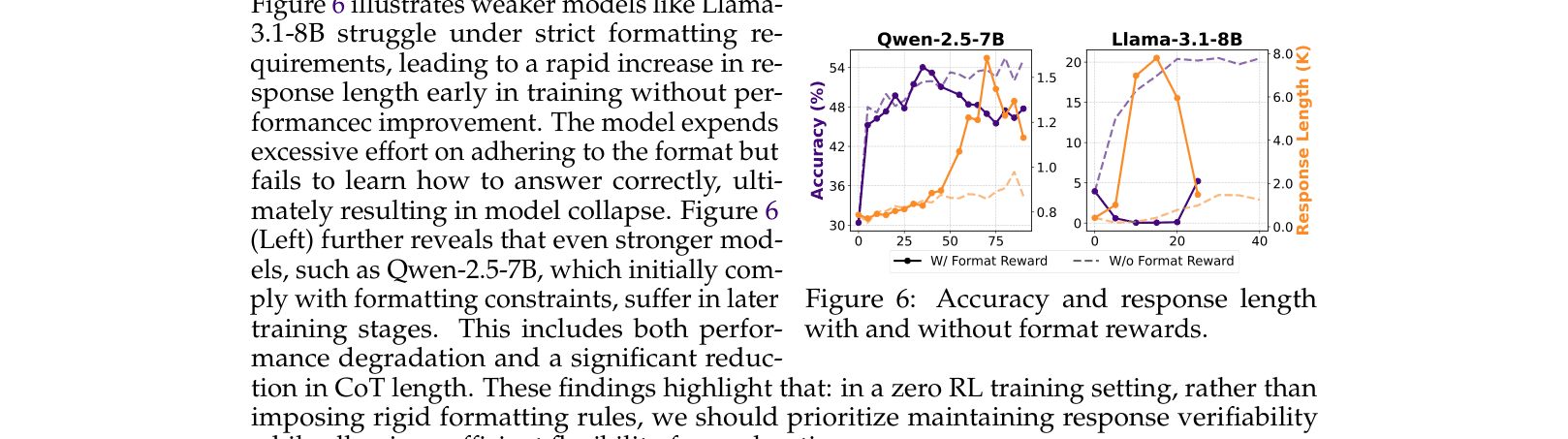
When Mistral-7B is trained with a rigid format reward (must use \boxed{}), it collapses early, generating repetitive gibberish to satisfy the format without solving the problem. In contrast, removing this constraint allows it to explore and improve.
Key Novelty
SimpleRL-Zoo (Evaluation & Recipe)
- Systematic evaluation of 'Zero RL' (RL without SFT) across 10 diverse base models (Llama-3, Mistral, DeepSeek-Math, Qwen2.5), verifying that reasoning emergence is a general phenomenon
- Identification of 'format reward' and 'data difficulty' as critical failure points: strict formatting kills exploration in weak models, while overly hard data causes collapse
- Discovery that traditional SFT warm-starts (using short CoT data) actually suppress the emergence of advanced reasoning behaviors like backtracking compared to pure Zero RL
Architecture
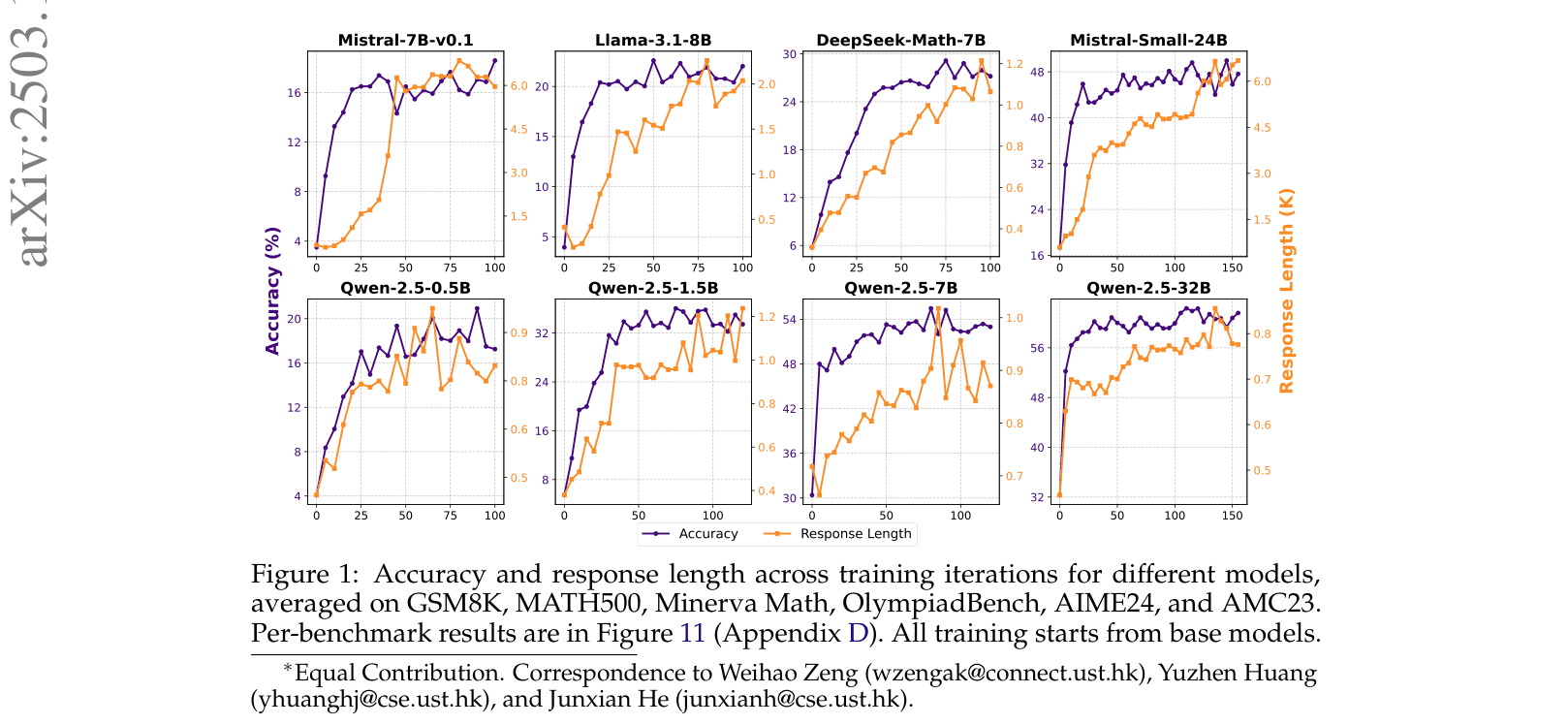
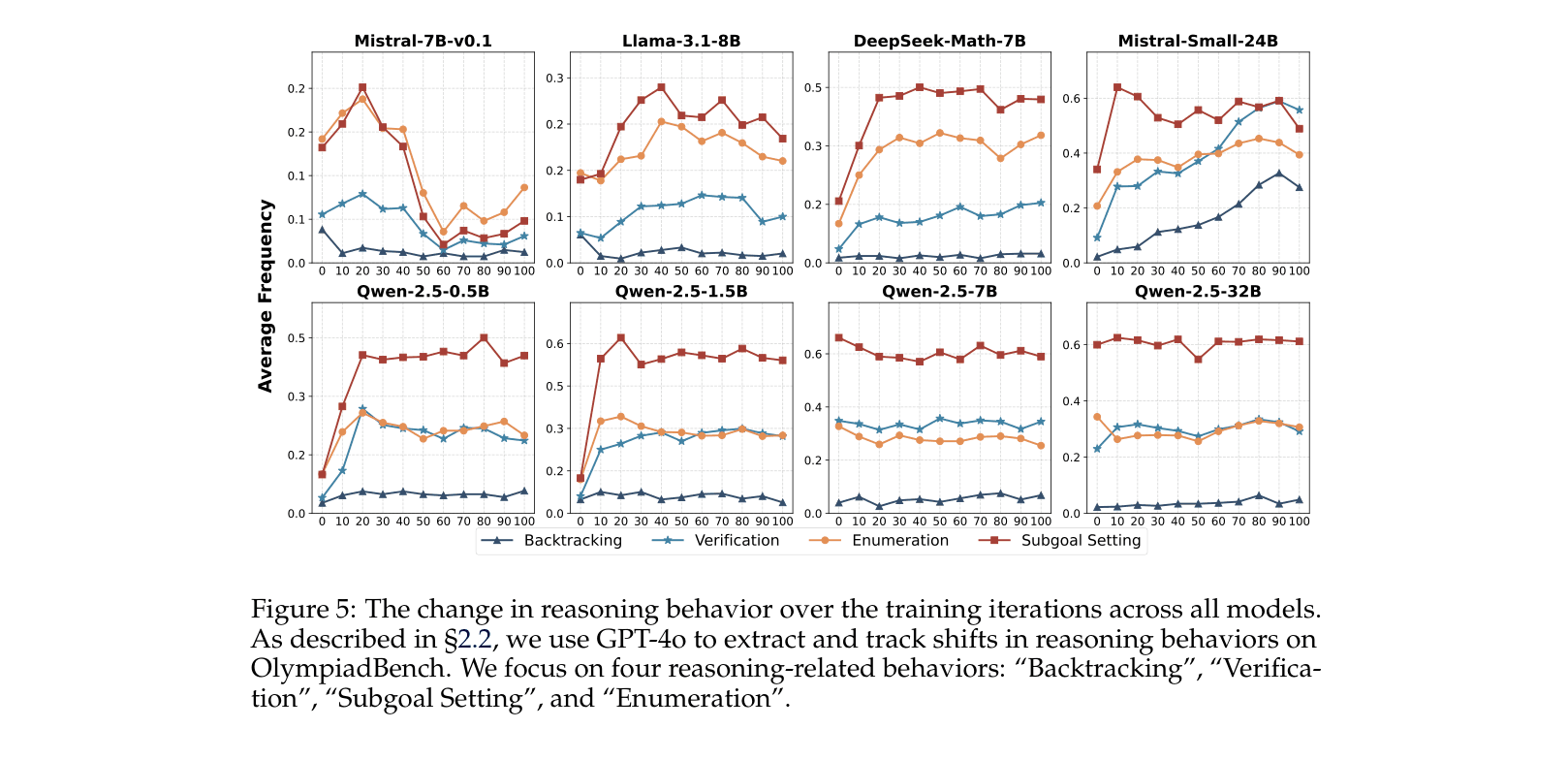
Evolution of accuracy and response length across training iterations for 8 different base models.
Evaluation Highlights
- Mistral-Small-24B improves accuracy from 27.6% to 49.6% (average across 6 math benchmarks) via Zero RL, surpassing its base model significantly
- DeepSeek-Math-7B improves from 11.3% to 29.2% average accuracy, tripling its performance without any supervised fine-tuning
- Zero RL models generalize to unseen tasks: Mistral-Small-24B gains +16.0 points on MMLU (Stem) and +24.8 points on GPQA, despite training only on 8K math problems
Breakthrough Assessment
9/10
Provides the first comprehensive empirical evidence that the 'DeepSeek-R1 effect' (emergent reasoning via pure RL) replicates across diverse open models, debunking the need for SFT warm-starts and establishing a robust recipe for the community.