📝 Paper Summary
Reinforcement Learning for LLMs
Reasoning
Kimi k1.5 scales reinforcement learning by utilizing long context windows up to 128k tokens, employing partial rollouts for efficiency, and simplifying policy optimization to achieve state-of-the-art reasoning without complex search trees or value functions.
Core Problem
Standard pretraining is limited by the availability of high-quality static data, and prior RL attempts with LLMs often failed to produce competitive results or relied on overly complex engineering like Monte Carlo Tree Search.
Why it matters:
- Scaling compute via next-token prediction is hitting data bottlenecks, requiring a new axis for continued intelligence improvement.
- Existing reasoning models often rely on expensive search algorithms (MCTS) or complex value functions that are hard to scale and deploy.
- Effective long-chain reasoning is critical for solving advanced math, coding, and multimodal problems where simple prompting fails.
Concrete Example:
In complex math problems, a model might guess a correct answer through incorrect reasoning (false positive). Kimi k1.5 avoids this by enforcing long Chain-of-Thought verification and penalizing short, lucky guesses, unlike standard RL which might exploit such rewards.
Key Novelty
Long-Context RL with Partial Rollouts
- Treats the reasoning process as a single very long sequence (up to 128k context) rather than a tree, allowing the model to learn planning, reflection, and error correction implicitly within the context.
- Uses 'partial rollouts' to reuse previous trajectory segments during training, enabling efficient training on extremely long reasoning paths without re-generating from scratch every step.
- Simplifies RL by removing value networks and Monte Carlo Tree Search, relying instead on a robust variant of online mirror descent with length penalties.
Architecture
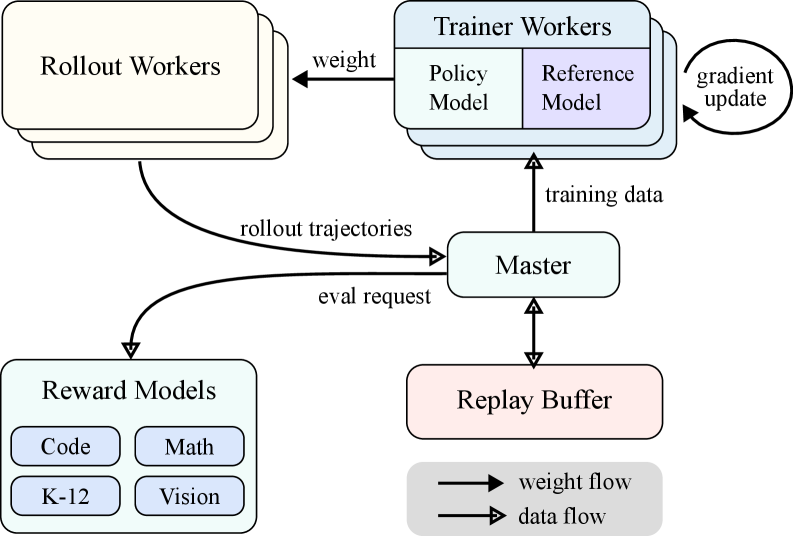
The RL training system architecture and the Partial Rollout mechanism.
Evaluation Highlights
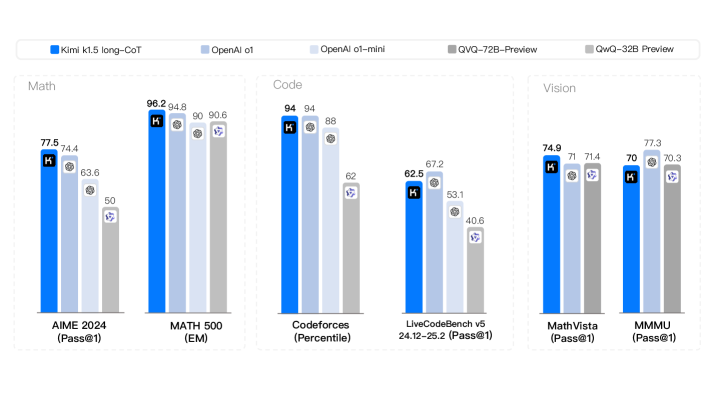
- Matches OpenAI o1 on reasoning benchmarks: 77.5 on AIME, 96.2 on MATH 500, and 94th percentile on Codeforces.
- Achieves 74.9 on MathVista, demonstrating strong multimodal reasoning capabilities.
- Short-CoT distilled model outperforms GPT-4o and Claude Sonnet 3.5 significantly (e.g., +550% relative improvement on some short-CoT metrics like AIME 60.8 vs lower baselines).
Breakthrough Assessment
9/10
Demonstrates that simple RL techniques scaled to massive contexts can match complex proprietary systems like o1, effectively demystifying 'reasoning' models and offering a reproducible recipe for scaling test-time compute.